Medical Electra
1.0.0
Ответ на вопрос (QA) - это поле в обработке естественного языка (NLP) и поиску информации (IR). QA Задача в основном направлена на то, чтобы дать точные и быстрые ответы на заданный вопрос на естественных языках, используя заданные данные или базы данных. В этом проекте мы решали проблему вопроса, отвечающего на медицинские документы. Есть много языковых моделей, опубликованных и доступных для использования для вопросов, отвечающих на задачу. В этом проекте мы хотели разработать языковую модель, специально обученную на области медицины. Наша цель состоит в том, чтобы разработать специфичную для контекста языковую модель в медицинских работах, работает лучше, чем общие языковые модели. Мы использовали Electra-Small в качестве нашей базовой модели и обучили ее, используя набор данных по медицинской бумаге, а затем настраиваясь на наборе данных медицинского QA. Мы обучили три разных моделя и сравнили их результаты по задачам NLP вниз по течению.
Вы можете получить доступ к нашим моделям здесь:
Med-Electra Small Model 17 ГБ-64K Vocab https://huggingface.co/enelpi/med-electra-small-discriminator
Med-Electra Small Model 39 ГБ-30,5K Vocab https://huggingface.co/enelpi/med-eletretra-small-30k-discriminator
Med-Electra Small Model 39 ГБ-64K Vocab https://huggingface.co/enelpi/med-electra-small-64k-driscriminator
Мы использовали медицинские документы S2ORC. Мы отфильтровали базу данных S2ORC, используя полевые исследования, и взяли медицинские рабочие документы. Мы использовали два разных набора данных, состоит из осколков, мы взяли 11 осколков для набора данных 17 ГБ и использовали 26 осколков для набора данных 39 ГБ. После этого мы взяли те, которые опубликованы на PubMed и PubmedCentral. Мы использовали только pdf_parses этих документов, поскольку предложения в PDF_PARSES содержит больше информации.
{
"section": "Introduction",
"text": "Dogs are happier cats [13, 15]. See Figure 3 for a diagram.",
"cite_spans": [
{"start": 22, "end": 25, "text": "[13", "ref_id": "BIBREF11"},
{"start": 27, "end": 30, "text": "15]", "ref_id": "BIBREF30"},
...
],
"ref_spans": [
{"start": 36, "end": 44, "text": "Figure 3", "ref_id": "FIGREF2"},
]
}
{
...,
"BIBREF11": {
"title": "Do dogs dream of electric humans?",
"authors": [
{"first": "Lucy", "middle": ["Lu"], "last": "Wang", "suffix": ""},
{"first": "Mark", "middle": [], "last": "Neumann", "suffix": "V"}
],
"year": "",
"venue": "barXiv",
"link": null
},
...
}
{
"TABREF4": {
"text": "Table 5. Clearly, we achieve SOTA here or something.",
"type": "table"
}
...,
"FIGREF2": {
"text": "Figure 3. This is the caption of a pretty figure.",
"type": "figure"
},
...
}
}
Краткое составление данных корпуса для 17 ГБ
| Предложение | Уникальные слова | Размер | Размер токена | |
|---|---|---|---|---|
| Тренироваться | 111537350 | 27609654 | 16,9 ГБ | 2538210492 |
Корпусная сводка данных для 39 ГБ
| Предложение | Уникальные слова | Размер | Размер токена | |
|---|---|---|---|---|
| Тренироваться | 263134203 | 52206886 | 39,9 ГБ | 6000436472 |
Используя сгенерированный корпус, мы предварительно обучили модель Electra-Small с нуля. Модель обучается на графическом процессоре RTX 2080 TI.
| Модель | Слои | Скрытый размер | Параметры |
|---|---|---|---|
| Электра-Смалл | 12 | 256 | 14 м |
Для 17 ГБ
Количество строк: 111332331
Количество слов (токены): 2538210492
Эта модель заняла 6 дней 12 часов, чтобы тренироваться
| Показатель | Ценить |
|---|---|
| Disc_accuracy | 0,9456 |
| disc_auc | 0,9256 |
| disc_loss | 0,154 |
| Disc_precision | 0,7832 |
| Disc_recall | 0,4545 |
| потеря | 10.45 |
| Masked_lm_accuracy | 0,5168 |
| Masked_lm_loss | 2.776 |
| SAMPLED_MASKED_LM_ACCURACY | 0,4135 |
Для 39 ГБ с размером словарной 30,5 тыс.
Количество строк: 263134203
Количество слов (токены): 6000436472
Эта модель заняла 5 дней 9 часов, чтобы тренироваться
| Показатель | Ценить |
|---|---|
| Disc_accuracy | 0,943 |
| disc_auc | 0,9184 |
| disc_loss | 0,1609 |
| Disc_precision | 0,7718 |
| Disc_recall | 0,4153 |
| потеря | 10.72 |
| Masked_lm_accuracy | 0,5218 |
| Masked_lm_loss | 2.7 |
| SAMPLED_MASKED_LM_ACCURACY | 0,4177 |
Для 39 ГБ с 64 -километровым словарным размером
Количество строк: 263134203
Количество слов (токены): 6000436472
Эта модель заняла 6 дней 12 часов, чтобы тренироваться
| Показатель | Ценить |
|---|---|
| Disc_accuracy | 0,9453 |
| disc_auc | 0,9278 |
| disc_loss | 0,1534 |
| Disc_precision | 0,7788 |
| Disc_recall | 0,4655 |
| потеря | 10.48 |
| Masked_lm_accuracy | 0,5095 |
| Masked_lm_loss | 2.82 |
| SAMPLED_MASKED_LM_ACCURACY | 0,4066 |
Для
| Модель/гиперпараметры | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Электра-Смалл | 1 м | 64000 | 128 |
Результаты обучения можно получить здесь:
https://tensorboard.dev/experiment/g9pkbfzaqeacr7dgw2uljq/#scalars https://tensorboard.dev/experiment/qu1bq0mirgocgqbzhqs2ta/#scalars
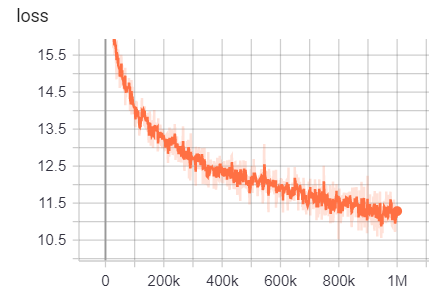
Для
| Модель/гиперпараметры | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Электра-Смалл | 1 м | 30522 | 128 |
Результаты обучения можно получить здесь:
https://tensorboard.dev/experiment/npyu6mkhrmgoyd8kdsqw5w/#scalars https://tensorboard.dev/experiment/zqbeq7zjsdyijs5jb8ov3g/#scalars
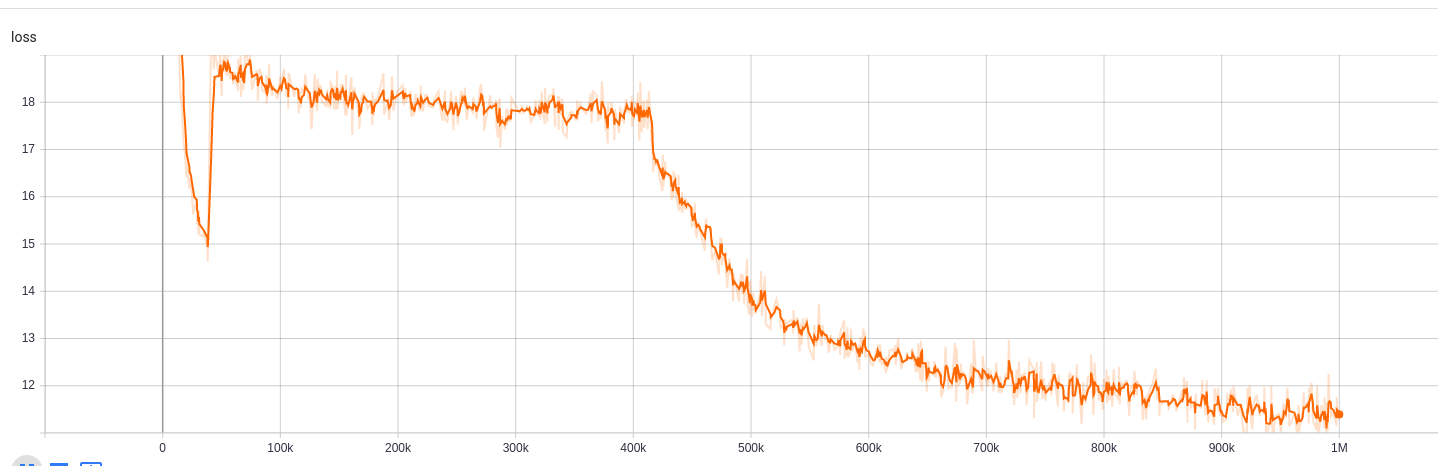
Для
| Модель/гиперпараметры | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Электра-Смалл | 1 м | 64000 | 128 |
Результаты обучения можно получить здесь:
https://tensorboard.dev/experiment/gc51rmhdtgmj7eq0uyuavw/#scalars https://tensorboard.dev/experiment/q66kfo3lqtwk1kykgjcyyg/#scalars
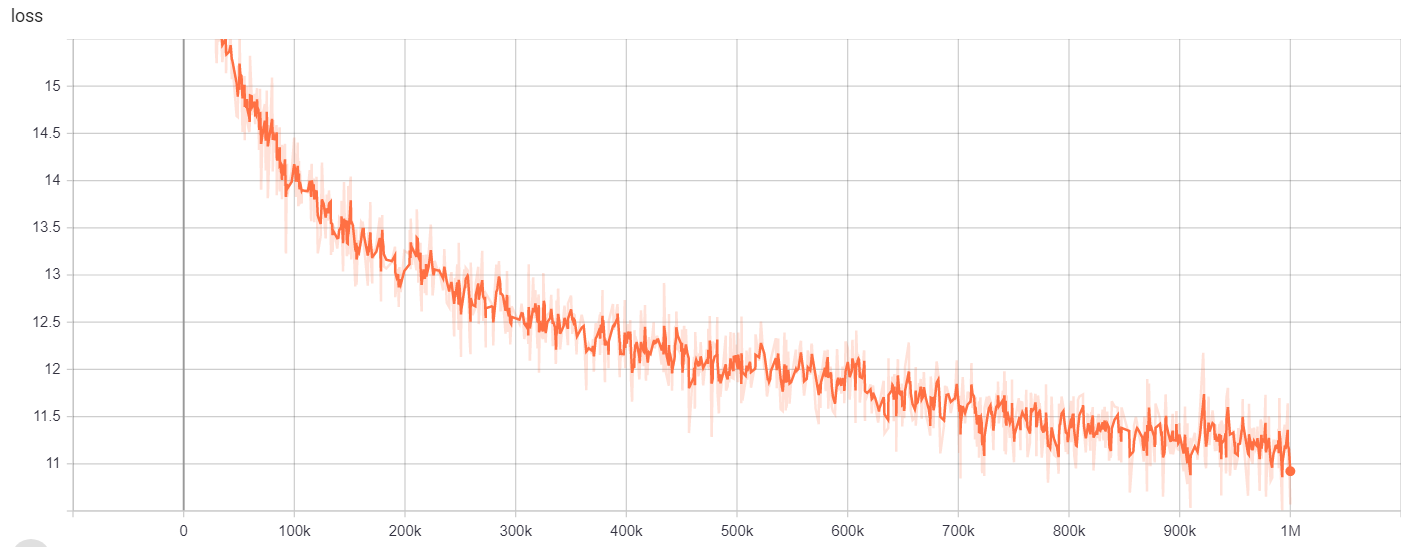
Для признания названного организации мы использовали корпус NCBI-Disease, который является ресурсом для распознавания имени болезни, опубликованной в PubMed.
| Модель | F1 | Потеря | точность | точность | отзывать |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-дискриминатор | 0,8462 | 0,0545 | 0,9827 | 0,8052 | 0,8462 |
| Google/Electra-Small-Discriminator | 0,8294 | 0,0640 | 0,9806 | 0,7998 | 0,8614 |
| Google/Electra-Base-Дискриминатор | 0,8580 | 0,0675 | 0,9835 | 0,8446 | 0,8718 |
| Дистильберт-базовый | 0,8348 | 0,0832 | 0,9815 | 0,8126 | 0,8583 |
| Distilroberta-Base | 0,8416 | 0,0828 | 0,9808 | 0,8207 | 0,8635 |
| Модель | F1 | Потеря | точность | точность | отзывать |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-дискриминатор | 0,8425 | 0,0545 | 0,9824 | 0,8028 | 0,8864 |
| Google/Electra-Small-Discriminator | 0,8280 | 0,0642 | 0,9807 | 0,7961 | 0,8625 |
| Google/Electra-Base-Дискриминатор | 0,8648 | 0,0682 | 0,9838 | 0,8442 | 0,8864 |
| Дистильберт-базовый | 0,8373 | 0,0806 | 0,9814 | 0,8153 | 0,8604 |
| Distilroberta-Base | 0,8329 | 0,0811 | 0,9801 | 0,8100 | 0,8572 |
| Модель | F1 | Потеря | точность | точность | отзывать |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-дискриминатор | 0,8463 | 0,0559 | 0,9823 | 0,8071 | 0,8895 |
| Google/Electra-Small-Discriminator | 0,8280 | 0,0691 | 0,9806 | 0,8025 | 0,8552 |
| Google/Electra-Base-Дискриминатор | 0,8542 | 0,0645 | 0,9840 | 0,8307 | 0,8791 |
| Дистильберт-базовый | 0,8424 | 0,0799 | 0,9822 | 0,8251 | 0,8604 |
| Distilroberta-Base | 0,8339 | 0,0924 | 0,9806 | 0,8136 | 0,8552 |
Для вопроса ответа на задание мы использовали набор данных вопросов BioASQ.
| Модель | Сакк | LACC |
|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator-128 | 0,2821 | 0,4359 |
| Google/Electra-Small-Discriminator-128 | 0,3077 | 0,5128 |
| Enelpi/Med-Electra-Small-Discriminator-512 | 0,1538 | 0,3590 |
| Google/Electra-Small-Discriminator-512 | 0,2564 | 0,5128 |
Вы можете получить доступ к видео с презентацией с YouTube. https://www.youtube.com/watch?v=fao9clyfldc&list=plhnxo6hzwbglge_iywgyxnmpz-3pgpggt&index=2
https://github.com/google-research/electra https://chriskhanhtran.github.io/_posts/2020-06-11-electra-panish/ https://github.com/allenai/s2orc https://github.com/allenai/scert https://github.com/abachaa/medquad https://www.ncbi.nlm.nih.gov/pmc/articles/pmc5550755/ https://pubmed.ncbi.nlm.nih.gov/24393765/ne https://github.com/lasseregin/medical-question-answer-data https://huggingface.co/blog/how-to-train https://arxiv.org/abs/1909.06146 https://www.nlm.nih.gov/databasebasemline/pamline_pamline_pamline_pamline_pamline_pamline_pamline_pamline_pamlicer


