Demo von Open-? Strawberry? Projekt: https://huggingface.co/spaces/pseudotensor/open-strawberry
Ein Nachweis des Konstrukts von Argumentationsspuren, um eine Open-Source-Version von OpenAI O1 zu erstellen, die vom Erdbeeralgorithmus von Openai inspiriert ist.
Wenn Sie das Projekt unterstützen möchten, wenden Sie sich ★ in (Top-Right-Ecke) und teilen Sie es mit Ihren Freunden.
Beiträge sehr willkommen!
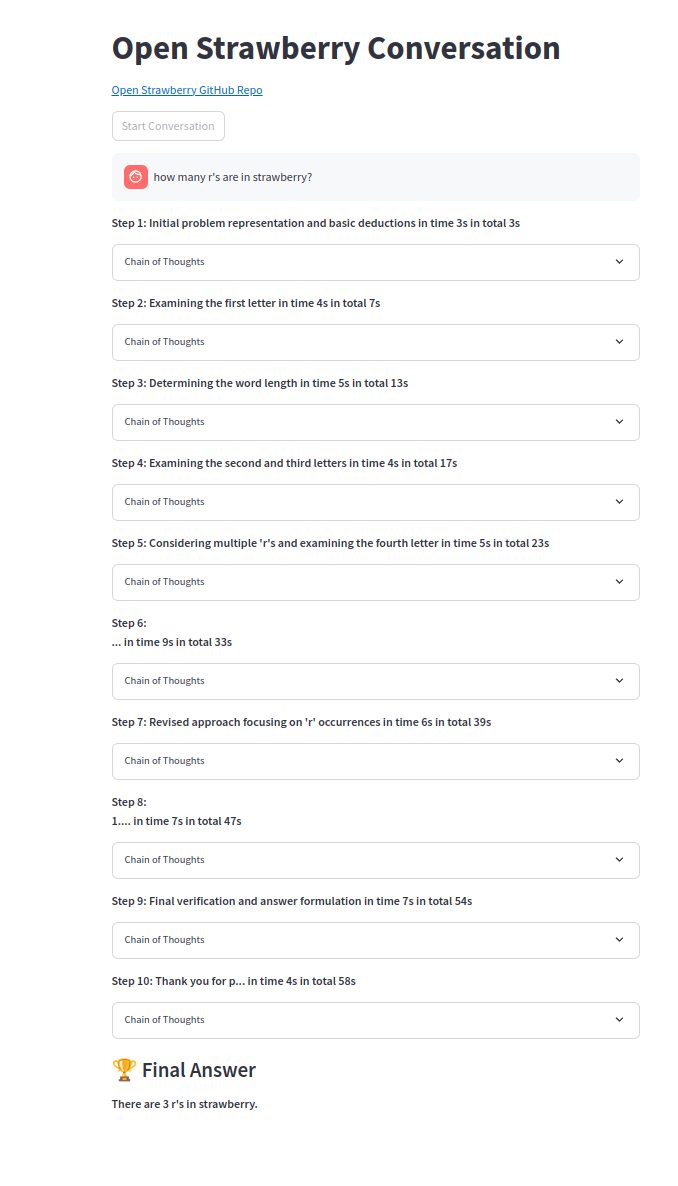
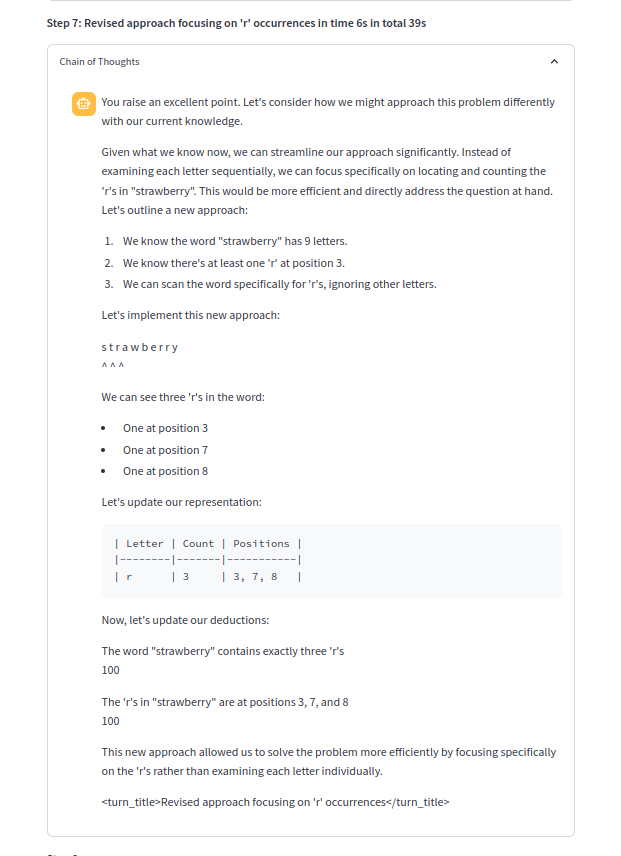
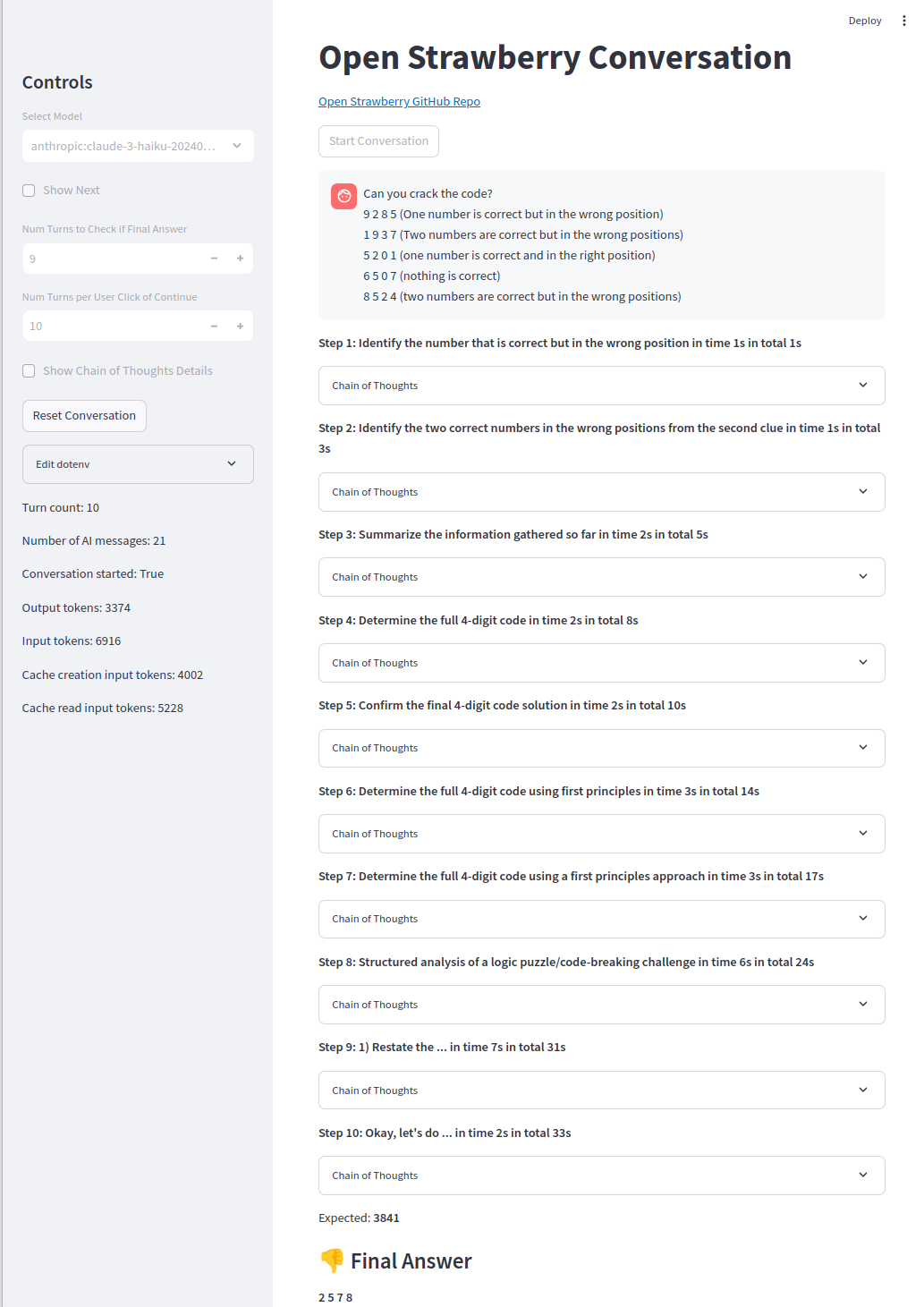
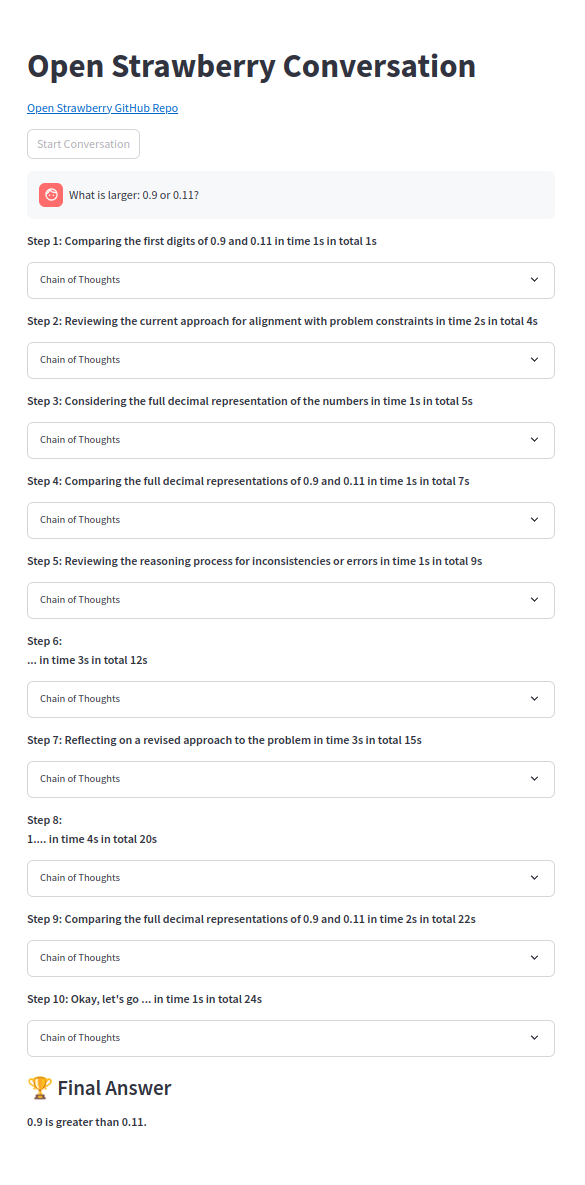
Eine der Gedankenketten:
Installation
Python> = 3.10 sollte in Ordnung sein, dann:
pip install -r requirements.txt
Verwendung
Füllen .env
# OpenAI# Can be OpenAI key or vLLM or other OpenAI proxies:OPENAI_API_KEY=# only require below for vLLM or other OpenAI proxies:OPENAI_BASE_URL=# only require below for vLLM or other OpenAI proxies:OPENAI_MODEL_NAME=# ollamaOLLAMA_OPENAI_API_KEY=OLLAMA_OPENAI_BASE_URL=# quoted list of strings or stringOLLAMA_OPENAI_MODEL_NAME=# AzureAZURE_OPENAI_API_KEY=OPENAI_API_VERSION=AZURE_OPENAI_ENDPOINT=AZURE_OPENAI_DEPLOYMENT=# not requiredAZURE_OPENAI_MODEL_NAME=# Anthropic prompt caching very efficientANTHROPIC_API_KEY=GEMINI_API_KEY=# groq fast and long contextGROQ_API_KEY=# cerebras only 8k contextCEREBRAS_OPENAI_API_KEY=# WIP: not yet usedMISTRAL_API_KEY=HUGGING_FACE_HUB_TOKEN=REPLICATE_API_TOKEN=TOGETHERAI_API_TOKEN=
Ollama
Für Ollama kann man den OpenAI -Service nutzen:
# Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve &> ollama.log &
ollama run mistral:v0.3
Dann wählen Sie Set .env mit OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ und z. OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3 oder Liste von Ollama -Modellen: OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"]
Das Projekt befindet sich in den ersten Phasen, um die Erzeugung von Argumentationsspuren für bestimmte Probleme als Beweis für das Konzept zu untersuchen.
Beachten Sie, dass die Demo-Eingabeaufforderung einfache Modelle sind und sogar Sonnet3.5 und GPT-4O auch mit Standard-COT eine Lösung finden können. Manchmal können manchmal nur O1-Mini oder O1-Präview erhalten, obwohl Code-Agenten und einfach es lösen.
Hintergrund
Open-Strawberry basiert auf Spekulationen über OpenAIs Strawberry, einen raffinierten Algorithmus für die Suchgeneration zur Generierung und Überprüfung von Trainingsdaten.
Dieses Projekt zielt darauf ab, ein ähnliches System mit Open-Source-Tools und -Methoden nachzubilden.
Spekulative Definitionen
Q *: Ein hypothetischer primordialer Suchgeneration Deep RL-Algorithmus, der von OpenAI entwickelt wurde, um Trainingsdaten zu generieren.
Strawberry : Ein fortgeschrittener Deep-RL-Algorithmus der Suchgeneration von OpenAI zur Generierung und Überprüfung von Schulungsdaten.
O1 : GPT-4O und GPT-4O-Mini-basiert, aber feiner auf Erdbeerdaten, einschließlich O1-Mini, O1-Präview, O1 und O1-ioi. [1]
ORION : GPT-5-basiertes Modell, das die synthetischen Daten von Strawberry enthält und 0-Shot-und Long-Argumentations-Abfragen besser verwaltet.
Erzeugen von Argumentationsspuren
Bootstrapping ist durch progressives Lernen der Schlüssel.
Bootstrap aus vorhandener beaufsichtigter, fein abgestimmter, unterrichtungsstimmiger, bevorzugter Modelle mithilfe von Chat-Multiturn-Chat-Historien.
Implementieren Sie ein promptes System, das die LLM dazu führt, inkrementelle Schritte in Richtung einer Lösung zu unternehmen.
Randomisierte nützliche COT -Eingabeaufforderungen vom Benutzer (z. B. nicht nur als nächstes, sondern "Sind Sie sicher?" "Irgendwelche Fehler?"
Betonen Sie das LLM, um den winzigsten Schritt in Richtung der Lösung zu machen, z. B. wird sogar ein einzelner Ausdruck oder ein einzelner Satz bevorzugt. Erst wenn die endgültige Antwort produziert wird, sollte eine erweiterte vollständige Antwort gegeben werden.
Generieren Sie Multi-Turn-Chat-Argumentationsspuren
Fragen Sie manchmal, ob das Modell über eine Antwort zuversichtlich ist. Wenn ja, bitten Sie es, diese Antwort in <Dend_answer> XML -Tags zu platzieren. Wenn dies getan wird, beenden Sie die Argumentationsspurenerzeugung.
Verwenden Sie ein Verifizierungssystem, um auf Fehler im Chat -Verlauf zu suchen.
Generieren Sie mehrere Argumentationsspuren pro Problem.
Wenden Sie diesen Prozess auf eine Menge von Problemen mit überprüfbaren Grundwahrheiten an.
Identifizieren Sie Probleme, das das vorhandene Anweisungsmodell für eine gewisse Anzahl von festen Wiederholungen (z. B. 20) kaum mit starkem COT und hoher Temperatur ausführen kann.
Feinabstimmung auf Argumentationsspuren
Wählen Sie für jedes Problem korrekte und falsche Argumentationsspuren basierend auf der Grundwahrheit.
Fein ein Modell unter Verwendung der ausgewählten Argumentationsspuren unter Verwendung von DPO oder NLHF, wobei die Präferenz für korrekte Spuren positiv ist, negativ für falsche Spuren.
Verzießen Sie das Präferenzgewicht nach Anzahl der unternommenen Schritte, dh wenn falsch, sollten längere negative Spuren eine größere negative Belohnung erhalten. Richtige Spuren, die kürzer sind, sollten eine positivere Belohnung erhalten.
Fein des Modells auf diesen Argumentationsspuren mit Mischung anderer Daten wie gewohnt.
Verwenden Sie dieses Modell, um Argumentationsspuren für etwas härtere Probleme zu generieren, die dieses neue Modell kaum tun kann.
Wiederholen Sie die Erzeugung von Argumentationsspuren und Feinabstimmungen, bis das Modell die schwierigsten Probleme haben kann, so dass der Umfang der Argumentationsspuren als mehr Arten von Problemen konsumiert (jedoch nicht alle Arten, da nicht immer erforderlich ist).
Spekulationen
MCTs, TOT, Agenten usw. Nicht zum Training oder zur Inferenzzeit erforderlich.
Eine menschliche Kennzeichnung oder menschliche Überprüfung von Argumentationsspuren ist nicht erforderlich.
Es sind keine fein abgestimmten Modelle zur Überprüfung erforderlich, welcher Schritt auch immer.
RLHF ist nicht streng erforderlich, sondern nur DPO.
OpenAI verwendet Deep RL zum Training der Argumentationsspuren, aber ich denke nicht, dass dies erforderlich ist. Selbstspiel ist mächtig, kann aber von DPO nachgeahmt werden.
Deep RL ist nur eine Möglichkeit, Daten auf effiziente Weise zu generieren, ist jedoch nicht erforderlich und übernommen von OpenAs früheren Arbeiten daran.
Begründung
[P10] ist ein aktuelles Papier, das unseren Vorschlag zur Verwendung selbst erzeugter Multi-Turn-Daten validiert, um das Modell leicht nach und nach in die Selbstkorrektur zu bringen.
Projektziele
Erzeugen Sie mit dem vorgeschlagenen Ansatz Argumentationsspuren.
Fein ein Modell auf den generierten Argumentationsspuren.
Bewerten Sie die Leistung und vergleichen Sie sie mit vorhandenen Modellen mit null Schotten, weniger Schuss, COT usw.
Andere Projekte:
Der zentrale Unterschied zu Raspberry besteht darin, dass sie sich auf harte Eingabeaufforderungen konzentrieren, während wir der Meinung sind, dass ein fortschreitender Lernansatz mit wiederholter Feinabstimmung in Richtung O1 startet.
Der zentrale Unterschied zu G1 besteht darin, dass sie sich allein auf O1-ähnliches Verhalten konzentrieren, ohne sich zu betonen, wie sie sich in Richtung O1 befassen können.
Anthropische und Google -API -Unterstützung von schnellem Caching bedeutet viel billiger zu betreiben. VllM unterstützt das Präfix -Caching, das dies ebenfalls hilft.
Aktueller Status
Dieses Projekt befindet sich in den ersten Phasen. Ergebnisse und Vergleiche werden hinzugefügt, sobald sie verfügbar sind.
Todo:
Richten
Richten Sie die grundlegende Streamlit -App ein, um die Ausgaben einfach zu überwachen
Suchen Sie nach Unterstützung der Community
Jede (sagen wir) 9 Schritte, fragen Sie, ob das Modell der Meinung ist, dass es eine endgültige Antwort hat, und wenn ja, bitten Sie es, diese Antwort in <Final_answer> XML -Tags für die Extraktion und Beendigung der Argumentationsspur zu platzieren.
Backoff hinzufügen
Fügen Sie Ollama, Google, Azure, OpenAI, GROQ, Anthropic -APIs mit schnellem Zwischenspeichern für Anthrope hinzu
Fügen Sie hochrangige Zusammenfassung der Textblöcke wie O1 hinzu
Verbessern
Fügen Sie das Fenster des Verlaufs des Verifizierers hinzu und kritisieren den Assistentenausgang getrennt kritisch
Verwenden Sie vorhandene Datensätze mit Bodenwahrheit, um Probleme zu identifizieren, für die COT nach einigen Versuchen Erfolg erzielt
Ernte cot-freundliche Aufforderungen und sammeln positive und negative Argumentationsspuren
Fein ab DPO einschließlich der Mischung aus normalen Daten mit einer ähnlichen Verteilung
Wiederholen Sie in der nächsten Runde von cot-freundlichen Eingabeaufforderungen ohne Originalanpassungen. So können Sie auch Bootstraps erhalten
Feinabstimmung oben auf der Feinabstimmung, einschließlich der Mischung aus normalen Daten und einer ähnlichen Verteilung
Wiederholen
Schwierigere Probleme sind immer noch unerreichbar, was O1-Vorsicht nur in etwa 50% der Fälle erhält (Code-Agenten erhalten 90% der Fälle):
Einfache Probleme werden zuverlässig gelöst:
Beitragen
Wir begrüßen Beiträge der Community. Weitere Richtlinien zur Teilnahme finden Sie in unserer Datei mit Beitrags.md -Datei.
Probleme:
Fahren Sie die Taste in App weiter, die grau ausgestrahlten alten Chats hinterlassen, am besten, wenn Sie sauber gestartet werden
Das Zählen von Token zeigt sich erst nach dem Treffer weiter, am besten, wenn jede Runde war
Über den Autor
Jonathan McKinney ist Forschungsdirektor bei H2O.ai mit einem Hintergrund in Astrophysik und maschinellem Lernen. Seine Erfahrung umfasst:
Ehemaliger Astrophysik -Professor bei UMD [B1] [B2] [B3] [B4]
7 Jahre Erfahrung mit Automl -Produkten bei H2O.AI [B5] [B6]
Jüngste Arbeiten zu Feinabstimmungs-LLMs, RAG und AI-Agenten (H2OGPT) [B7] [B8]
Sehen Sie meine anderen Projekte wie H2OGPT und prompt-Engineering an
Haftungsausschluss
Dieses Projekt ist spekulativ und basiert auf öffentlich verfügbaren Informationen über die Arbeit von OpenAI. Es ist nicht mit OpenAI verbunden oder von OpenAI unterstützt.
[P0] Ketten-of-Gedanken-Aufforderung Erläuterung in großen Sprachmodellen: https://arxiv.org/abs/2201.11903
[P1] Star: Bootstrapping -Argumentation mit Argumentation: https://arxiv.org/abs/2203.14465
[P2] Überprüfen wir Schritt für Schritt: https://arxiv.org/abs/2305.20050
[P3] Quiet-Star: Sprachmodelle können sich vor dem Sprechen beibringen: https://arxiv.org/abs/2403.09629
[P4] Denken Sie an, bevor Sie sprechen: Trainingssprachmodelle mit Pause -Token: https://arxiv.org/abs/2310.02226
[P5] Nash -Lernen aus menschlichem Feedback: https://arxiv.org/abs/2312.00886
[P6] Skaling LLM Test-Time Compute kann optimaler effektiver sein als Skalierungsmodellparameter https://arxiv.org/abs/2408.03314
[P7] Verbesserung der LLM -Problemlösung mit Reap: Reflexion, explizite Problemdekonstruktion und Fortgeschrittene, um https://arxiv.org/abs/2409.09415 zu fordern
[P8] Agent Q: Erweiterte Argumentation und Lernen für autonome AI -Agenten https://arxiv.org/abs//2408.07199
[P9] Skalierungsgesetze mit Brettspielen https://arxiv.org/abs/2104.03113
[P10] Trainingssprachmodelle, die sich durch Verstärkungslernen https://arxiv.org/abs/2409.12917 selbst korrigieren, um sich selbst zu korrigieren .12917
Verwandte Projekte:
[OpenO1-Team] Open-Source O1
[Gair-NLP] O1 Replikationsreise: Ein strategischer Fortschrittsbericht
[Maitrix.org] LLM -Vernunft
[Bklieger-Groq] G1: Verwenden von LLAMA-3.1 70B auf COQ, um O1-ähnliche Argumentationsketten zu erstellen
[O1-Kette des Gedanken] Transkription von O1-Argumentationsspuren aus dem OpenAI-Blog-Beitrag
[Toyberry] Toyberry: Ein End -to -End -Tiny -Implementierung des O1 -Argumentationssystems von OpenAI unter Verwendung von MCTs und LLM als Backend
Aber IMHO, das LLM sieht nur ein anderes Token als <thinking> und jetzt ist es <reasoning> .
Ressource:
[Awsome-Llm-Strawberry] Awsome-Llm-Strawberry
Verwandte Videos:
https://www.youtube.com/watch?v=tpun1uokecc (Kaskadierungsanforderungen mit wiederholtem COT)
https://youtu.be/ey9ihse82hc?t=2742 (Noam Brown auf Selbstspiel mit LLMs)
https://youtu.be/nvaxucibb-c?list=pldrirstud7wwjxhoi9vvxeo9ktUfBxLHF (Warum Vlad Tenev und Tudor Achim of Harmonic Think KI im Begriff, die Mathematik zu ändern-und warum es wichtig ist)
https://youtu.be/jplusxjpdra?si=yspkfx57T7EYEL5O (OpenAIs Noam Brown, Ilge Akkaya und Hunter Lightman auf O1 und unterrichten LLMs, um besser zu argumentieren)