Medical Electra
1.0.0
질문 답변 (QA)은 자연어 처리 (NLP) 및 정보 검색 (IR)의 분야입니다. QA 작업은 기본적으로 주어진 데이터 또는 데이터베이스를 사용하여 자연어로 주어진 질문에 대한 정확하고 빠른 답변을 제공하는 것을 목표로합니다. 이 프로젝트에서 우리는 의료 서류에 대한 질문의 문제를 해결했습니다. 질문 응답 과제를 위해 많은 언어 모델이 게시되어 사용할 수 있습니다. 이 프로젝트에서 우리는 의료 분야에서 특히 교육을받은 언어 모델을 개발하고 싶었습니다. 우리의 목표는 의료 논문에 대한 맥락 별 언어 모델을 개발하고 일반 언어 모델보다 더 잘 수행하는 것입니다. 우리는 Electra-Small을 기본 모델로 사용하고 의료 용지 데이터 세트를 사용하여 교육을받은 다음 의료 QA 데이터 세트에서 미세 조정했습니다. 우리는 세 가지 모델을 훈련시키고 NLP 다운 스트림 작업에서 결과를 비교했습니다.
여기에서 모델에 액세스 할 수 있습니다.
Med-Electra Small Model 17GB-64K Vocab https://huggingface.co/enelpi/med-electra-small-discriminator
Med-Electra Small Model 39GB-30.5K Vocab https://huggingface.co/enelpi/med-electra-small-30k-discriminator
Med-Electra Small Model 39GB-64K Vocab https://huggingface.co/enelpi/med-electra-small-64k-discriminator
우리는 의료 서류 S2ORC를 사용했습니다. 연구 분야를 사용하여 S2ORC 데이터베이스를 필터링하고 의료 서류를 가져갔습니다. 우리는 두 가지 다른 데이터 세트를 사용하고 파편으로 구성되며 17GB 데이터 세트에 11 개의 파편을 가져 갔으며 39GB 데이터 세트에 26 개의 파편을 사용했습니다. 그 후, 우리는 PubMed와 PubMedcentral에 출판 된 것을 가져갔습니다. PDF_PARSES의 문장에는 더 많은 정보가 포함되어 있기 때문에 해당 논문의 PDF_PARSES 만 사용했습니다.
{
"section": "Introduction",
"text": "Dogs are happier cats [13, 15]. See Figure 3 for a diagram.",
"cite_spans": [
{"start": 22, "end": 25, "text": "[13", "ref_id": "BIBREF11"},
{"start": 27, "end": 30, "text": "15]", "ref_id": "BIBREF30"},
...
],
"ref_spans": [
{"start": 36, "end": 44, "text": "Figure 3", "ref_id": "FIGREF2"},
]
}
{
...,
"BIBREF11": {
"title": "Do dogs dream of electric humans?",
"authors": [
{"first": "Lucy", "middle": ["Lu"], "last": "Wang", "suffix": ""},
{"first": "Mark", "middle": [], "last": "Neumann", "suffix": "V"}
],
"year": "",
"venue": "barXiv",
"link": null
},
...
}
{
"TABREF4": {
"text": "Table 5. Clearly, we achieve SOTA here or something.",
"type": "table"
}
...,
"FIGREF2": {
"text": "Figure 3. This is the caption of a pretty figure.",
"type": "figure"
},
...
}
}
17GB에 대한 코퍼스 데이터 요약
| 문장 | 독특한 단어 | 크기 | 토큰 크기 | |
|---|---|---|---|---|
| 기차 | 111537350 | 27609654 | 16.9GB | 2538210492 |
39GB에 대한 코퍼스 데이터 요약
| 문장 | 독특한 단어 | 크기 | 토큰 크기 | |
|---|---|---|---|---|
| 기차 | 263134203 | 52206886 | 39.9GB | 6000436472 |
생성 된 코퍼스를 사용하여 전기 연습 모델을 처음부터 미리 훈련했습니다. 이 모델은 RTX 2080 TI GPU에 대한 교육을 받았습니다.
| 모델 | 레이어 | 숨겨진 크기 | 매개 변수 |
|---|---|---|---|
| 전자식 | 12 | 256 | 14m |
17GB의 경우
줄 수 : 111332331
단어 수 (토큰) : 2538210492
이 모델은 훈련하는 데 6 일이 걸렸습니다
| 메트릭 | 값 |
|---|---|
| disc_accuracy | 0.9456 |
| disc_auc | 0.9256 |
| disc_loss | 0.154 |
| disc_precision | 0.7832 |
| disc_recall | 0.4545 |
| 손실 | 10.45 |
| masked_lm_accuracy | 0.5168 |
| masked_lm_loss | 2.776 |
| sampled_masked_lm_accuracy | 0.4135 |
30.5k 어휘 크기의 39GB의 경우
라인 수 : 263134203
단어 수 (토큰) : 6000436472
이 모델은 훈련하는 데 9 시간이 걸렸습니다
| 메트릭 | 값 |
|---|---|
| disc_accuracy | 0.943 |
| disc_auc | 0.9184 |
| disc_loss | 0.1609 |
| disc_precision | 0.7718 |
| disc_recall | 0.4153 |
| 손실 | 10.72 |
| masked_lm_accuracy | 0.5218 |
| masked_lm_loss | 2.7 |
| sampled_masked_lm_accuracy | 0.4177 |
64K 어휘 크기의 39GB의 경우
라인 수 : 263134203
단어 수 (토큰) : 6000436472
이 모델은 훈련하는 데 6 일이 걸렸습니다
| 메트릭 | 값 |
|---|---|
| disc_accuracy | 0.9453 |
| disc_auc | 0.9278 |
| disc_loss | 0.1534 |
| disc_precision | 0.7788 |
| disc_recall | 0.4655 |
| 손실 | 10.48 |
| masked_lm_accuracy | 0.5095 |
| masked_lm_loss | 2.82 |
| sampled_masked_lm_accuracy | 0.4066 |
을 위한
| 모델/하이퍼 파라미터 | Train_steps | vocab_size | batch_size |
|---|---|---|---|
| 전자식 | 1m | 64000 | 128 |
교육 결과는 여기에서 액세스 할 수 있습니다.
https://tensorboard.dev/experiment/g9pkbfzaqeacr7dgw2uljq/#scalars https://tensorboard.dev/experiment/qu1bq0mirgocgqbzhqs2ta/#scalars
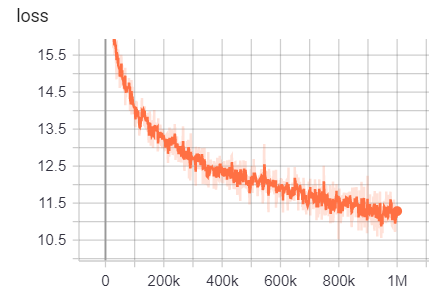
을 위한
| 모델/하이퍼 파라미터 | Train_steps | vocab_size | batch_size |
|---|---|---|---|
| 전자식 | 1m | 30522 | 128 |
교육 결과는 여기에서 액세스 할 수 있습니다.
https://tensorboard.dev/experiment/npyuu6mkhrmgoyd8kdsqw5w/#scalars https://tensorboard.dev/experiment/zqbeq7zsdyijs5jb8ov3g/#scalars
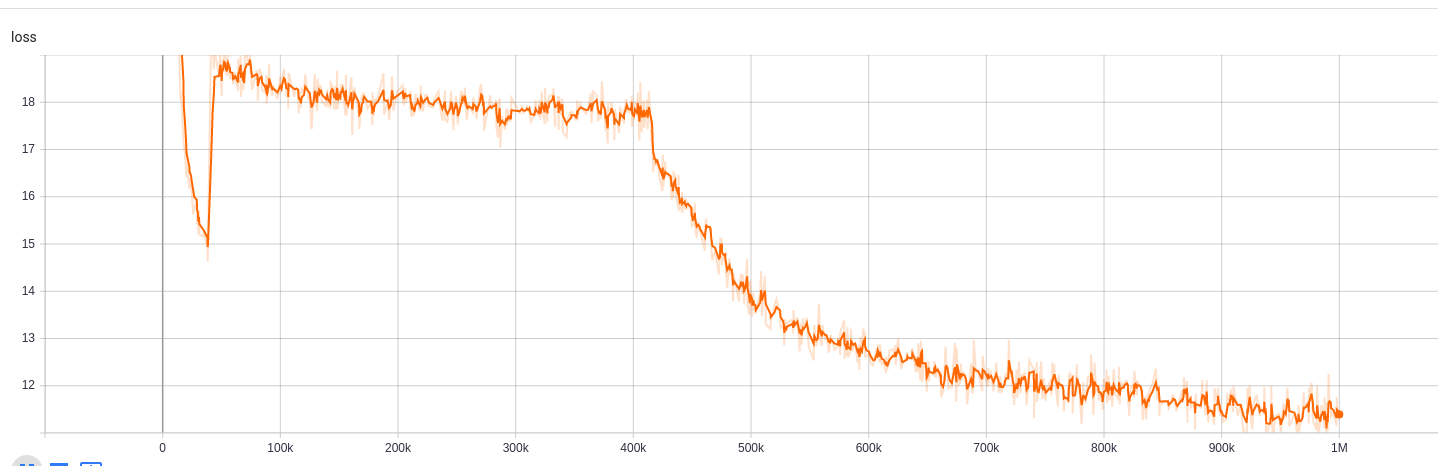
을 위한
| 모델/하이퍼 파라미터 | Train_steps | vocab_size | batch_size |
|---|---|---|---|
| 전자식 | 1m | 64000 | 128 |
교육 결과는 여기에서 액세스 할 수 있습니다.
https://tensorboard.dev/experiment/gc51rmhdtgmj7eq0uyuavw/#scalars https://tensorboard.dev/experiment/q66kfo3lqtwk1keykgjcyyg/#scalars
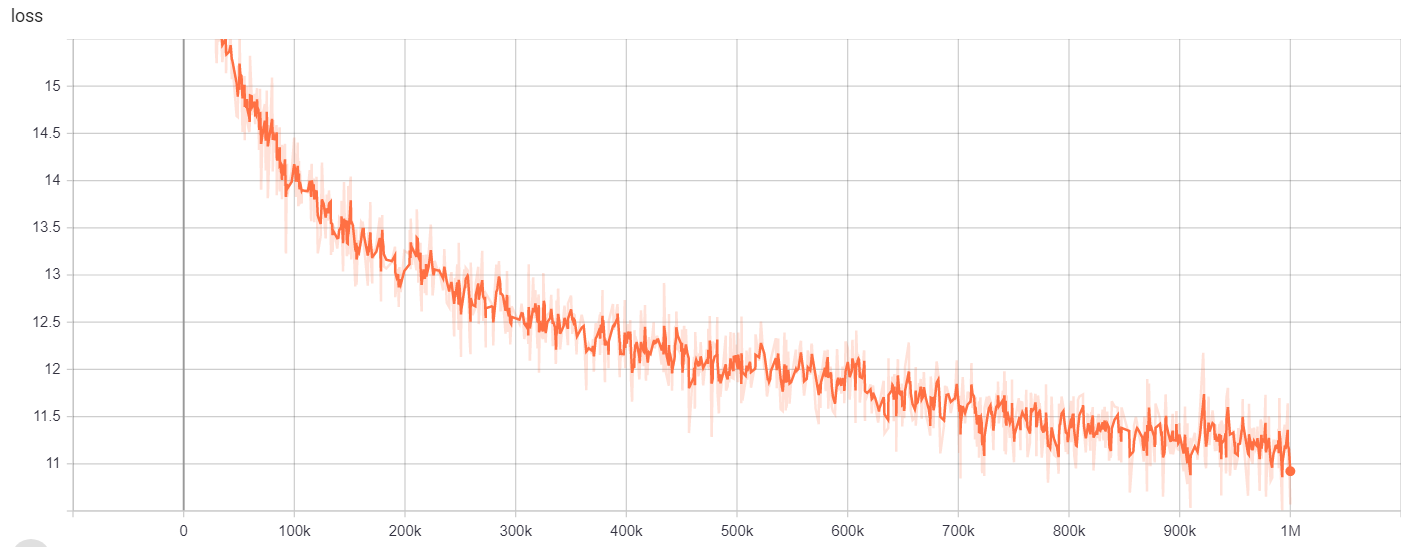
명명 된 엔티티 인식을 위해, 우리는 NCBI-Disease Corpus를 사용했는데, 이는 PubMed에 게시 된 질병 이름 인식 자원입니다.
| 모델 | F1 | 손실 | 정확성 | 정도 | 상기하다 |
|---|---|---|---|---|---|
| enelpi/med-electra-small-discriminator | 0.8462 | 0.0545 | 0.9827 | 0.8052 | 0.8462 |
| Google/Electra-Small-Discriminator | 0.8294 | 0.0640 | 0.9806 | 0.7998 | 0.8614 |
| Google/Electra-Base-Discriminator | 0.8580 | 0.0675 | 0.9835 | 0.8446 | 0.8718 |
| Distilbert-base-incased | 0.8348 | 0.0832 | 0.9815 | 0.8126 | 0.8583 |
| Distilroberta-base | 0.8416 | 0.0828 | 0.9808 | 0.8207 | 0.8635 |
| 모델 | F1 | 손실 | 정확성 | 정도 | 상기하다 |
|---|---|---|---|---|---|
| enelpi/med-electra-small-discriminator | 0.8425 | 0.0545 | 0.9824 | 0.8028 | 0.8864 |
| Google/Electra-Small-Discriminator | 0.8280 | 0.0642 | 0.9807 | 0.7961 | 0.8625 |
| Google/Electra-Base-Discriminator | 0.8648 | 0.0682 | 0.9838 | 0.8442 | 0.8864 |
| Distilbert-base-incased | 0.8373 | 0.0806 | 0.9814 | 0.8153 | 0.8604 |
| Distilroberta-base | 0.8329 | 0.0811 | 0.9801 | 0.8100 | 0.8572 |
| 모델 | F1 | 손실 | 정확성 | 정도 | 상기하다 |
|---|---|---|---|---|---|
| enelpi/med-electra-small-discriminator | 0.8463 | 0.0559 | 0.9823 | 0.8071 | 0.8895 |
| Google/Electra-Small-Discriminator | 0.8280 | 0.0691 | 0.9806 | 0.8025 | 0.8552 |
| Google/Electra-Base-Discriminator | 0.8542 | 0.0645 | 0.9840 | 0.8307 | 0.8791 |
| Distilbert-base-incased | 0.8424 | 0.0799 | 0.9822 | 0.8251 | 0.8604 |
| Distilroberta-base | 0.8339 | 0.0924 | 0.9806 | 0.8136 | 0.8552 |
질문 답변 작업을 위해 BioASQ 질문 데이터 세트를 사용했습니다.
| 모델 | SACC | LACC |
|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator-128 | 0.2821 | 0.4359 |
| Google/Electra-Small-Discriminator-128 | 0.3077 | 0.5128 |
| Enelpi/Med-Electra-Small-Discriminator-512 | 0.1538 | 0.3590 |
| Google/Electra-Small-Discriminator-512 | 0.2564 | 0.5128 |
YouTube에서 프레젠테이션 비디오에 액세스 할 수 있습니다. https://www.youtube.com/watch?v=fao9clyfldc&list=plhnxo6hzwbglge_iywgyxnmpz-3pgpggt&index=2
https://github.com/google-research/electra https://chriskhanhtran.github.io/_posts/2020-06-11-electra-spanish/ https://github.com/allenai/s2orc https://github.com/scibert https://github.com/abachaa/medquad https://www.ncbi.nlm.nih.gov/pmc/articles/pmc5530755/ https://pubmed.ncbi.nlm.nih.gov/24393765/ https://github.com/lasseregin/medical-question-answer-data https://huggingface.co/blog/how-t-train https://arxiv.org/abs/1909.06146 https://www.nlm.nih.gov/databasess/dodroad/pubmed.html


