¿Demo de Open-? Strawberry? Proyecto: https://huggingface.co/spaces/pseudotensor/openstrawberry
Una prueba de concepto para la construcción de trazas de razonamiento para construir una versión de código abierto de OpenAI O1 inspirado en el algoritmo de fresa de OpenAi.
Si desea apoyar el proyecto, convierta ★ en (esquina superior derecha) y compártalo con tus amigos.
¡Contribuciones muy bienvenidas!
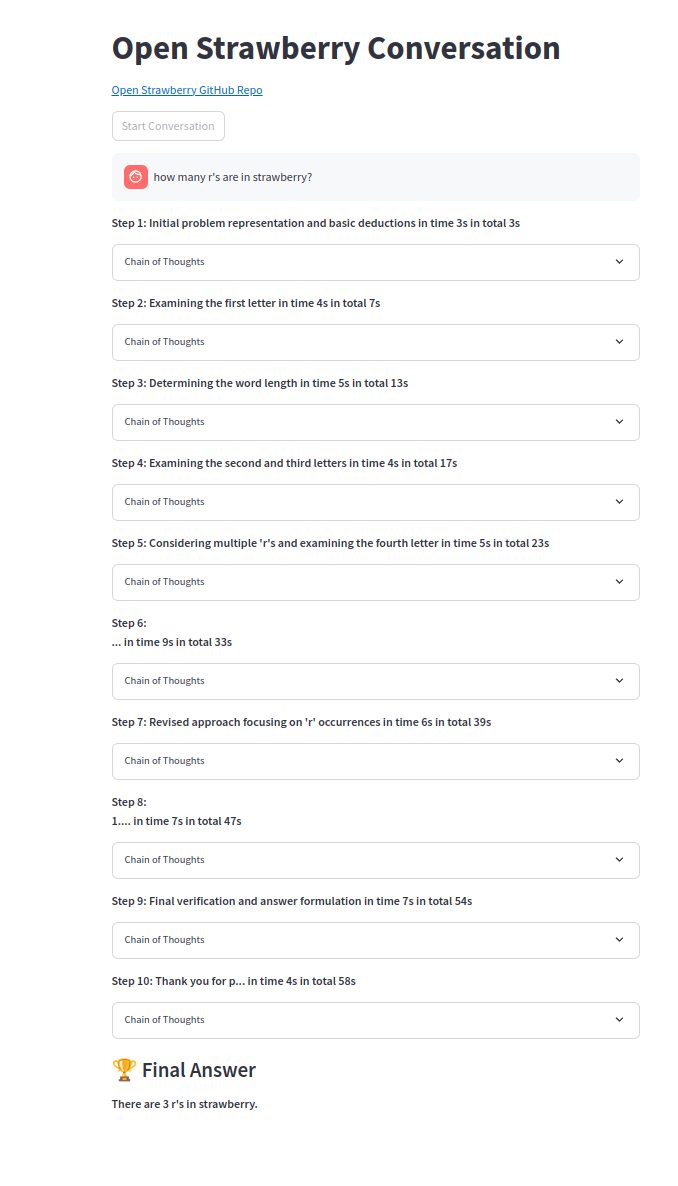
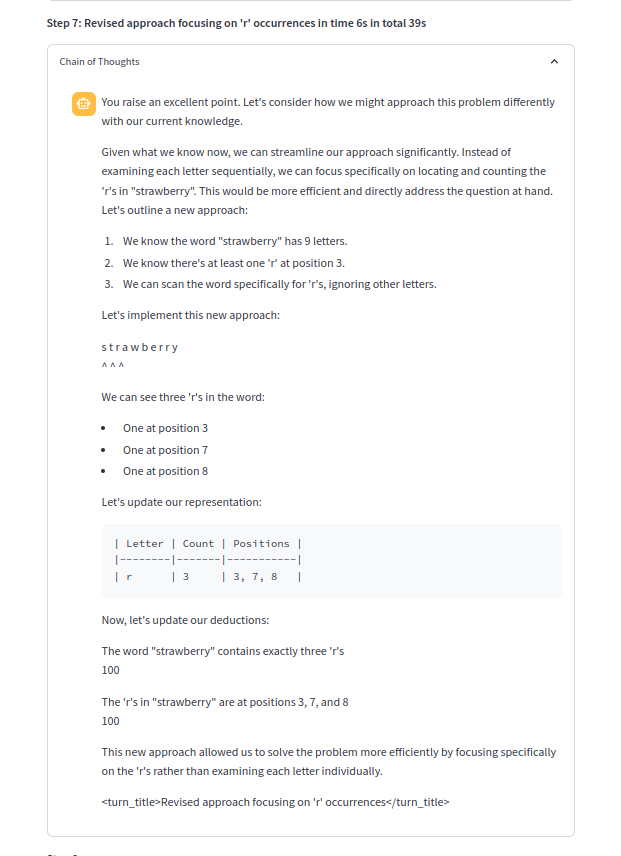
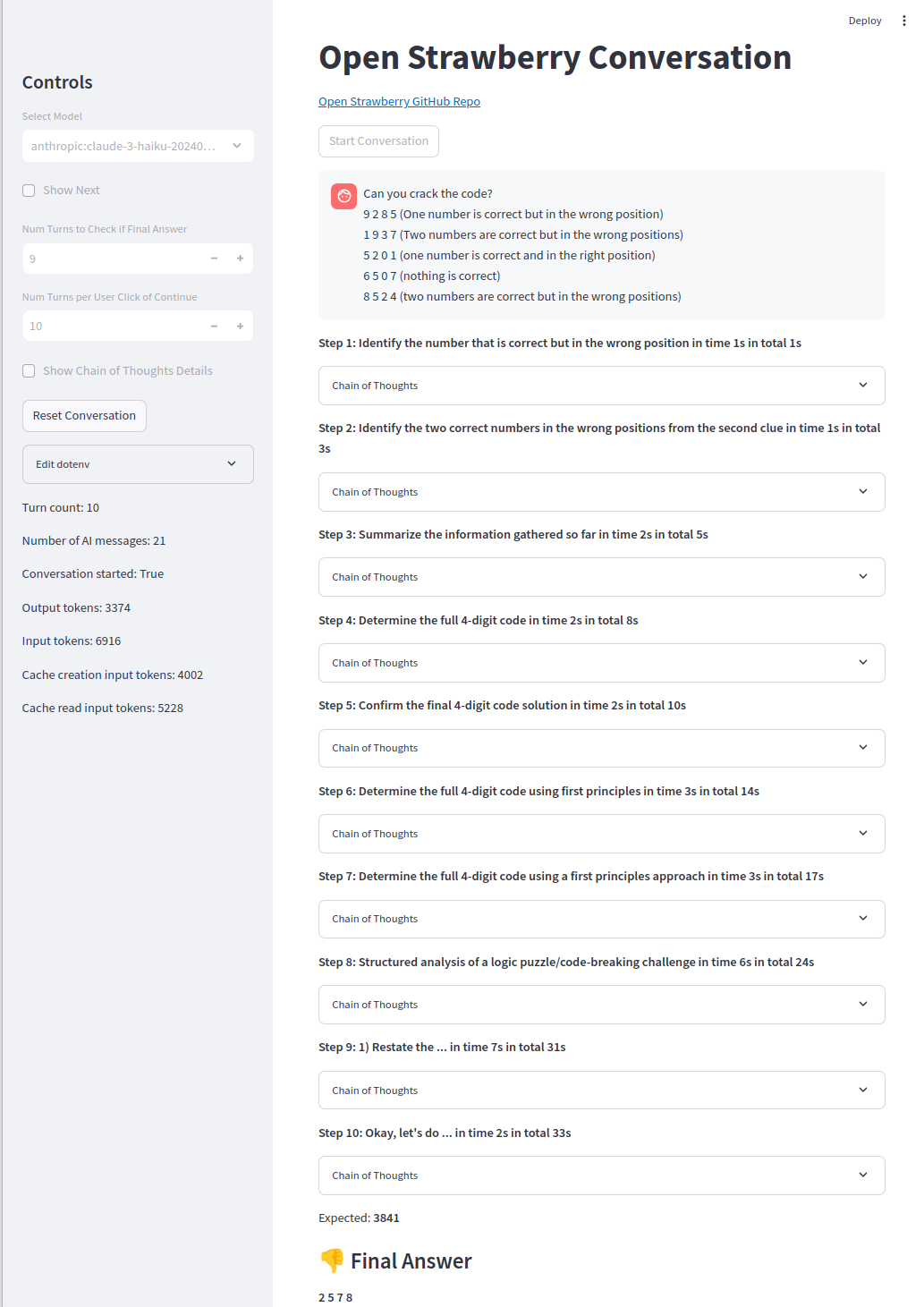
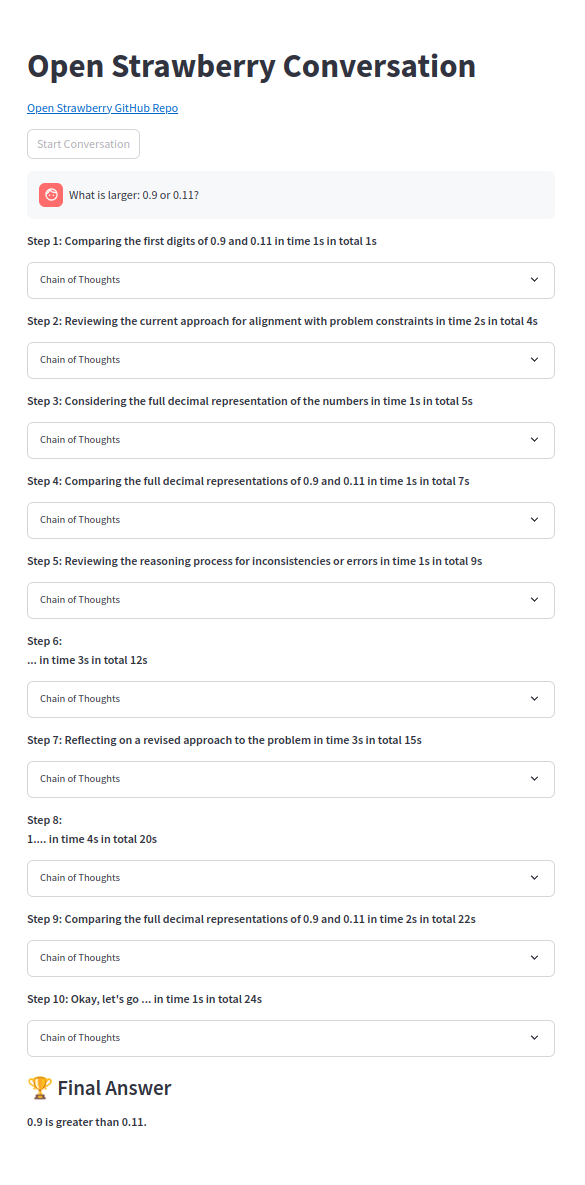
Una de las cadenas de pensamiento:
Instalación
Python> = 3.10 debería estar bien, luego:
pip install -r requirements.txt
Uso
Llenar .env con claves API requeridas, etc. o establecer envs, por ejemplo:
# OpenAI# Can be OpenAI key or vLLM or other OpenAI proxies:OPENAI_API_KEY=# only require below for vLLM or other OpenAI proxies:OPENAI_BASE_URL=# only require below for vLLM or other OpenAI proxies:OPENAI_MODEL_NAME=# ollamaOLLAMA_OPENAI_API_KEY=OLLAMA_OPENAI_BASE_URL=# quoted list of strings or stringOLLAMA_OPENAI_MODEL_NAME=# AzureAZURE_OPENAI_API_KEY=OPENAI_API_VERSION=AZURE_OPENAI_ENDPOINT=AZURE_OPENAI_DEPLOYMENT=# not requiredAZURE_OPENAI_MODEL_NAME=# Anthropic prompt caching very efficientANTHROPIC_API_KEY=GEMINI_API_KEY=# groq fast and long contextGROQ_API_KEY=# cerebras only 8k contextCEREBRAS_OPENAI_API_KEY=# WIP: not yet usedMISTRAL_API_KEY=HUGGING_FACE_HUB_TOKEN=REPLICATE_API_TOKEN=TOGETHERAI_API_TOKEN=
ollama
Para Ollama, uno puede usar el servicio OpenAI:
# Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve &> ollama.log &
ollama run mistral:v0.3
Luego elija establecer .env con OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ y eg OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3 o lista de modelos OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"]
El proyecto está en sus etapas iniciales para explorar la generación de trazas de razonamiento para problemas específicos como prueba de concepto.
Tenga en cuenta que el indicador de demostración son modelos simples e incluso sonnet3.5 y GPT-4O no pueden encontrar una solución incluso con cuna estándar. Solo O1-Mini o O1 prevalecer a veces pueden obtener, aunque agentes de código y resolverlo fácilmente.
Fondo
Open-Strawberry se basa en especulaciones sobre la fresa de OpenAi, un algoritmo refinado de generación de búsqueda para generar y verificar los datos de capacitación.
Este proyecto tiene como objetivo recrear un sistema similar utilizando herramientas y metodologías de código abierto.
Definiciones especulativas
P *: Un algoritmo RL de generación de generación de búsqueda primordial hipotético desarrollado por OpenAI para generar datos de capacitación.
Strawberry : un algoritmo RL Deep RL de generación de búsqueda avanzada por OpenAI para generar y verificar datos de capacitación.
O1 : GPT-4O y GPT-4O-Mini, pero afinados en datos de fresa, incluidos O1-Mini, O1-Preview, O1 y O1-IOI. [1]
Orión : modelo basado en GPT-5 que incorpora datos sintéticos de Strawberry y administra las consultas de razonamiento 0-SHOT versus largas mejor.
Generando rastros de razonamiento
Bootstrapping es clave a través del aprendizaje progresivo.
Bootstrap comenzando con modelos supervisados supervisados existentes, ajustados de instrucciones y sintonizados con preferencias utilizando el historial de chat múltiple.
Implemente un sistema rápido que guía al LLM a tomar pasos incrementales hacia una solución.
Solicitudes de cuna útiles aleatorizadas del usuario (por ejemplo, no solo a continuación, sino "¿Estás seguro?" "¿Algún error?" "¿Cómo verificarías tu respuesta?") Para un razonamiento e introspección ilícita.
Haga hincapié en el LLM para dar el paso más minúsculo hacia la solución, por ejemplo, se prefiere una sola frase o oración. Solo una vez que se produciría la respuesta final si se dará una respuesta completa extendida.
Generar trazas de razonamiento de chat múltiples giros
A veces, pregunte si el modelo confía en una respuesta. Si es así, pídale que coloque esa respuesta en las etiquetas <final_answer> xml. Si se hace, entonces termine la generación de trazas de razonamiento.
Emplee un sistema de verificación para verificar los errores en el historial de chat.
Genere múltiples rastros de razonamiento por problema.
Aplique este proceso a un gran conjunto de problemas con verdades terrestres verificables.
Identifique los problemas que el modelo de instrucción existente puede hacer apenas con cuna fuerte y alta temperatura para un número de repeticiones fijas (por ejemplo, 20).
Ajuste de rastreos de razonamiento
Seleccione trazas de razonamiento correctas e incorrectas para cada problema basado en la verdad del suelo.
Atrae un modelo utilizando las trazas de razonamiento seleccionadas usando DPO o NLHF, donde la preferencia es positiva para trazas correctas, negativas para trazas incorrectas.
Sesgar el peso de preferencia por número de pasos tomados, es decir, si es incorrecto, entonces las trazas negativas más largas deberían obtener una mayor recompensa negativa. Los rastros correctos que son más cortos deberían obtener una recompensa más positiva.
Atrae el modelo en estos rastros de razonamiento con la combinación de otros datos como de costumbre.
Use este modelo para generar trazas de razonamiento para problemas ligeramente más difíciles que este nuevo modelo apenas puede hacer.
Repita la generación de rastros de razonamiento y el ajuste fino hasta que el modelo pueda hacer los problemas más difíciles, de modo que el alcance de los trazas de razonamiento se consumiera más tipos de problemas (pero no todos los tipos, ya que no siempre es necesario).
Especulaciones
MCTS, TOT, Agentes, etc. No se requieren en el tiempo de entrenamiento o inferencia.
No se requiere etiquetado humano o verificación humana de trazas de razonamiento.
No se requieren modelos ajustados para la verificación, el paso.
RLHF no es estrictamente requerido, solo DPO.
Operai está utilizando Deep RL para entrenar los rastros de razonamiento, pero no creo que esto sea necesario. La autocompasión es poderosa, pero puede ser imitada por DPO.
Deep RL es solo una forma de generar datos de manera eficiente, pero no es necesaria y solo se espera del trabajo previo de OpenAI en él.
Justificaciones
[P10] es un documento reciente que valida nuestra propuesta de uso de datos de giro múltiples autogenerados para impulsar ligeramente progresivamente el modelo hacia la autocorrección.
Proyecto de objetivos
Genere trazas de razonamiento utilizando el enfoque propuesto.
Atrae un modelo en las trazas de razonamiento generadas.
Evaluar el rendimiento y compararlo con los modelos existentes con cero disparos, pocos disparos, cuna, etc.
Otros proyectos:
La diferencia clave con Raspberry es que se centran en las indicaciones difíciles, mientras que creemos que un enfoque de aprendizaje progresivo con ajuste fino repetido arrancará hacia O1.
La diferencia clave con G1 es que se centran solo en el comportamiento similar a O1, sin énfasis sobre cómo ajustar hacia O1.
El soporte de API antrópico y Google del almacenamiento en caché rápido significa mucho más barato de ejecutar. VLLM es compatible con el almacenamiento en caché del prefijo que también ayuda a eso.
Estado actual
Este proyecto está en sus etapas iniciales. Se agregarán resultados y comparaciones a medida que estén disponibles.
HACER:
Configurar un caso antrópico básico con caché de caché rápido
Configurar la aplicación Basic Streamlit para monitorear fácilmente las salidas
Busque apoyo comunitario
Cada (digamos) 9 pasos, pregunte si el modelo cree que tiene una respuesta final, y si es así, pídale que coloque esa respuesta en las etiquetas <final_answer> XML para la extracción y terminación de la traza de razonamiento.
Agregar retroceso
Agregue Ollama, Google, Azure, OpenAi, Groq, API antrópicas con un almacenamiento en caché rápido para antrópico
Agregue un resumen de alto nivel de bloques de texto como O1
Mejorar la solicitud del sistema, variarlo tan o por separado de las siguientes indicaciones del usuario
Agregue el verificador que muestre la ventana de la historia y critique por separado la salida del asistente
Utilice conjuntos de datos existentes con la verdad de tierra para identificar problemas para los cuales la cuna logra el éxito después de algunas pruebas
Harvestas indicaciones amigables con la cuna y recolectar rastros de razonamiento positivo y negativo
Tune fino con DPO, incluida con la combinación de datos normales, también con una distribución similar
Repita en la siguiente ronda de indicaciones amigables con la cuna, excluyendo las indicaciones originales, al igual que Bootstrap
Tune fino en la parte superior del ajuste fino, incluida con la combinación de datos normales, también con una distribución similar
Repita en general hasta que se repita a un modelo más inteligente
Los problemas más duros aún están fuera del alcance, que O1-previa solo obtiene aproximadamente el 50% del tiempo (los agentes del código obtienen el 90% del tiempo):
Los problemas fáciles se resuelven de manera confiable:
Que contribuye
Agradecemos las contribuciones de la comunidad. Consulte nuestro archivo contribuyente. MD para obtener pautas sobre cómo participar.
Asuntos:
Continuar el botón en la aplicación deja chats viejos grises, mejor si se inicia limpiamente
El conteo de tokens solo aparece después del éxito continúa, lo mejor si fue cada turno
Sobre el autor
Jonathan McKinney es el director de investigación en H2O.AI con experiencia en astrofísica y aprendizaje automático. Su experiencia incluye:
Ex profesor de astrofísica en UMD [B1] [B2] [B3] [B4]
7 años de experiencia con productos Automl en H2O.AI [B5] [B6]
Trabajo reciente sobre agentes LLMS, RAG y AI (H2OGPT) [B7] [B8]
Vea mis otros proyectos como H2OGPT y la ingeniería rápida
Descargo de responsabilidad
Este proyecto es especulativo y se basa en información disponible públicamente sobre el trabajo de OpenAI. No está afiliado o respaldado por OpenAI.
[P0] La provisión de la cadena de pensamiento provoca un razonamiento en modelos de idiomas grandes: https://arxiv.org/abs/2201.11903
[P1] Estrella: Bootstrapping Razonamiento con razonamiento: https://arxiv.org/abs/2203.14465
[P2] Verifiquemos paso a paso: https://arxiv.org/abs/2305.20050
[P3] STORS-STAR: los modelos de idiomas pueden enseñarse a pensar antes de hablar: https://arxiv.org/abs/2403.09629
[P4] Piense antes de hablar: Modelos de lenguaje de capacitación con tokens de pausa: https://arxiv.org/abs/2310.02226
[P5] Aprendizaje de Nash de los comentarios humanos: https://arxiv.org/abs/2312.00886
[P6] Escalado LLM Tiempo de prueba Computas de manera óptima puede ser más efectivo que los parámetros del modelo de escala https://arxiv.org/abs/2408.03314
[P7] Mejora de la resolución de problemas de LLM con REAP: reflexión, deconstrucción de problemas explícitos y avanzado que solicitó https://arxiv.org/abs/2409.09415
[P8] Agente Q: razonamiento avanzado y aprendizaje para agentes de IA autónomos https://arxiv.org/abs//2408.07199
[P9] Escalado de leyes de escala con juegos de mesa https://arxiv.org/abs/2104.03113
[P10] Modelos de lenguaje de capacitación para autocorregir a través de refuerzo aprendiendo https://arxiv.org/abs/2409.12917
Proyectos relacionados:
[Equipo de Opero1] Open-Source O1
[GAIR-NLP] Viaje de replicación O1: un informe de progreso estratégico
[Maitrix.org] LLM razonadores
[Bklieger-Groq] G1: Uso de Llama-3.1 70b en Groq para crear cadenas de razonamiento similares a O1
[Cadena de pensamiento de O1] Transcripción de trazas de razonamiento O1 de la publicación de blog de Operai
[Toyberry] Toyberry: una pequeña implementación de fin a extremo del sistema de razonamiento O1 de Openai utilizando MCTS y LLM como backend
Pero en mi humilde opinión, el LLM solo ve un token diferente a <thinking> y ahora es <reasoning> .
Recurso:
[Awsome-llmtrawberry] Awsome-llm-strawberry
Videos relacionados:
https://www.youtube.com/watch?v=tpun1Uokecc (indicaciones en cascada con cot repetido)
https://youtu.be/ey9ihse82hc?t=2742 (Noam Brown en la jugada de sí mismo con LLMS)
https://youtu.be/nvaxucibb-c?list=pldirstud7wwjxhoi9vvxeo9ktufbxlhf (por qué Vlad Tenev y Tudor Achim de armónico piensa que AI está a punto de cambiar las matemáticas, y por qué importa))
https://youtu.be/jplusxjpdra?si=yspkfx57t7Eyel5o (Noam Brown, Ilge Akkaya y Hunter Lightman en O1 y enseñando LLM para razonar mejor)