Проверка концепции в конструкции следов рассуждений для создания версии Openai O1 с открытым исходным кодом, вдохновленным клубничным алгоритмом Openai.
Если вы хотите поддержать проект, переверните ★ в (в правом углу) и поделитесь им со своими друзьями.
Вклад очень приветствуюсь!
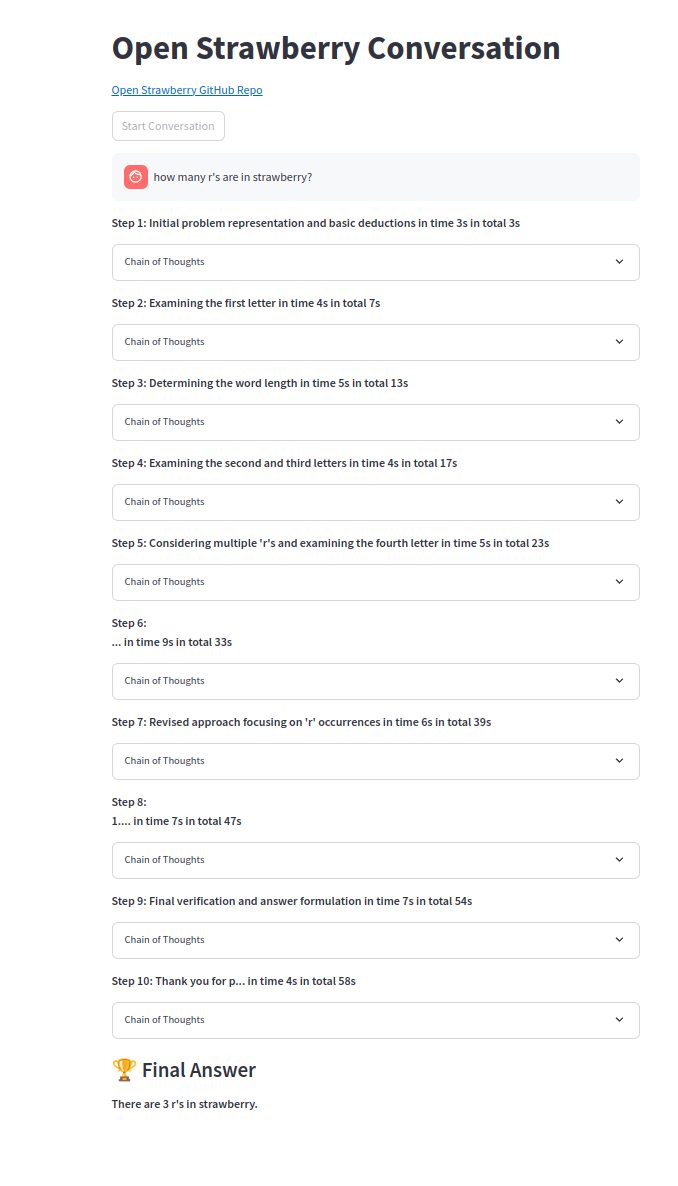
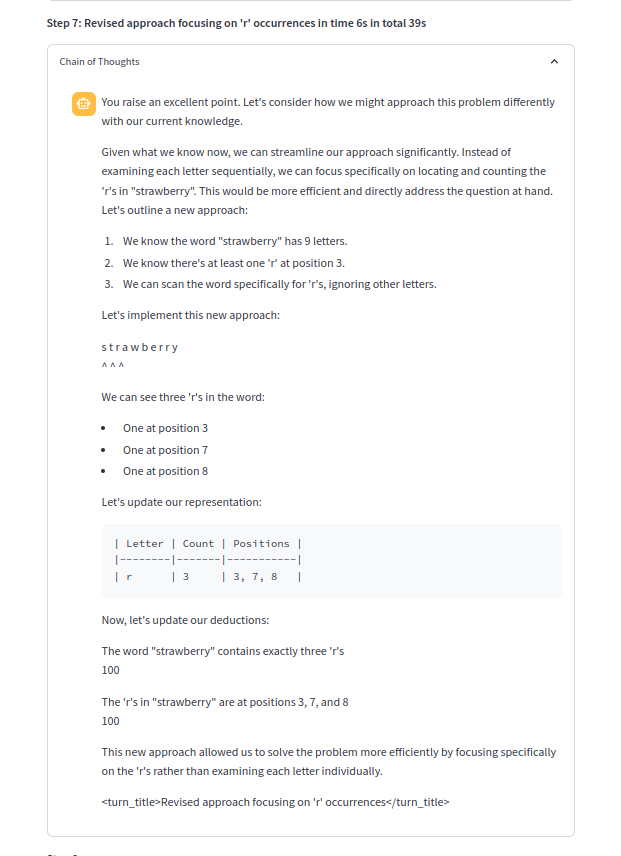
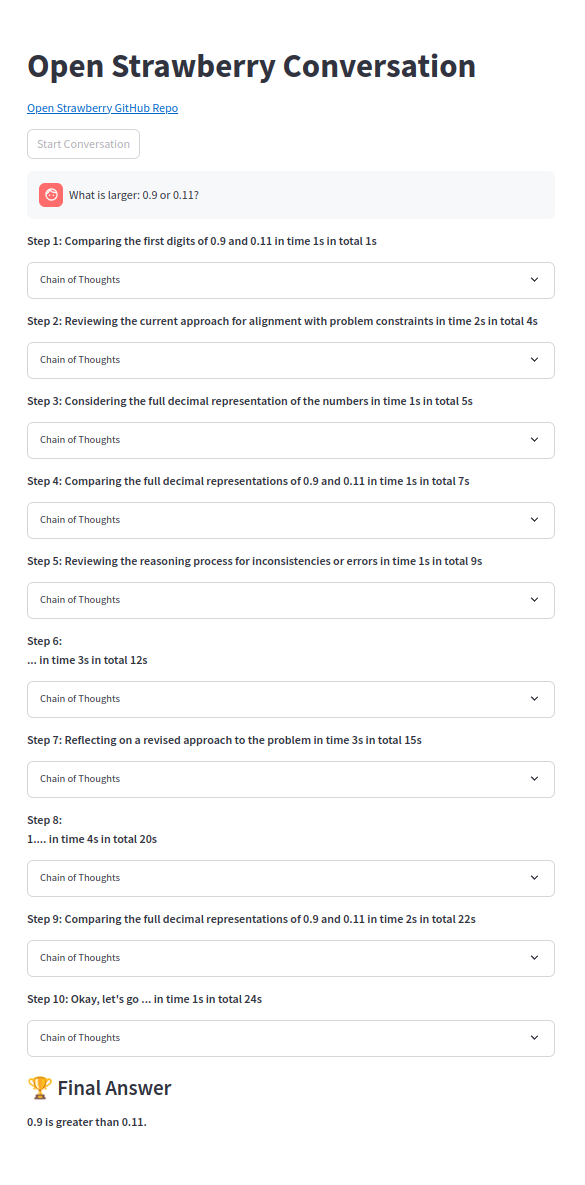
Одна из цепочек мышления:
Установка
Python> = 3.10 должен быть в порядке, тогда:
pip install -r requirements.txt
Использование
Заполните .env с необходимыми клавишами API и т. Д. или Установите Envs, например:
# OpenAI# Can be OpenAI key or vLLM or other OpenAI proxies:OPENAI_API_KEY=# only require below for vLLM or other OpenAI proxies:OPENAI_BASE_URL=# only require below for vLLM or other OpenAI proxies:OPENAI_MODEL_NAME=# ollamaOLLAMA_OPENAI_API_KEY=OLLAMA_OPENAI_BASE_URL=# quoted list of strings or stringOLLAMA_OPENAI_MODEL_NAME=# AzureAZURE_OPENAI_API_KEY=OPENAI_API_VERSION=AZURE_OPENAI_ENDPOINT=AZURE_OPENAI_DEPLOYMENT=# not requiredAZURE_OPENAI_MODEL_NAME=# Anthropic prompt caching very efficientANTHROPIC_API_KEY=GEMINI_API_KEY=# groq fast and long contextGROQ_API_KEY=# cerebras only 8k contextCEREBRAS_OPENAI_API_KEY=# WIP: not yet usedMISTRAL_API_KEY=HUGGING_FACE_HUB_TOKEN=REPLICATE_API_TOKEN=TOGETHERAI_API_TOKEN=
Оллама
Для Олламы можно использовать услугу OpenAI:
# Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve &> ollama.log &
ollama run mistral:v0.3
Затем выберите SET .env с OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ and eg OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3 или список моделей Ollama: OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"]
Проект находится на его начальных этапах, чтобы изучить генерацию следов рассуждений для конкретных проблем в качестве доказательства концепции.
Обратите внимание, что демонстрационная подсказка-это простые модели, и даже Sonnet3.5 и GPT-4O не могут найти решение даже со стандартной кроваткой. Иногда могут быть получены только O1-Mini или O1-Preview, хотя и легко решают кодовые агенты и легко его решают.
Фон
Open-Brawberry основан на предположениях о клубнике Openai, утонченном алгоритме генерации поиска для создания и проверки учебных данных.
Этот проект направлен на воссоздание аналогичной системы с использованием инструментов и методологий с открытым исходным кодом.
Спекулятивные определения
Q *: Гипотетический изначальный алгоритм Генерации поиска, разработанный OpenAI для создания учебных данных.
Клубника : Advanced Generation Generation Gene RL-алгоритм от OpenaI для создания и проверки данных обучения.
O1 : GPT-4O и GPT-4O-Mini, но точно настроенные на данные о клубнике, включая O1-Mini, O1-Preview, O1 и O1-IOI. [1]
ORION : модель на основе GPT-5, которая включает в себя синтетические данные Strawberry и лучше управляет запросами на 0-ступенчатую и длинных рассуждений.
Генерирующие следы рассуждений
Начальная загрузка является ключом через прогрессивное обучение.
Bootstrap, начиная с существующих контролируемых тонких настроек, настроенных на инструкции, настроенными моделями с использованием многократного чата.
Реализуйте систему быстрого приглашения, которая направляет LLM, чтобы предпринять постепенные шаги к решению.
Рандомизированные полезные подсказки от пользователя (например, не только дальше, но «вы уверены?» «Есть ошибки?» «Как бы вы проверили свой ответ?»).)
Подчеркните LLM, чтобы сделать самый незначительный шаг к решению, например, даже одна фраза или предложение. Только после того, как будет получен окончательный ответ, если будет предоставлен расширенный полный ответ.
Генерировать следы рассуждения в чате
Иногда спросите, уверена ли модель в ответе. Если это так, то попросите его поместить этот ответ в теги <inal_answer> XML. Если сделано, то прекратите генерацию следов рассуждений.
Используйте систему проверки для проверки ошибок в истории чата.
Создайте несколько следов рассуждений на проблему.
Примените этот процесс к большому набору проблем с проверяемыми наземными истинами.
Определите проблемы.
Тонкая настройка на следах рассуждения
Выберите правильные и неверные следы рассуждения для каждой проблемы на основе основной истины.
Точная настройка модели, используя выбранные следы рассуждения, используя DPO или NLHF, где предпочтение положительно для правильных трассов, отрицательными для неправильных трассов.
Исключите вес предпочтения по количеству предпринятых шагов, т. Е. Если неверно, то более длительные отрицательные следы должны получить большее отрицательное вознаграждение. Правильные следы, которые короче, должны получить более позитивное вознаграждение.
Настраивайте модель на этих следах рассуждений со смешиванием других данных, как обычно.
Используйте эту модель, чтобы генерировать следы рассуждений для немного более сложных проблем, которые эта новая модель едва может сделать.
Повторная генерация следов рассуждений и тонкая настройка до тех пор, пока модель не сможет сделать самые сложные проблемы, так что объем следов рассуждений как потребляется больше типов проблем (но не все типы, поскольку не всегда требуется).
Спекуляции
MCT, TOT, агенты и т. Д. Не требуются при обучении или времени вывода.
Человеческая маркировка или человеческая проверка следов рассуждений не требуется.
Точно настроенные модели для проверки не требуются, в зависимости от того, что.
RLHF не требуется строго, просто DPO.
OpenAI использует Deep RL для обучения следы рассуждений, но я не думаю, что это требуется. Самопроизводство мощно, но может быть имитирован DPO.
Глубокий RL-это просто способ эффективного создания данных, но не требуется и просто удерживается от предыдущей работы Openai.
Оправдания
[P10]-это недавняя статья, которая проверяет наше предложение об использовании самогрированных данных многообразивых, чтобы немного постепенно подтолкнуть модель к самокоррекции.
Цели проекта
Генерировать следы рассуждения, используя предложенный подход.
Точно настроить модель на сгенерированных следах рассуждения.
Оцените производительность и сравните ее с существующими моделями с нулевым выстрелом, небольшим количеством выстрелов, кроватки и т. Д.
Другие проекты:
Ключевое отличие с Raspberry заключается в том, что они сосредоточены на жестких подсказках, в то время как мы думаем, что прогрессивный подход к обучению с повторяющейся тонкой настройкой будет начаться в отношении O1.
Ключевое отличие с G1 заключается в том, что они сосредоточены только на O1-подобном поведении, без акцента на то, как точно навязать O1.
Антрическая и Google API поддержка быстрого кэширования означает гораздо дешевле. VLLM поддерживает кэширование префикса, которое тоже помогает.
Текущий статус
Этот проект находится на начальных этапах. Результаты и сравнения будут добавлены, когда они станут доступны.
Тодо:
Настройка базового антропного корпуса с помощью быстрого кэширования
Настройка базового приложения Streamlit для легко мониторинга выходов
Ищите поддержку сообщества
Каждое (скажем) 9 шагов, спросите, думает ли модель, у нее есть окончательный ответ, и если да, то попросите его поместить этот ответ в тегах <final_answer> XML для извлечения и завершения следа рассуждения.
Добавить отдачу
Добавить Ollama, Google, Azure, Openai, Groq, антропные API с быстрым кэшированием для антропного
Добавьте резюме на высоком уровне блоков текста, таких как O1
Улучшение системной подсказки, также меняйте его или отдельно от пользователя следующих подсказок
Добавьте проверку, который пробегает окно истории и отдельно критикует помощника вывода
Используйте существующие наборы данных с основной истиной, чтобы определить проблемы, для которых COT достигает успеха после некоторых испытаний
Соберите подсказки для сбора, удобные для кости и собирать положительные и отрицательные следы рассуждения
Тонкая настройка с DPO, включая сочетание нормальных данных, а также с аналогичным распределением
Повторите в следующем раунде подсказок, удобных для мыши, за исключением оригинальных подсказок, так и Bootstrap
Тонкая настройка поверх тонкой настройки, в том числе со смешиванием нормальных данных, а также с аналогичным распределением
Повторите в целом до начала самолета.
Более сложные проблемы все еще недоступны, что O1-просмотр получает только около 50% случаев (кодовые агенты получают 90% случаев):
Простые проблемы надежно решаются:
Внося
Мы приветствуем вклад сообщества. Пожалуйста, смотрите наш файл apponting.md для руководящих принципов о том, как участвовать.
Проблемы:
Продолжить кнопку в приложении, оставляя серые старые чаты, лучше всего, если запустить чисто
Подсчет токенов появляется только после продолжения удара, лучше всего, если был каждый ход
Об авторе
Джонатан МакКинни - директор по исследованиям в H2O.AI с опытом в области астрофизики и машинного обучения. Его опыт включает в себя:
Бывший профессор астрофизики в UMD [B1] [B2] [B3] [B4]
7 -летний опыт работы с продуктами Automl на H2O.AI [B5] [B6]
Недавняя работа по точной настройке LLMS, RAG и AI-агентов (H2OGPT) [B7] [B8]
Смотрите другие мои проекты, такие как H2OGPT и оперативное управление
Отказ от ответственности
Этот проект является спекулятивным и основанным на общедоступной информации о работе Openai. Он не связан с OpenAI и не одобрен.
[P0] Подача в цепочке мышления вызывает рассуждения в моделях крупных языков: https://arxiv.org/abs/2201.11903
[P1] Звезда: начальная обработка рассуждений с рассуждением: https://arxiv.org/abs/2203.14465
[P2] Давайте проверим шаг за шагом: https://arxiv.org/abs/2305.20050
[P3] Тихо-звезда: Языковые модели могут научить себя думать, прежде чем говорить: https://arxiv.org/abs/2403.09629
[P4] Подумайте, прежде чем говорить: модели языка обучения с токенами паузы: https://arxiv.org/abs/2310.022266
[P5] Нэш обучение на отзыве человека: https://arxiv.org/abs/2312.00886
[P6] Скаметное время тестирования LLM вычислить оптимально может быть более эффективным, чем параметры масштабирования модели https://arxiv.org/abs/2408.03314
[P7] Улучшение решения проблем LLM с помощью Reap: Отражение, явная задача деконструкция и расширенное подсказка https://arxiv.org/abs/2409.09415
[P8] Агент Q: Расширенные рассуждения и обучение для автономных агентов AI https://arxiv.org/abs//2408.07199
[P9] Законы масштабирования масштабирования с настольными играми https://arxiv.org/abs/2104.03113
[P10] Обучение языковым моделям для самоправки с помощью обучения подкреплению https://arxiv.org/abs/2409.12917
Связанные проекты:
[Команда OpenO1] O1 с открытым исходным кодом
[Gair-nlp] o1 ездить на репликацию: отчет о стратегическом прогрессе
[Maitrix.org] LLM Soideors
[Bklieger-Groq] G1: Использование Llama-3.1 70b на Groq для создания O1-подобных цепочек рассуждений
[O1-Chain-of-мысль] Транскрипция следов рассуждений O1 из сообщения в блоге Openai
[Toyberry] Toyberry: Конечная до конца крошечная реализация системы рассуждений O1 O1 с использованием MCTS и LLM в качестве бэкэнда
Но ИМХО, LLM просто видит другой токен, чем <thinking> , и теперь это <reasoning> .
Ресурс:
[Потрясающая-llm-Strawberry] потрясающая страдая
Связанные видео:
https://www.youtube.com/watch?v=tpun1Uokecc (каскадные подсказки с повторяющейся коткой)
https://youtu.be/ey9ihse82hc?t=2742 (Noam Brown на самостоятельстве с LLMS)
https://youtu.be/nvaxucibb-c?list=pldrirstud7wwjxhoi9vvxeo9ktufbxlhf (почему Vlad Tenev и Tudor Achim of Harmonic думают, что AI собирается изменить математику-и почему это имеет значение)
https://youtu.be/jplusxjpdra?si=yspkfx57t7eyel5o (Noam Brown's, Ilge Akkaya и Hunter Lightman на O1 и обучение LLMS лучше)