Medical Electra
1.0.0
الإجابة على الأسئلة (QA) هي حقل في معالجة اللغة الطبيعية (NLP) واسترجاع المعلومات (IR). تهدف مهمة QA بشكل أساسي إلى إعطاء إجابات دقيقة وسريعة للأسئلة المعطاة باللغات الطبيعية باستخدام البيانات أو قواعد البيانات المعطاة. في هذا المشروع ، تعاملنا مع مشكلة الإجابة على الأسئلة على الأوراق الطبية. هناك الكثير من نماذج اللغة المنشورة ومتاحة لاستخدامها لمهمة الإجابة على الأسئلة. في هذا المشروع ، أردنا تطوير نموذج لغة ، تم تدريبه على وجه التحديد على المجال الطبي. هدفنا هو تطوير نموذج لغة محدد للسياق على الأوراق الطبية ، ويعزف نماذج اللغة العامة بشكل أفضل. استخدمنا Electra-Small كنموذج أساسي لدينا ، وقمنا بتدريبه باستخدام مجموعة بيانات الورق الطبية ، ثم تم ضبطها على مجموعة بيانات QA الطبية. قمنا بتدريب ثلاثة نماذج مختلفة ، وقارنا نتائجها على مهام NLP المصب.
يمكنك الوصول إلى نماذجنا هنا:
Med-Electra Small Model 17GB-64K VOCAB
Med-Electra Small Model 39GB-30.5K VOCAB
Med-Electra Small Model 39GB-64K VOCAB
استخدمنا الأوراق الطبية S2ORC. قمنا بتصفية قاعدة بيانات S2ORC باستخدام مجال الدراسة ، واستغرقنا الأوراق الطبية. استخدمنا مجموعتين مختلفتين ، يتكون من شظايا ، أخذنا 11 شظية لمجموعة بيانات 17 جيجابايت ، واستخدمنا 26 شظية لمجموعة بيانات 39 جيجابايت. بعد ذلك ، أخذنا تلك التي يتم نشرها على PubMed و PubMedCenterral. استخدمنا فقط PDF_Parses لتلك الأوراق ، لأن الجمل في PDF_Parses تحتوي على مزيد من المعلومات.
{
"section": "Introduction",
"text": "Dogs are happier cats [13, 15]. See Figure 3 for a diagram.",
"cite_spans": [
{"start": 22, "end": 25, "text": "[13", "ref_id": "BIBREF11"},
{"start": 27, "end": 30, "text": "15]", "ref_id": "BIBREF30"},
...
],
"ref_spans": [
{"start": 36, "end": 44, "text": "Figure 3", "ref_id": "FIGREF2"},
]
}
{
...,
"BIBREF11": {
"title": "Do dogs dream of electric humans?",
"authors": [
{"first": "Lucy", "middle": ["Lu"], "last": "Wang", "suffix": ""},
{"first": "Mark", "middle": [], "last": "Neumann", "suffix": "V"}
],
"year": "",
"venue": "barXiv",
"link": null
},
...
}
{
"TABREF4": {
"text": "Table 5. Clearly, we achieve SOTA here or something.",
"type": "table"
}
...,
"FIGREF2": {
"text": "Figure 3. This is the caption of a pretty figure.",
"type": "figure"
},
...
}
}
ملخص بيانات Corpus لـ 17 جيجابايت
| جملة | كلمات فريدة | مقاس | حجم الرمز المميز | |
|---|---|---|---|---|
| يدرب | 111537350 | 27609654 | 16.9 جيجا بايت | 2538210492 |
ملخص بيانات Corpus لـ 39 جيجابايت
| جملة | كلمات فريدة | مقاس | حجم الرمز المميز | |
|---|---|---|---|---|
| يدرب | 263134203 | 52206886 | 39.9 جيجابايت | 6000436472 |
باستخدام المجموعة التي تم إنشاؤها ، قمنا بتدريب نموذج Electra-Small مسبقًا من الصفر. تم تدريب النموذج على RTX 2080 TI GPU.
| نموذج | طبقات | الحجم المخفي | حدود |
|---|---|---|---|
| Electra-Small | 12 | 256 | 14m |
ل 17 جيجابايت
عدد الخطوط: 111332331
عدد الكلمات (الرموز): 2538210492
استغرق هذا النموذج 6 أيام 12 ساعة للتدريب
| متري | قيمة |
|---|---|
| DISC_ACCURACY | 0.9456 |
| DISC_AUC | 0.9256 |
| DISC_LOSS | 0.154 |
| DISC_PRECISION | 0.7832 |
| disc_recall | 0.4545 |
| خسارة | 10.45 |
| masked_lm_accuracy | 0.5168 |
| Masked_lm_loss | 2.776 |
| sampled_masked_lm_accuracy | 0.4135 |
مقابل 39 جيجابايت مع حجم المفردات 30.5k
عدد الخطوط: 263134203
عدد الكلمات (الرموز): 6000436472
استغرق هذا النموذج 5 أيام 9 ساعات للتدريب
| متري | قيمة |
|---|---|
| DISC_ACCURACY | 0.943 |
| DISC_AUC | 0.9184 |
| DISC_LOSS | 0.1609 |
| DISC_PRECISION | 0.7718 |
| disc_recall | 0.4153 |
| خسارة | 10.72 |
| masked_lm_accuracy | 0.5218 |
| Masked_lm_loss | 2.7 |
| sampled_masked_lm_accuracy | 0.4177 |
مقابل 39 جيجابايت مع حجم المفردات 64k
عدد الخطوط: 263134203
عدد الكلمات (الرموز): 6000436472
استغرق هذا النموذج 6 أيام 12 ساعة للتدريب
| متري | قيمة |
|---|---|
| DISC_ACCURACY | 0.9453 |
| DISC_AUC | 0.9278 |
| DISC_LOSS | 0.1534 |
| DISC_PRECISION | 0.7788 |
| disc_recall | 0.4655 |
| خسارة | 10.48 |
| masked_lm_accuracy | 0.5095 |
| Masked_lm_loss | 2.82 |
| sampled_masked_lm_accuracy | 0.4066 |
ل
| النموذج/hyperparameters | Train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-Small | 1M | 64000 | 128 |
يمكن الوصول إلى نتائج التدريب هنا:
https://tensorboard.dev/experiment/g9pkbfzaqeacr7dgw2uljq/#scalars
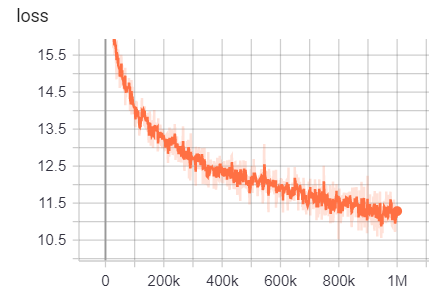
ل
| النموذج/hyperparameters | Train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-Small | 1M | 30522 | 128 |
يمكن الوصول إلى نتائج التدريب هنا:
https://tensorboard.dev/experiment/npyu6mkhrmgoyd8kdsqw5w/#scalars
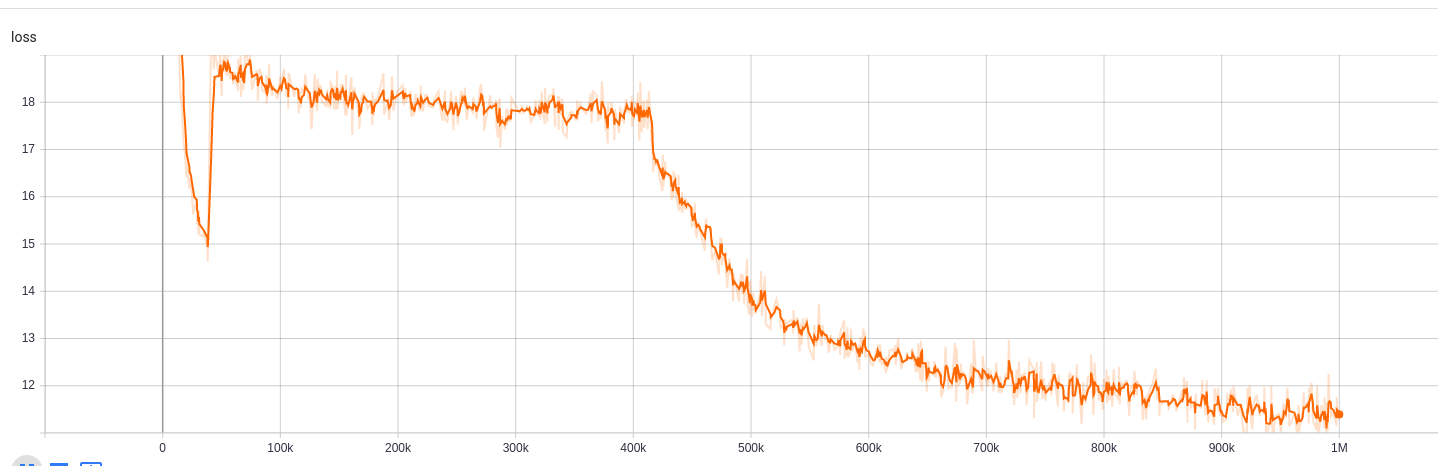
ل
| النموذج/hyperparameters | Train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-Small | 1M | 64000 | 128 |
يمكن الوصول إلى نتائج التدريب هنا:
https://tensorboard.dev/experiment/gc51rmhdtgmjj7eq0uyuavw/#scalars https://tensorboard.dev/experiment/q66kfo3lqtwk1kekgjcyyg/#scalars
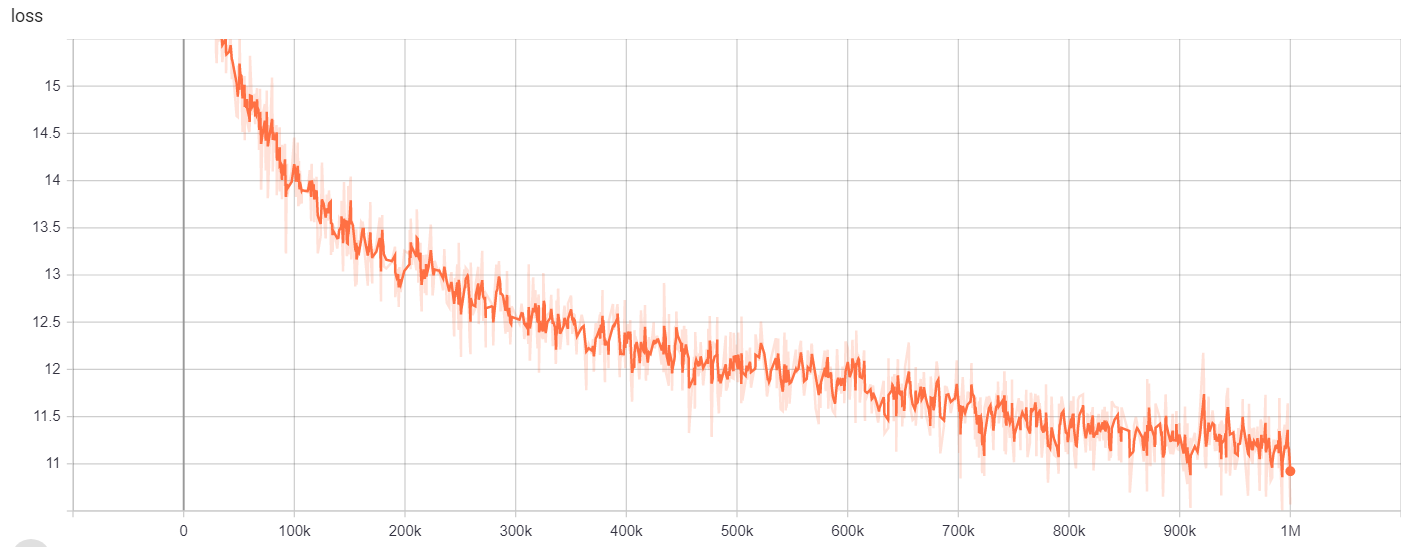
للتعرف على الكيان المسماة ، استخدمنا NCBI-Imease Corpus ، وهو مورد للتعرف على اسم المرض المنشور في PubMed.
| نموذج | F1 | خسارة | دقة | دقة | يتذكر |
|---|---|---|---|---|---|
| enelpi/med-electra-small-discriminator | 0.8462 | 0.0545 | 0.9827 | 0.8052 | 0.8462 |
| Google/Electra-Small-Discriminator | 0.8294 | 0.0640 | 0.9806 | 0.7998 | 0.8614 |
| Google/Electra-base-discriminator | 0.8580 | 0.0675 | 0.9835 | 0.8446 | 0.8718 |
| distilbert-base-uncared | 0.8348 | 0.0832 | 0.9815 | 0.8126 | 0.8583 |
| Distilroberta-base | 0.8416 | 0.0828 | 0.9808 | 0.8207 | 0.8635 |
| نموذج | F1 | خسارة | دقة | دقة | يتذكر |
|---|---|---|---|---|---|
| enelpi/med-electra-small-discriminator | 0.8425 | 0.0545 | 0.9824 | 0.8028 | 0.8864 |
| Google/Electra-Small-Discriminator | 0.8280 | 0.0642 | 0.9807 | 0.7961 | 0.8625 |
| Google/Electra-base-discriminator | 0.8648 | 0.0682 | 0.9838 | 0.8442 | 0.8864 |
| distilbert-base-uncared | 0.8373 | 0.0806 | 0.9814 | 0.8153 | 0.8604 |
| Distilroberta-base | 0.8329 | 0.0811 | 0.9801 | 0.8100 | 0.8572 |
| نموذج | F1 | خسارة | دقة | دقة | يتذكر |
|---|---|---|---|---|---|
| enelpi/med-electra-small-discriminator | 0.8463 | 0.0559 | 0.9823 | 0.8071 | 0.8895 |
| Google/Electra-Small-Discriminator | 0.8280 | 0.0691 | 0.9806 | 0.8025 | 0.8552 |
| Google/Electra-base-discriminator | 0.8542 | 0.0645 | 0.9840 | 0.8307 | 0.8791 |
| Distilbert-base-uncared | 0.8424 | 0.0799 | 0.9822 | 0.8251 | 0.8604 |
| distilroberta-base | 0.8339 | 0.0924 | 0.9806 | 0.8136 | 0.8552 |
لمهمة الإجابة على الأسئلة ، استخدمنا مجموعة بيانات أسئلة BioAsq.
| نموذج | SACC | LACC |
|---|---|---|
| enelpi/med-electra-small-discriminator-128 | 0.2821 | 0.4359 |
| Google/Electra-Small-Discriminator-128 | 0.3077 | 0.5128 |
| enelpi/med-electra-small-discriminator-512 | 0.1538 | 0.3590 |
| Google/Electra-Small-Discriminator-512 | 0.2564 | 0.5128 |
يمكنك الوصول إلى فيديو العرض التقديمي من YouTube. https://www.youtube.com/watch؟v=fao9clyfldc&list=plhnxo6hzwbglge_iywgyxnmpz-3pgpggt&index=2
https://github.com/google-research/electra https://chriskhanhtran.github.io/_posts https://github.com/abachaa/medquad https://www.ncbi.nlm.nih.gov/pmc/articles/pmc5530755/ https://pubmed.ncbi.nlm.nih.gov/24393765/ https://github.com/lassergin/medical-question-answer-data https://huggingface.co/blog/how-to--train https://arxiv.org/abs/1909.06146


