Medical Electra
1.0.0
问题回答(QA)是自然语言处理(NLP)和信息检索(IR)的领域。质量保证任务基本上是通过使用给定的数据或数据库以自然语言为给定的问题提供精确而快速的答案。在这个项目中,我们解决了有关医疗论文的问题的问题。有很多语言模型发布,可用于问答任务。在这个项目中,我们想开发一种专门在医学领域培训的语言模型。我们的目标是在医学论文上开发特定于上下文的语言模型,比一般语言模型更好。我们使用Electra-Small作为基础模型,并使用医疗纸数据集对其进行了训练,然后在Medical QA数据集上进行了微调。我们训练了三种不同的模型,并将其在下游任务的NLP任务上进行了比较。
您可以在此处访问我们的模型:
Med-Electra小型型号17GB-64K词汇
Med-Electra小型39GB-30.5K vocab https://huggingface.co/enelpi/Med-electra-small-30k-discriminator
Med-Electra小型39GB-64K vocab https://huggingface.co/enelpi/Med-electra-small-64k-discriminator
我们使用了医学论文S2orc。我们使用研究领域过滤了S2ORC数据库,并进行了医学论文。我们使用了两个不同的数据集,包括碎片,我们为17GB数据集进行了11张碎片,并使用了26个碎片用于39GB数据集。之后,我们采用了在PubMed和PubMedCentral上出版的内容。我们仅使用了这些论文的pdf_parses,因为pdf_parses中的句子包含更多信息。
{
"section": "Introduction",
"text": "Dogs are happier cats [13, 15]. See Figure 3 for a diagram.",
"cite_spans": [
{"start": 22, "end": 25, "text": "[13", "ref_id": "BIBREF11"},
{"start": 27, "end": 30, "text": "15]", "ref_id": "BIBREF30"},
...
],
"ref_spans": [
{"start": 36, "end": 44, "text": "Figure 3", "ref_id": "FIGREF2"},
]
}
{
...,
"BIBREF11": {
"title": "Do dogs dream of electric humans?",
"authors": [
{"first": "Lucy", "middle": ["Lu"], "last": "Wang", "suffix": ""},
{"first": "Mark", "middle": [], "last": "Neumann", "suffix": "V"}
],
"year": "",
"venue": "barXiv",
"link": null
},
...
}
{
"TABREF4": {
"text": "Table 5. Clearly, we achieve SOTA here or something.",
"type": "table"
}
...,
"FIGREF2": {
"text": "Figure 3. This is the caption of a pretty figure.",
"type": "figure"
},
...
}
}
17GB的语料库数据摘要
| 句子 | 独特的单词 | 尺寸 | 令牌大小 | |
|---|---|---|---|---|
| 火车 | 111537350 | 27609654 | 16.9GB | 2538210492 |
39GB的语料库数据摘要
| 句子 | 独特的单词 | 尺寸 | 令牌大小 | |
|---|---|---|---|---|
| 火车 | 263134203 | 52206886 | 39.9GB | 6000436472 |
使用生成的语料库,我们从头开始预先培训的Electra-Mall模型。该模型在RTX 2080 Ti GPU上进行了训练。
| 模型 | 层 | 隐藏尺寸 | 参数 |
|---|---|---|---|
| Electra-small | 12 | 256 | 14m |
对于17GB
线数:111332331
单词数(令牌):2538210492
该型号花了6天12小时才能训练
| 公制 | 价值 |
|---|---|
| DISC_ACCURACY | 0.9456 |
| DISC_AUC | 0.9256 |
| DISC_LOSS | 0.154 |
| disc_precision | 0.7832 |
| disc_recall | 0.4545 |
| 损失 | 10.45 |
| masked_lm_accuracy | 0.5168 |
| masked_lm_loss | 2.776 |
| Sampled_masked_lm_accuracy | 0.4135 |
对于39GB,词汇尺寸为30.5k
线数:263134203
单词数(令牌):6000436472
该型号花了5天9小时才能训练
| 公制 | 价值 |
|---|---|
| DISC_ACCURACY | 0.943 |
| DISC_AUC | 0.9184 |
| DISC_LOSS | 0.1609 |
| disc_precision | 0.7718 |
| disc_recall | 0.4153 |
| 损失 | 10.72 |
| masked_lm_accuracy | 0.5218 |
| masked_lm_loss | 2.7 |
| Sampled_masked_lm_accuracy | 0.4177 |
对于39GB,词汇尺寸为64k
线数:263134203
单词数(令牌):6000436472
该型号花了6天12小时才能训练
| 公制 | 价值 |
|---|---|
| DISC_ACCURACY | 0.9453 |
| DISC_AUC | 0.9278 |
| DISC_LOSS | 0.1534 |
| disc_precision | 0.7788 |
| disc_recall | 0.4655 |
| 损失 | 10.48 |
| masked_lm_accuracy | 0.5095 |
| masked_lm_loss | 2.82 |
| Sampled_masked_lm_accuracy | 0.4066 |
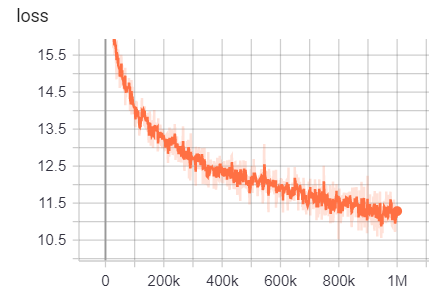
为了
| 模型/超参数 | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-small | 1m | 64000 | 128 |
可以在此处访问培训结果:
https://tensorboard.dev/experiment/g9pkbfzaqeacr7dgw2uljq/#scalars https://tensorboard.dev/experiment/qu1bq0mirgocgqbzbzhqs2ta/#scalars
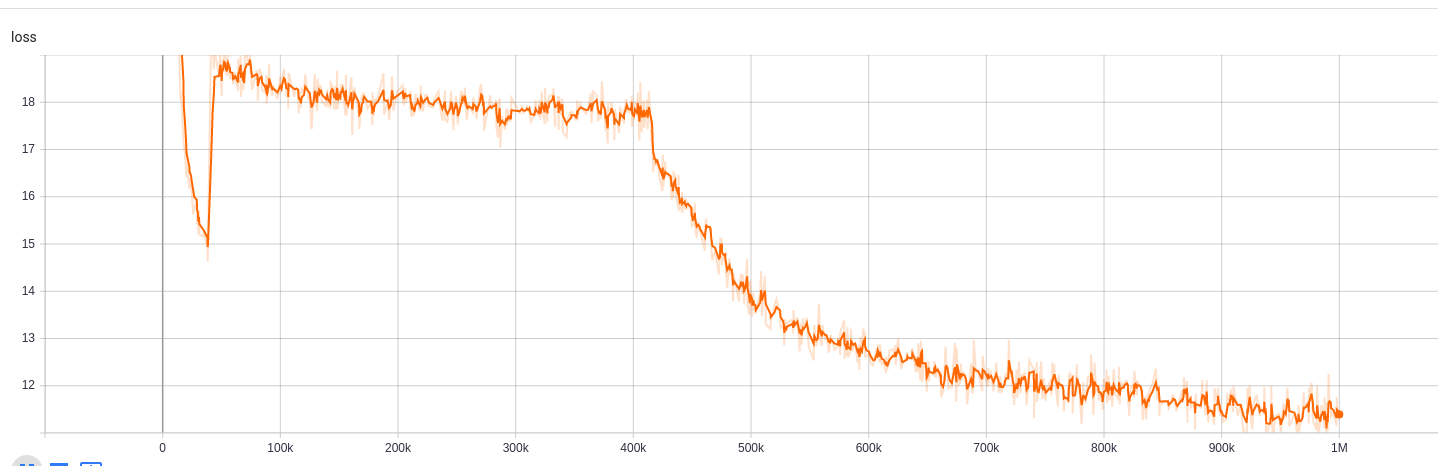
为了
| 模型/超参数 | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-small | 1m | 30522 | 128 |
可以在此处访问培训结果:
https://tensorboard.dev/experiment/npyu6mkhrmgoyd8kdsqw5w/#scalars https://tensorboard.dev/experiment/zqbeq7zjsdyijs5jb8ov3g/#scalars
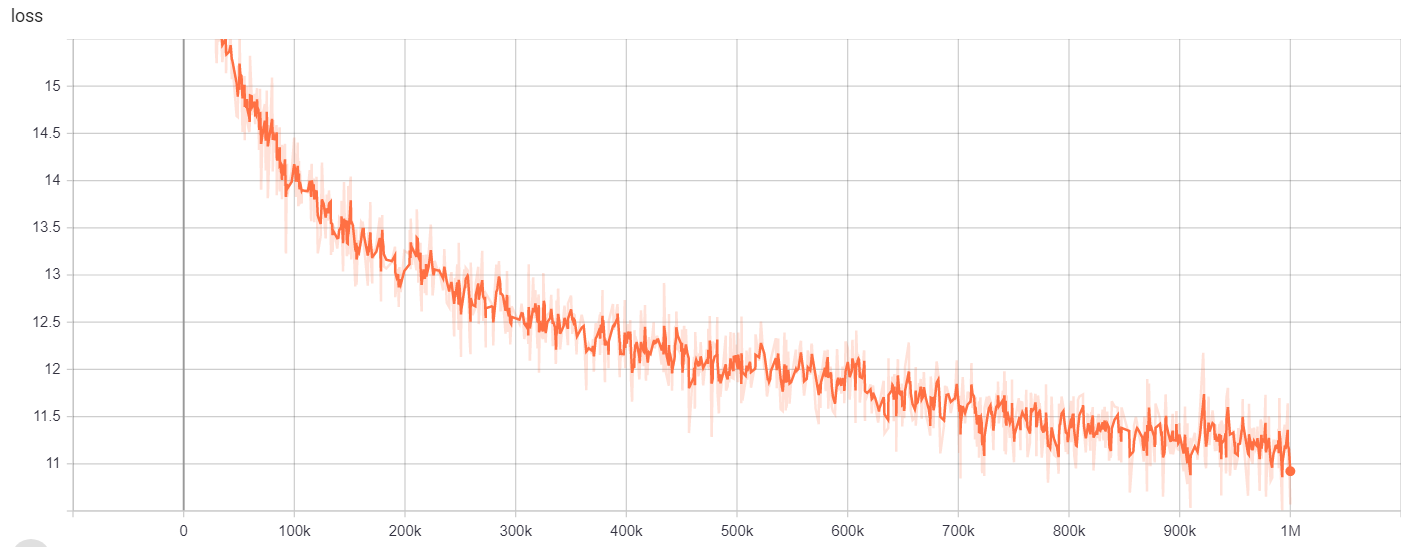
为了
| 模型/超参数 | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-small | 1m | 64000 | 128 |
可以在此处访问培训结果:
https://tensorboard.dev/experiment/gc51rmhdtgmj7eq0uyuavw/#scalars https://tensorboard.dev/experiment/q66kfo3lqtwk1kykgjcyyg/#scalars
对于命名的实体识别,我们使用了NCBI-Disese Copus,这是PubMed发表的疾病名称识别的资源。
| 模型 | F1 | 损失 | 准确性 | 精确 | 记起 |
|---|---|---|---|---|---|
| ENELPI/MED-ELECTRA-SMALL-DISCINETOR | 0.8462 | 0.0545 | 0.9827 | 0.8052 | 0.8462 |
| Google/Electra-Small-Disciminator | 0.8294 | 0.0640 | 0.9806 | 0.7998 | 0.8614 |
| Google/electra-base-cissiminator | 0.8580 | 0.0675 | 0.9835 | 0.8446 | 0.8718 |
| 大型基于基础 | 0.8348 | 0.0832 | 0.9815 | 0.8126 | 0.8583 |
| Distilroberta-bas | 0.8416 | 0.0828 | 0.9808 | 0.8207 | 0.8635 |
| 模型 | F1 | 损失 | 准确性 | 精确 | 记起 |
|---|---|---|---|---|---|
| ENELPI/MED-ELECTRA-SMALL-DISCINETOR | 0.8425 | 0.0545 | 0.9824 | 0.8028 | 0.8864 |
| Google/Electra-Small-Disciminator | 0.8280 | 0.0642 | 0.9807 | 0.7961 | 0.8625 |
| Google/electra-base-cissiminator | 0.8648 | 0.0682 | 0.9838 | 0.8442 | 0.8864 |
| 大型基于基础 | 0.8373 | 0.0806 | 0.9814 | 0.8153 | 0.8604 |
| Distilroberta-bas | 0.8329 | 0.0811 | 0.9801 | 0.8100 | 0.8572 |
| 模型 | F1 | 损失 | 准确性 | 精确 | 记起 |
|---|---|---|---|---|---|
| ENELPI/MED-ELECTRA-SMALL-DISCINETOR | 0.8463 | 0.0559 | 0.9823 | 0.8071 | 0.8895 |
| Google/Electra-Small-Disciminator | 0.8280 | 0.0691 | 0.9806 | 0.8025 | 0.8552 |
| Google/electra-base-cissiminator | 0.8542 | 0.0645 | 0.9840 | 0.8307 | 0.8791 |
| 大型基于基础 | 0.8424 | 0.0799 | 0.9822 | 0.8251 | 0.8604 |
| Distilroberta-bas | 0.8339 | 0.0924 | 0.9806 | 0.8136 | 0.8552 |
对于回答任务,我们使用了BioASQ问题数据集。
| 模型 | sacc | lacc |
|---|---|---|
| Enelpi/Med-Electra-Small-Disciminator-128 | 0.2821 | 0.4359 |
| Google/Electra-Small-Disciminator-128 | 0.3077 | 0.5128 |
| Enelpi/Med-Electra-Small-Disciminator-512 | 0.1538 | 0.3590 |
| Google/Electra-Small-Discisiminator-512 | 0.2564 | 0.5128 |
您可以从YouTube访问演示视频。 https://www.youtube.com/watch?v=fao9clyfldc&list=plhnxo6hzwbglge_iywgyxnmpz-3pgpggt&index=2
https://github.com/google-research/electra https://chriskhanhanhtran.github.io/_posts/2020-06-11-Electra-spanish/s-panish/https:/ https://github.com/github.com/github.com/allenai/allenai/allenai/sallenai/s2orc https :/ https://github.com/abachaa/medquad https://www.ncbi.nlm.nih.gov/pmc/articles/pmc5530755/pmc5530755/ https://github.com/lasseregin/medical-question-swer-data https://huggingface.co/blog/how-the-train-train https://arxiv.org/abs/1909.09.06146 https:/


