open strawberry
1.0.0
Demo of open-?strawberry? project: https://huggingface.co/spaces/pseudotensor/open-strawberry

A proof-of-concept to construct of reasoning traces to build an open-source version of OpenAI o1 as inspired by OpenAI's Strawberry algorithm.
If you want to support the project, turn ★ into (top-right corner) and share it with your friends.
Contributions very welcome!
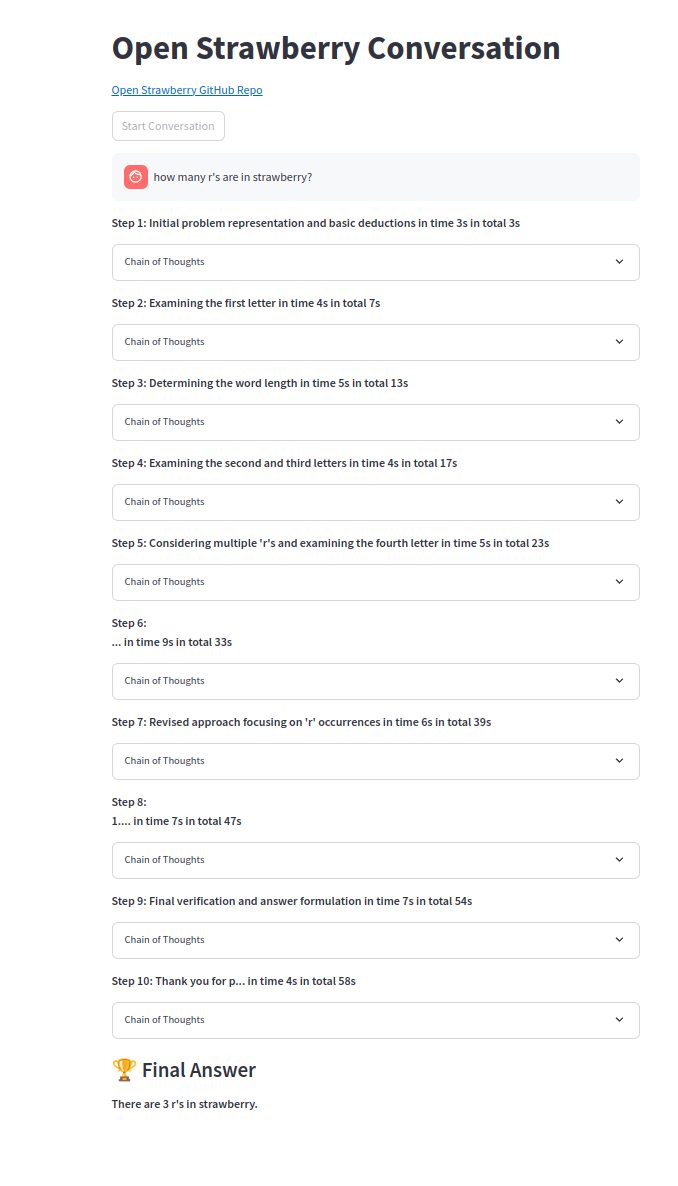
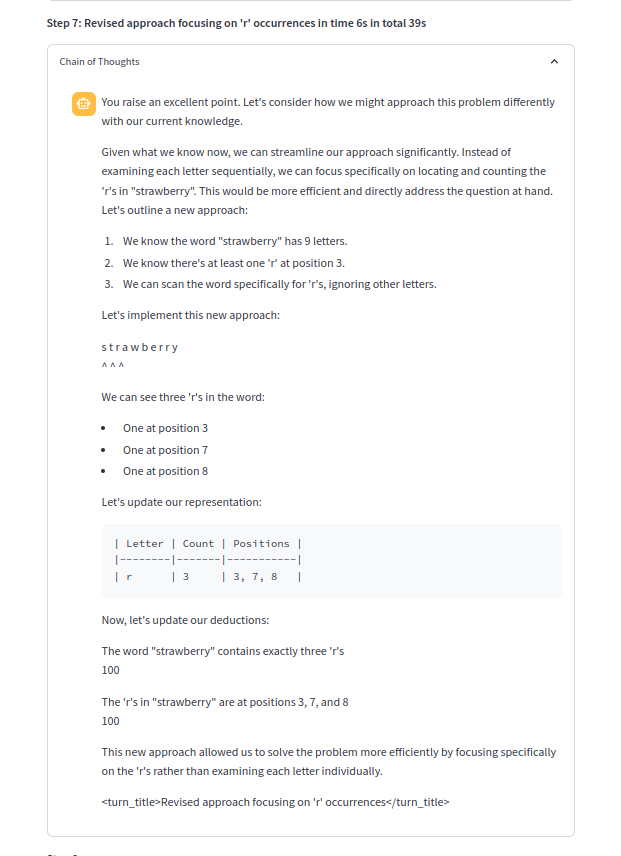
One of the chains of thought:
Python >=3.10 should be fine, then:
pip install -r requirements.txtFill .env with required API keys etc or set ENVs, e.g.:
# OpenAI
# Can be OpenAI key or vLLM or other OpenAI proxies:
OPENAI_API_KEY=
# only require below for vLLM or other OpenAI proxies:
OPENAI_BASE_URL=
# only require below for vLLM or other OpenAI proxies:
OPENAI_MODEL_NAME=
# ollama
OLLAMA_OPENAI_API_KEY=
OLLAMA_OPENAI_BASE_URL=
# quoted list of strings or string
OLLAMA_OPENAI_MODEL_NAME=
# Azure
AZURE_OPENAI_API_KEY=
OPENAI_API_VERSION=
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_DEPLOYMENT=
# not required
AZURE_OPENAI_MODEL_NAME=
# Anthropic prompt caching very efficient
ANTHROPIC_API_KEY=
GEMINI_API_KEY=
# groq fast and long context
GROQ_API_KEY=
# cerebras only 8k context
CEREBRAS_OPENAI_API_KEY=
# WIP: not yet used
MISTRAL_API_KEY=
HUGGING_FACE_HUB_TOKEN=
REPLICATE_API_TOKEN=
TOGETHERAI_API_TOKEN=For ollama, one can use the OpenAI service:
#Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve &> ollama.log &
ollama run mistral:v0.3then choose set .env with OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ and e.g. OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3 or list of ollama models: OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"],
then run for CLI:
python src/open_strawberry.py --model ollama:mistral:v0.3or pick the model in the UI.
Using UI:
export ANTHROPIC_API_KEY=your_api_key
streamlit run src/app.pythen open the browser to http://localhost:8501 (should pop-up automatically).
Using CLI:
export ANTHROPIC_API_KEY=your_api_key
python src/open_strawberry.pythen choose prompt.
The project is in its initial stages to explore generation of reasoning traces for specific problems as proof of concept.
Note that the demo prompt is simple models and even sonnet3.5 and gpt-4o cannot find a solution even with standard CoT. Only o1-mini or o1-preview can sometimes get, although code agents and easily solve it.
open-strawberry is based on speculations about OpenAI's Strawberry, a refined search-generation algorithm for generating and verifying training data.
This project aims to recreate a similar system using open-source tools and methodologies.
Bootstrapping is key via progressive learning.
Repeat generation of reasoning traces and fine-tuning until the model can do the hardest problems, such that the scope of reasoning traces as consumed more types of problems (but not all types since not always required).
[P10] is recent paper that validates our proposal of using self-generated multi-turn data to slightly progressively push the model towards self-correction.
Other projects:
This project is in its initial stages. Results and comparisons will be added as they become available.
TODO:
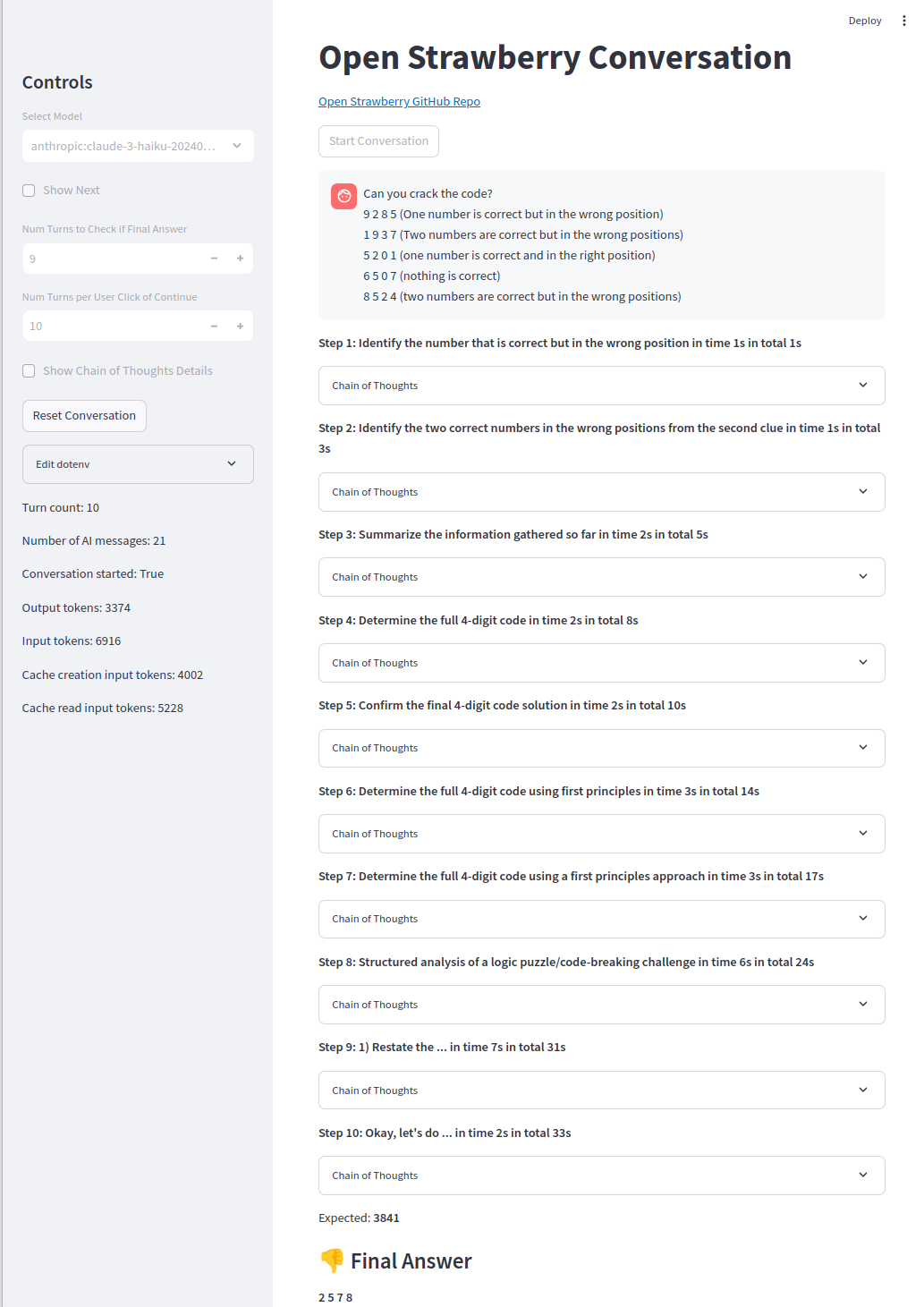
Harder problems are still out of reach, which o1-preview only gets about 50% of the time (code agents get 90% of the time):
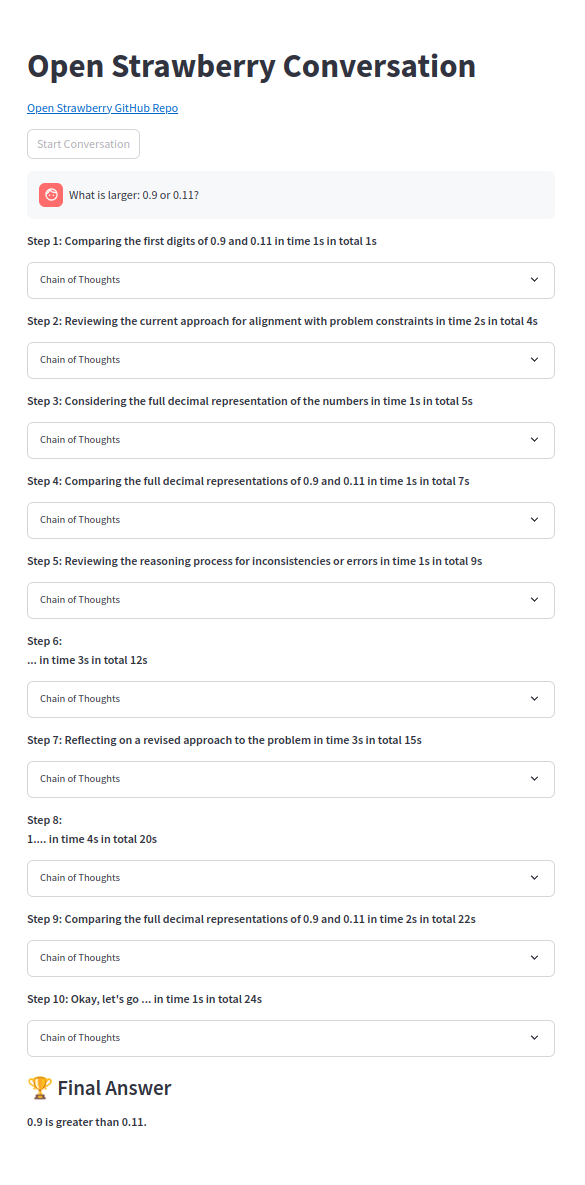
Easy problems are reliably solved:
We welcome contributions from the community. Please see our CONTRIBUTING.md file for guidelines on how to participate.
Issues:
Jonathan McKinney is the Director of Research at H2O.ai with a background in astrophysics and machine learning. His experience includes:
This project is speculative and based on publicly available information about OpenAI's work. It is not affiliated with or endorsed by OpenAI.
[1] https://openai.com/index/learning-to-reason-with-llms/
[B1] https://umdphysics.umd.edu/about-us/news/department-news/697-jon-mckinney-publishes-in-science-express.html
[B2] https://umdphysics.umd.edu/academics/courses/945-physics-420-principles-of-modern-physics.html
[B3] https://www.linkedin.com/in/jonathan-mckinney-32b0ab18/
[B4] https://scholar.google.com/citations?user=5L3LfOYAAAAJ&hl=en
[B5] https://h2o.ai/company/team/makers/
[B6] https://h2o.ai/platform/ai-cloud/make/h2o-driverless-ai/
[B7] https://arxiv.org/abs/2306.08161
[B8] https://github.com/h2oai/h2ogpt
[P0] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models: https://arxiv.org/abs/2201.11903
[P1] STaR: Bootstrapping Reasoning With Reasoning: https://arxiv.org/abs/2203.14465
[P2] Let's Verify Step by Step: https://arxiv.org/abs/2305.20050
[P3] Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking: https://arxiv.org/abs/2403.09629
[P4] Think before you speak: Training Language Models With Pause Tokens: https://arxiv.org/abs/2310.02226
[P5] Nash Learning from Human Feedback: https://arxiv.org/abs/2312.00886
[P6] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters https://arxiv.org/abs/2408.03314
[P7] Enhancing LLM Problem Solving with REAP: Reflection, Explicit Problem Deconstruction, and Advanced Prompting https://arxiv.org/abs/2409.09415
[P8] Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents https://arxiv.org/abs//2408.07199
[P9] Scaling Scaling Laws with Board Games https://arxiv.org/abs/2104.03113
[P10] Training Language Models to Self-Correct via Reinforcement Learning https://arxiv.org/abs/2409.12917
Related Projects:
<thinking> and now it's <reasoning>.Resource:
Related Videos:


