Medical Electra
1.0.0
質問回答(QA)は、自然言語処理(NLP)および情報検索(IR)の分野です。 QAタスクは、基本的に、指定されたデータまたはデータベースを使用して、自然言語で与えられた質問に対する正確で迅速な回答を提供することを目指しています。このプロジェクトでは、医療用紙に質問する質問の問題に取り組みました。公開され、質問に答えるタスクに使用できる多くの言語モデルがあります。このプロジェクトでは、特に医療分野で訓練された言語モデルを開発したいと考えていました。私たちの目標は、医療用紙でコンテキスト固有の言語モデルを開発し、一般的な言語モデルよりも優れたパフォーマンスを発揮することです。 Electra-Smallをベースモデルとして使用し、医療用紙データセットを使用して訓練し、その後医療QAデータセットで微調整しました。 3つの異なるモデルをトレーニングし、NLPのダウンストリームタスクで結果を比較しました。
ここからモデルにアクセスできます。
Med-Electra Small Model 17GB-64K Vocab https://huggingface.co/enelpi/med-electra-small-discriminator
Med-Electra Small Model 39GB-30.5K Vocab https://huggingface.co/enelpi/med-electra-small-30K-ディスクリミネーター
Med-Electra Small Model 39GB-64K Vocab https://huggingface.co/enelpi/med-electra-small-64k-discriminator
医療用紙S2ORCを使用しました。研究フィールドを使用してS2ORCデータベースをフィルタリングし、医療用紙を取りました。 2つの異なるデータセットを使用し、シャードで構成され、17GBデータセットに11の破片を撮影し、39GBデータセットに26の破片を使用しました。その後、PubMedおよびPubMedCentralで公開されているものを取りました。 PDF_PARSESの文にはより多くの情報が含まれているため、これらの論文のPDF_PARSESのみを使用しました。
{
"section": "Introduction",
"text": "Dogs are happier cats [13, 15]. See Figure 3 for a diagram.",
"cite_spans": [
{"start": 22, "end": 25, "text": "[13", "ref_id": "BIBREF11"},
{"start": 27, "end": 30, "text": "15]", "ref_id": "BIBREF30"},
...
],
"ref_spans": [
{"start": 36, "end": 44, "text": "Figure 3", "ref_id": "FIGREF2"},
]
}
{
...,
"BIBREF11": {
"title": "Do dogs dream of electric humans?",
"authors": [
{"first": "Lucy", "middle": ["Lu"], "last": "Wang", "suffix": ""},
{"first": "Mark", "middle": [], "last": "Neumann", "suffix": "V"}
],
"year": "",
"venue": "barXiv",
"link": null
},
...
}
{
"TABREF4": {
"text": "Table 5. Clearly, we achieve SOTA here or something.",
"type": "table"
}
...,
"FIGREF2": {
"text": "Figure 3. This is the caption of a pretty figure.",
"type": "figure"
},
...
}
}
17GBのコーパスデータサマリー
| 文 | ユニークな言葉 | サイズ | トークンサイズ | |
|---|---|---|---|---|
| 電車 | 111537350 | 27609654 | 16.9GB | 2538210492 |
39GBのコーパスデータの概要
| 文 | ユニークな言葉 | サイズ | トークンサイズ | |
|---|---|---|---|---|
| 電車 | 263134203 | 52206886 | 39.9GB | 6000436472 |
生成されたコーパスを使用して、Electra-Smallモデルをゼロから事前に訓練しました。このモデルは、RTX 2080 TI GPUでトレーニングされています。
| モデル | レイヤー | 隠されたサイズ | パラメーター |
|---|---|---|---|
| Electra-Small | 12 | 256 | 14m |
17GBの場合
行数:111332331
単語数(トークン):2538210492
このモデルは、訓練に6日間12時間かかりました
| メトリック | 価値 |
|---|---|
| disc_accuracy | 0.9456 |
| disc_auc | 0.9256 |
| disc_loss | 0.154 |
| disc_precision | 0.7832 |
| disc_recall | 0.4545 |
| 損失 | 10.45 |
| masked_lm_accuracy | 0.5168 |
| masked_lm_loss | 2.776 |
| sampled_masked_lm_accuracy | 0.4135 |
30.5kの語彙サイズの39GBの場合
行数:263134203
単語数(トークン):6000436472
このモデルは、訓練に5日間9時間かかりました
| メトリック | 価値 |
|---|---|
| disc_accuracy | 0.943 |
| disc_auc | 0.9184 |
| disc_loss | 0.1609 |
| disc_precision | 0.7718 |
| disc_recall | 0.4153 |
| 損失 | 10.72 |
| masked_lm_accuracy | 0.5218 |
| masked_lm_loss | 2.7 |
| sampled_masked_lm_accuracy | 0.4177 |
64kの語彙サイズの39GBの場合
行数:263134203
単語数(トークン):6000436472
このモデルは、訓練に6日間12時間かかりました
| メトリック | 価値 |
|---|---|
| disc_accuracy | 0.9453 |
| disc_auc | 0.9278 |
| disc_loss | 0.1534 |
| disc_precision | 0.7788 |
| disc_recall | 0.4655 |
| 損失 | 10.48 |
| masked_lm_accuracy | 0.5095 |
| masked_lm_loss | 2.82 |
| sampled_masked_lm_accuracy | 0.4066 |
のために
| モデル/ハイパーパラメーター | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-Small | 1m | 64000 | 128 |
トレーニング結果にアクセスできます。
https://tensorboard.dev/experiment/g9pkbfzaqeacr7dgw2uljq/#scalars https://tensorboard.dev/experiment/qu1bq0mirgocgqbzhqs2ta/#scalars
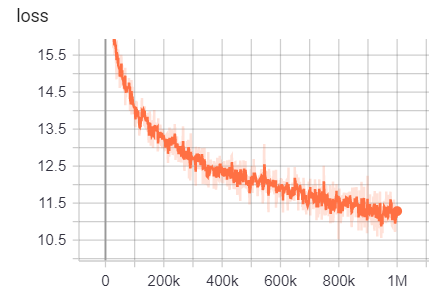
のために
| モデル/ハイパーパラメーター | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-Small | 1m | 30522 | 128 |
トレーニング結果にアクセスできます。
https://tensorboard.dev/experiment/npyu6mkhrmgoyd8kdsqw5w/#scalars https://tensorboard.dev/experiment/zqbeq7zjsdyijs5jb8ov3g/#scalars
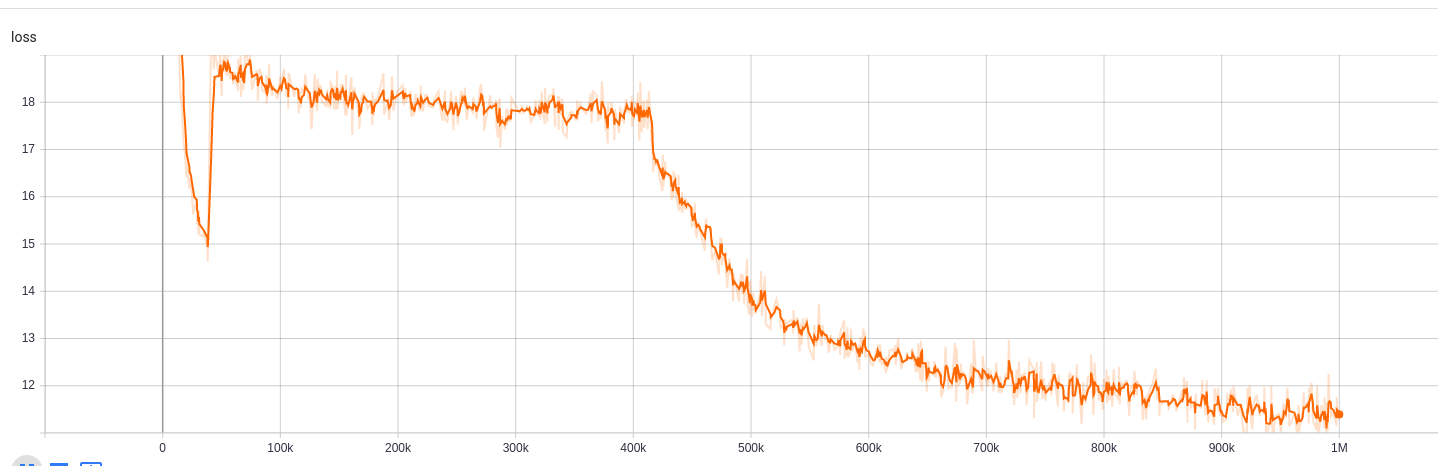
のために
| モデル/ハイパーパラメーター | train_steps | vocab_size | batch_size |
|---|---|---|---|
| Electra-Small | 1m | 64000 | 128 |
トレーニング結果にアクセスできます。
https://tensorboard.dev/experiment/gc51rmhdtgmj7eq0uyuavw/#scalars https://tensorboard.dev/experiment/q66kfo3lqtwk1kykgjcyyg/#scalars
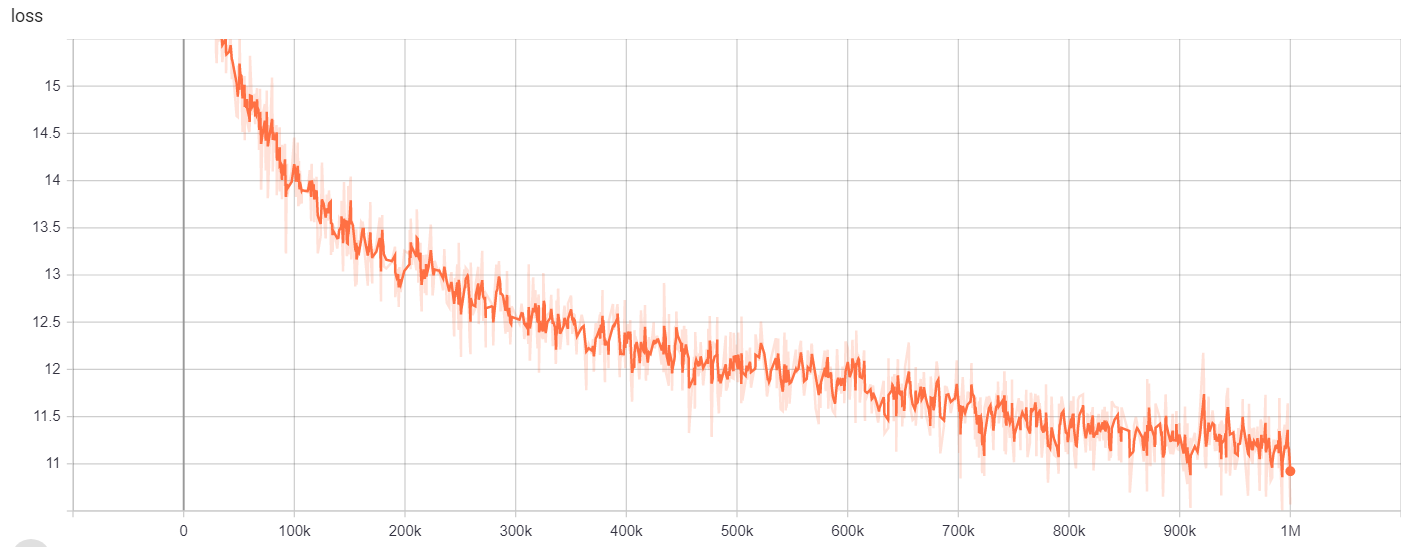
指定されたエンティティ認識には、PubMedに掲載された疾患名認識のリソースであるNCBI-Disease Corpusを使用しました。
| モデル | F1 | 損失 | 正確さ | 精度 | 想起 |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator | 0.8462 | 0.0545 | 0.9827 | 0.8052 | 0.8462 |
| Google/Electra-Small-Discriminator | 0.8294 | 0.0640 | 0.9806 | 0.7998 | 0.8614 |
| Google/Electra-Base-Discriminator | 0.8580 | 0.0675 | 0.9835 | 0.8446 | 0.8718 |
| Distilbert-Base-Uncased | 0.8348 | 0.0832 | 0.9815 | 0.8126 | 0.8583 |
| distilroberta-base | 0.8416 | 0.0828 | 0.9808 | 0.8207 | 0.8635 |
| モデル | F1 | 損失 | 正確さ | 精度 | 想起 |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator | 0.8425 | 0.0545 | 0.9824 | 0.8028 | 0.8864 |
| Google/Electra-Small-Discriminator | 0.8280 | 0.0642 | 0.9807 | 0.7961 | 0.8625 |
| Google/Electra-Base-Discriminator | 0.8648 | 0.0682 | 0.9838 | 0.8442 | 0.8864 |
| Distilbert-Base-Uncased | 0.8373 | 0.0806 | 0.9814 | 0.8153 | 0.8604 |
| distilroberta-base | 0.8329 | 0.0811 | 0.9801 | 0.8100 | 0.8572 |
| モデル | F1 | 損失 | 正確さ | 精度 | 想起 |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator | 0.8463 | 0.0559 | 0.9823 | 0.8071 | 0.8895 |
| Google/Electra-Small-Discriminator | 0.8280 | 0.0691 | 0.9806 | 0.8025 | 0.8552 |
| Google/Electra-Base-Discriminator | 0.8542 | 0.0645 | 0.9840 | 0.8307 | 0.8791 |
| Distilbert-Base-Uncased | 0.8424 | 0.0799 | 0.9822 | 0.8251 | 0.8604 |
| distilroberta-base | 0.8339 | 0.0924 | 0.9806 | 0.8136 | 0.8552 |
質問に答えるタスクには、BioASQ質問データセットを使用しました。
| モデル | SACC | LACC |
|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator-128 | 0.2821 | 0.4359 |
| Google/Electra-Small-Discriminator-128 | 0.3077 | 0.5128 |
| Enelpi/Med-Electra-Small-Discriminator-512 | 0.1538 | 0.3590 |
| Google/Electra-Small-Discriminator-512 | 0.2564 | 0.5128 |
YouTubeからのプレゼンテーションビデオにアクセスできます。 https://www.youtube.com/watch?v=fao9clyfldc&list=plhnxo6hzwbglge_iywgyxnmpz-3pgpggt&index=2
https://github.com/google-research/electra https://chriskhanhtran.github.io/_posts/2020-06-06-11-electra-spanish/ https://github.com/allenai/s2orc https://github.com/allenai/scibert https://github.com/abachaa/medquad https://www.ncbi.nlm.nih.gov/pmc/articles/pmc5530755/ https://pubmed.ncbi.nlm.nih.gov/243933777775/ https://github.com/lasseregin/medical-question-answer-data https://huggingface.co/blog/how-to-train https://arxiv.org/abs/1909.09.06146 https://www.nlm.nih.nih.gov/databis.mmhlodabys/databhhmhllow.


