open strawberry
1.0.0
开放的演示 - 草莓?项目:https://huggingface.co/spaces/pseudotensor/open-strawberry

构造推理轨迹的概念概念,以构建受Openai的草莓算法启发的OpenAi O1的开源版本。
如果您想支持该项目,请将★变成(右上角)并与您的朋友分享。
贡献非常欢迎!
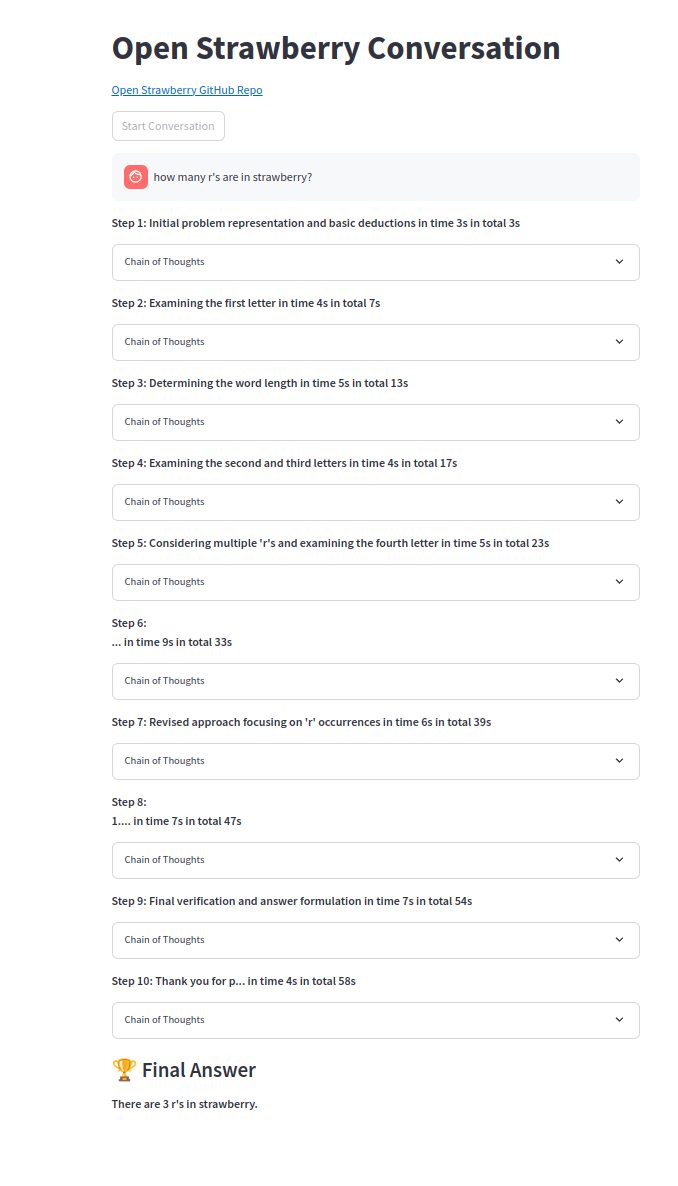
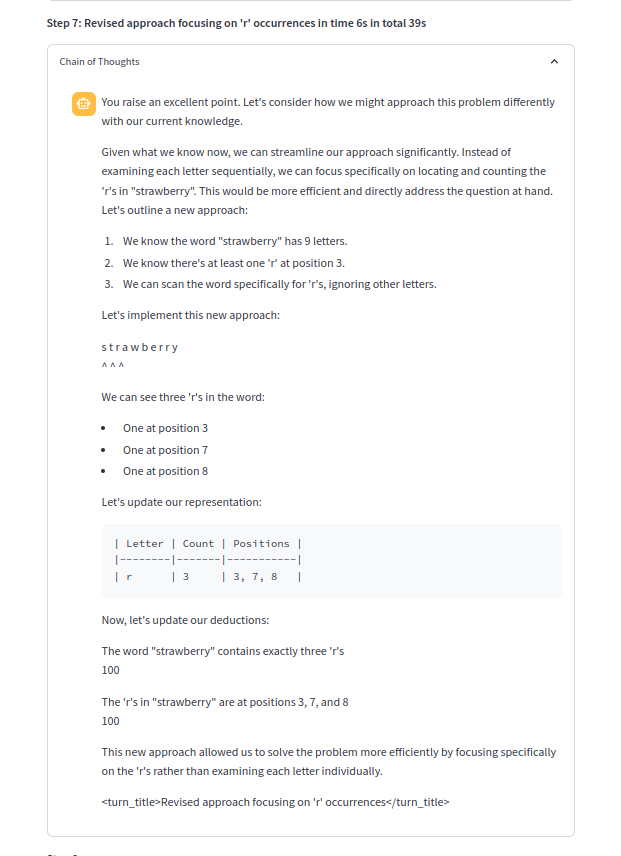
思想的链条之一:
python> = 3.10应该很好,然后:
pip install -r requirements.txt用所需的API键等填充.env或设置Envs,例如:
# OpenAI
# Can be OpenAI key or vLLM or other OpenAI proxies:
OPENAI_API_KEY =
# only require below for vLLM or other OpenAI proxies:
OPENAI_BASE_URL =
# only require below for vLLM or other OpenAI proxies:
OPENAI_MODEL_NAME =
# ollama
OLLAMA_OPENAI_API_KEY =
OLLAMA_OPENAI_BASE_URL =
# quoted list of strings or string
OLLAMA_OPENAI_MODEL_NAME =
# Azure
AZURE_OPENAI_API_KEY =
OPENAI_API_VERSION =
AZURE_OPENAI_ENDPOINT =
AZURE_OPENAI_DEPLOYMENT =
# not required
AZURE_OPENAI_MODEL_NAME =
# Anthropic prompt caching very efficient
ANTHROPIC_API_KEY =
GEMINI_API_KEY =
# groq fast and long context
GROQ_API_KEY =
# cerebras only 8k context
CEREBRAS_OPENAI_API_KEY =
# WIP: not yet used
MISTRAL_API_KEY =
HUGGING_FACE_HUB_TOKEN =
REPLICATE_API_TOKEN =
TOGETHERAI_API_TOKEN =对于Ollama,可以使用OpenAi服务:
# Shut down ollama and re-run on whichever GPUs wanted:
sudo systemctl stop ollama.service
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST=0.0.0.0:11434 ollama serve & > ollama.log &
ollama run mistral:v0.3 OLLAMA_OPENAI_MODEL_NAME=ollama:mistral:v0.3选择使用OLLAMA_OPENAI_BASE_URL=http://localhost:11434/v1/ and选择.env OLLAMA_OPENAI_MODEL_NAME="[ollama:mistral:v0.3"] 。
python src/open_strawberry.py --model ollama:mistral:v0.3或在UI中选择模型。
使用UI:
export ANTHROPIC_API_KEY=your_api_key
streamlit run src/app.py然后将浏览器打开至http:// localhost:8501(应自动弹出)。
使用CLI:
export ANTHROPIC_API_KEY=your_api_key
python src/open_strawberry.py然后选择提示。
该项目处于其初期阶段,旨在探索特定问题作为概念证明的推理痕迹的产生。
请注意,演示提示是简单的型号,即使使用标准COT,也无法找到SONNET3.5和GPT-4O。尽管代码代理并可以轻松解决它,但有时只能获得O1-Mini或O1-preiview。
开阔的晶布基于关于Openai的草莓的猜测,Openai的草莓是一种精致的搜索生成算法,用于生成和验证培训数据。
该项目旨在使用开源工具和方法来重新创建类似的系统。
引导是通过渐进学习的关键。
重复生成推理轨迹并进行微调,直到模型可以解决最严重的问题,以便推理轨迹的范围消耗了更多类型的问题(但不是所有类型的问题)。
[P10]是最近的论文,该论文验证了我们使用自我生成的多转移数据以稍微逐步将模型推向自我纠正的建议。
其他项目:
该项目处于初始阶段。结果和比较将在可用时添加。
托多:
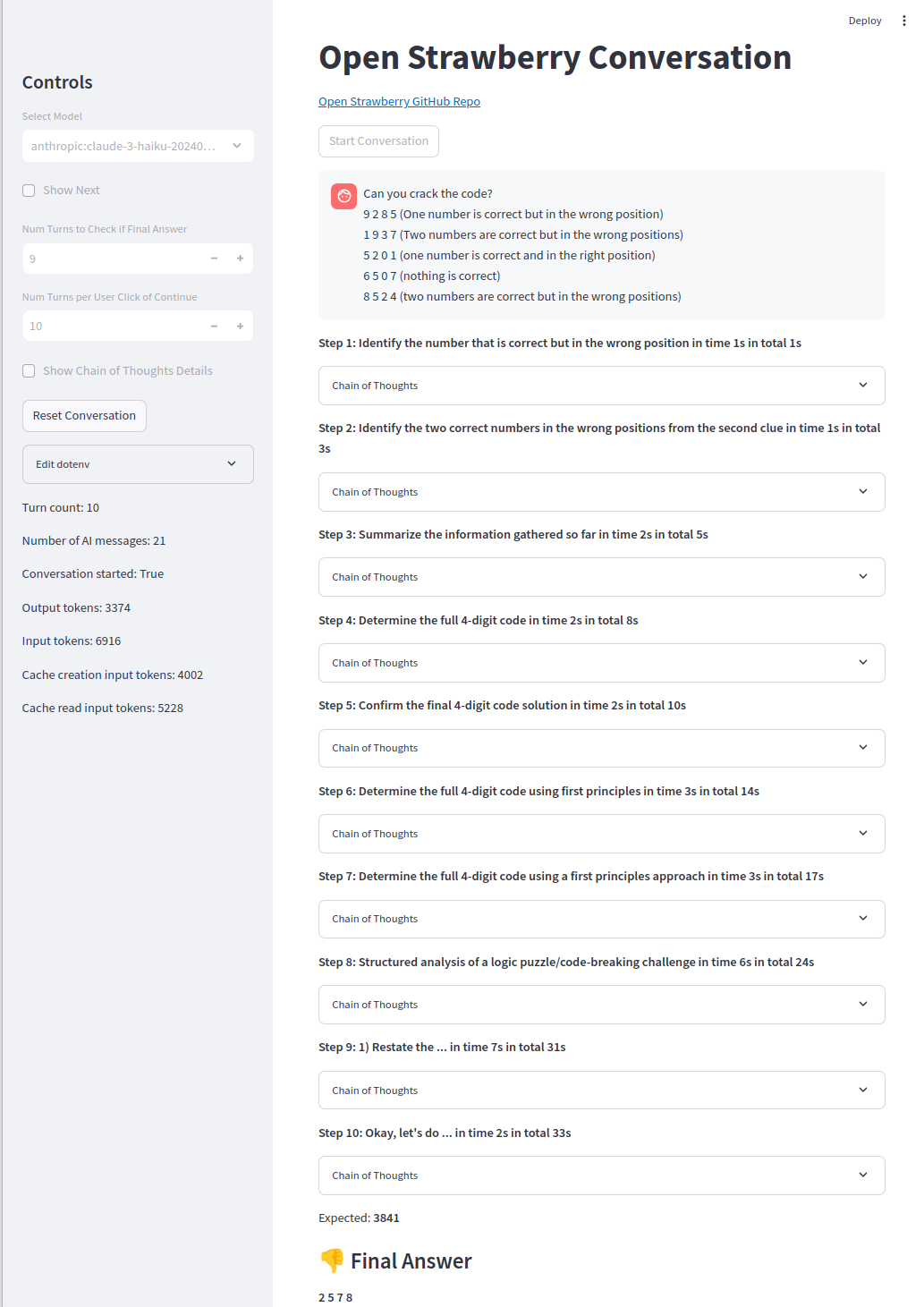
更困难的问题仍然是遥不可及的,O1-preiview只会得到约50%的时间(代码代理人获得90%的时间):
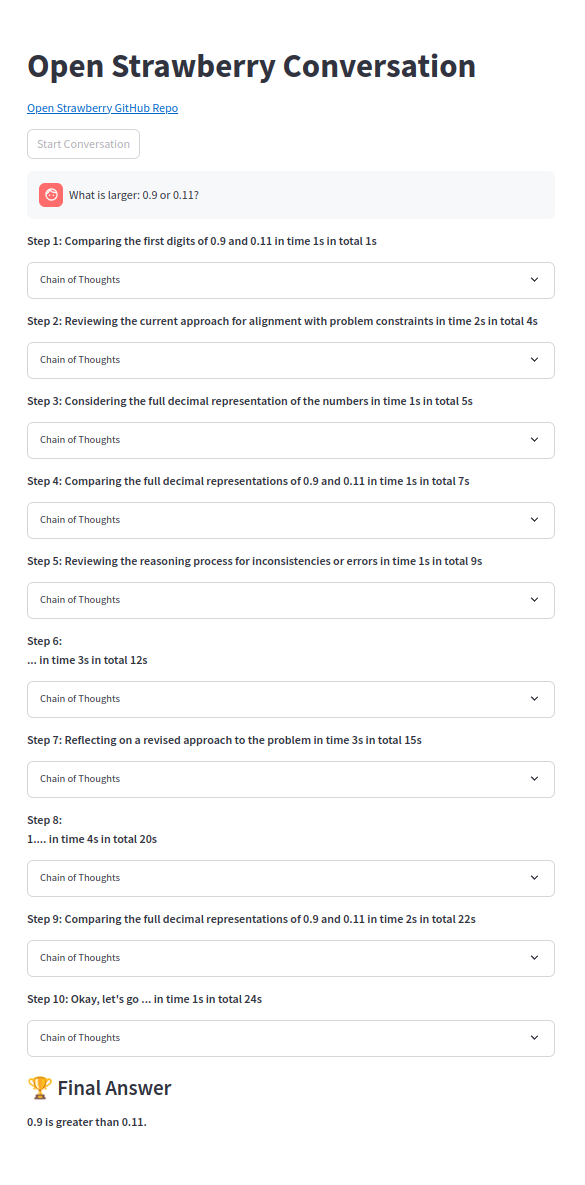
简单的问题可靠地解决:
我们欢迎社区的贡献。请参阅我们的贡献.md文件,以获取有关如何参与的指南。
问题:
乔纳森·麦金尼(Jonathan McKinney)是H2O.AI的研究总监,其背景是天体物理学和机器学习的背景。他的经验包括:
该项目具有投机性,并基于有关OpenAI工作的公开信息。它不隶属于Openai或认可。
[1] https://openai.com/index/learning-to-reason-with-llms/
[B1] https://umdphysics.umd.edu/about-us/news/department-news/697-jon-jon-mckinney-publishney-publishes-in-science-express.html
[B2] https://umdphysics.umd.edu/academics/courses/945-physics-420-principles-of-modern-physics.html
[B3] https://www.linkedin.com/in/jonathan-mckinney-32b0ab18/
[B4] https://scholar.google.com/citations?user = 5l3lfoyaaaaaj&hl=en
[B5] https://h2o.ai/company/team/makers/
[B6] https://h2o.ai/platform/ai-cloud/make/h2o-driverless-ai/
[B7] https://arxiv.org/abs/2306.08161
[B8] https://github.com/h2oai/h2ogpt
[P0]促使大语言模型引发推理的链条:https://arxiv.org/abs/2201.11903
[P1]星:引导推理推理:https://arxiv.org/abs/2203.14465
[P2]让我们逐步验证:https://arxiv.org/abs/2305.20050
[p3]静态明星:语言模型可以在说话之前自我思考:https://arxiv.org/abs/2403.09629
[p4]在说话之前先思考:带有暂停令牌的培训语言模型:https://arxiv.org/abs/2310.02226
[p5]纳什从人类反馈中学习:https://arxiv.org/abs/2312.00886
[P6]比例LLM测试时间计算比缩放模型参数更有效https://arxiv.org/abs/2408.03314
[P7]通过REAP增强LLM问题解决:反射,明确的问题解构和高级提示https://arxiv.org/abs/2409.09415
[P8]代理问:自主AI代理的高级推理和学习https://arxiv.org/abs//2408.07199
[P9]棋盘游戏缩放缩放法律https://arxiv.org/abs/2104.03113
[P10]培训语言模型通过强化学习https://arxiv.org/abs/2409.12917
相关项目:
<thinking>不同的象征,现在是<reasoning> 。资源:
相关视频:


