Medical Electra
1.0.0
PERTANYAAN PERTANYAAN (QA) adalah bidang dalam pemrosesan bahasa alami (NLP) dan pengambilan informasi (IR). Tugas QA pada dasarnya bertujuan untuk memberikan jawaban yang tepat dan cepat untuk pertanyaan yang diberikan dalam bahasa alami dengan menggunakan data atau database yang diberikan. Dalam proyek ini, kami menangani masalah menjawab pertanyaan di surat -surat medis. Ada banyak model bahasa yang diterbitkan dan tersedia untuk digunakan untuk tugas menjawab pertanyaan. Dalam proyek ini, kami ingin mengembangkan model bahasa, secara khusus dilatih di bidang medis. Tujuan kami adalah mengembangkan model bahasa khusus konteks pada makalah medis, berkinerja lebih baik daripada model bahasa umum. Kami menggunakan electra-small sebagai model dasar kami, dan melatihnya menggunakan dataset kertas medis, kemudian disesuaikan dengan dataset QA medis. Kami melatih tiga model yang berbeda, dan membandingkan hasilnya pada tugas hilir NLP.
Anda dapat mengakses model kami di sini:
Med-Electra Small Model 17GB-64K Vocab https://huggingface.co/enelpi/med-electra-small-discriminator
Med-Electra Small Model 39GB-30.5k Vocab https://huggingface.co/enelpi/med-electra-small-30k-discriminator
Med-Electra Small Model 39GB-64K Vocab https://huggingface.co/enelpi/med-electra-small-64k-discriminator
Kami menggunakan Medical Papers S2ORC. Kami memfilter basis data S2ORC menggunakan bidang studi, dan mengambil kertas medis. Kami menggunakan dua kumpulan data yang berbeda, terdiri dari pecahan, kami mengambil 11 pecahan untuk dataset 17GB, dan menggunakan 26 pecahan untuk dataset 39GB. Setelah itu, kami mengambil yang diterbitkan di PubMed dan PubMedCentral. Kami hanya menggunakan pdf_parses dari makalah -kertas itu, karena kalimat di PDF_Parses berisi lebih banyak informasi.
{
"section": "Introduction",
"text": "Dogs are happier cats [13, 15]. See Figure 3 for a diagram.",
"cite_spans": [
{"start": 22, "end": 25, "text": "[13", "ref_id": "BIBREF11"},
{"start": 27, "end": 30, "text": "15]", "ref_id": "BIBREF30"},
...
],
"ref_spans": [
{"start": 36, "end": 44, "text": "Figure 3", "ref_id": "FIGREF2"},
]
}
{
...,
"BIBREF11": {
"title": "Do dogs dream of electric humans?",
"authors": [
{"first": "Lucy", "middle": ["Lu"], "last": "Wang", "suffix": ""},
{"first": "Mark", "middle": [], "last": "Neumann", "suffix": "V"}
],
"year": "",
"venue": "barXiv",
"link": null
},
...
}
{
"TABREF4": {
"text": "Table 5. Clearly, we achieve SOTA here or something.",
"type": "table"
}
...,
"FIGREF2": {
"text": "Figure 3. This is the caption of a pretty figure.",
"type": "figure"
},
...
}
}
Ringkasan Data Corpus untuk 17GB
| Kalimat | Kata -kata unik | Ukuran | Ukuran token | |
|---|---|---|---|---|
| Kereta | 111537350 | 27609654 | 16.9GB | 2538210492 |
Ringkasan Data Corpus untuk 39GB
| Kalimat | Kata -kata unik | Ukuran | Ukuran token | |
|---|---|---|---|---|
| Kereta | 263134203 | 52206886 | 39.9GB | 6000436472 |
Menggunakan corpus yang dihasilkan, kami pra-terlatih model electra-small dari awal. Model ini dilatih pada RTX 2080 Ti GPU.
| Model | Lapisan | Ukuran tersembunyi | Parameter |
|---|---|---|---|
| Electra-Small | 12 | 256 | 14m |
Untuk 17GB
Jumlah baris: 111332331
Jumlah kata (token): 2538210492
Model ini membutuhkan waktu 6 hari 12 jam untuk berlatih
| Metrik | Nilai |
|---|---|
| disc_accuracy | 0.9456 |
| disc_auc | 0.9256 |
| disc_loss | 0.154 |
| disc_precision | 0.7832 |
| disc_recall | 0.4545 |
| kehilangan | 10.45 |
| masked_lm_accuracy | 0.5168 |
| masked_lm_loss | 2.776 |
| sampled_masked_lm_accuracy | 0.4135 |
Untuk 39GB dengan ukuran kosa kata 30,5k
Jumlah baris: 263134203
Jumlah kata (token): 6000436472
Model ini membutuhkan waktu 5 hari untuk berlatih
| Metrik | Nilai |
|---|---|
| disc_accuracy | 0.943 |
| disc_auc | 0.9184 |
| disc_loss | 0.1609 |
| disc_precision | 0.7718 |
| disc_recall | 0.4153 |
| kehilangan | 10.72 |
| masked_lm_accuracy | 0.5218 |
| masked_lm_loss | 2.7 |
| sampled_masked_lm_accuracy | 0.4177 |
Untuk 39GB dengan ukuran kosa kata 64K
Jumlah baris: 263134203
Jumlah kata (token): 6000436472
Model ini membutuhkan waktu 6 hari 12 jam untuk berlatih
| Metrik | Nilai |
|---|---|
| disc_accuracy | 0.9453 |
| disc_auc | 0.9278 |
| disc_loss | 0.1534 |
| disc_precision | 0.7788 |
| disc_recall | 0.4655 |
| kehilangan | 10.48 |
| masked_lm_accuracy | 0.5095 |
| masked_lm_loss | 2.82 |
| sampled_masked_lm_accuracy | 0.4066 |
Untuk
| Model/Hyperparameters | train_steps | vocab_size | Batch_Size |
|---|---|---|---|
| Electra-Small | 1m | 64000 | 128 |
Hasil pelatihan dapat diakses di sini:
https://tensorboard.dev/experiment/g9pkbfzaqeacr7dgw2uljq/#scalars https://tensorboard.dev/experiment/qu1bq0mirgocgqbzhqs2ta/#scalars
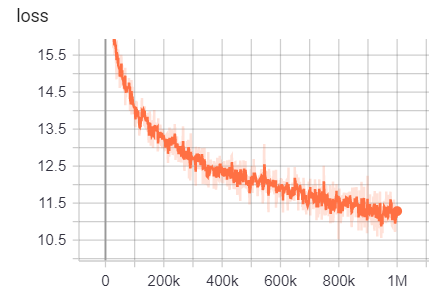
Untuk
| Model/Hyperparameters | train_steps | vocab_size | Batch_Size |
|---|---|---|---|
| Electra-Small | 1m | 30522 | 128 |
Hasil pelatihan dapat diakses di sini:
https://tensorboard.dev/experiment/npyu6mkhrmgoyd8kdsqw5w/#scalars https://tensorboard.dev/experiment/zqbeq7zjsdyijs5jb8ov3g/#scalars
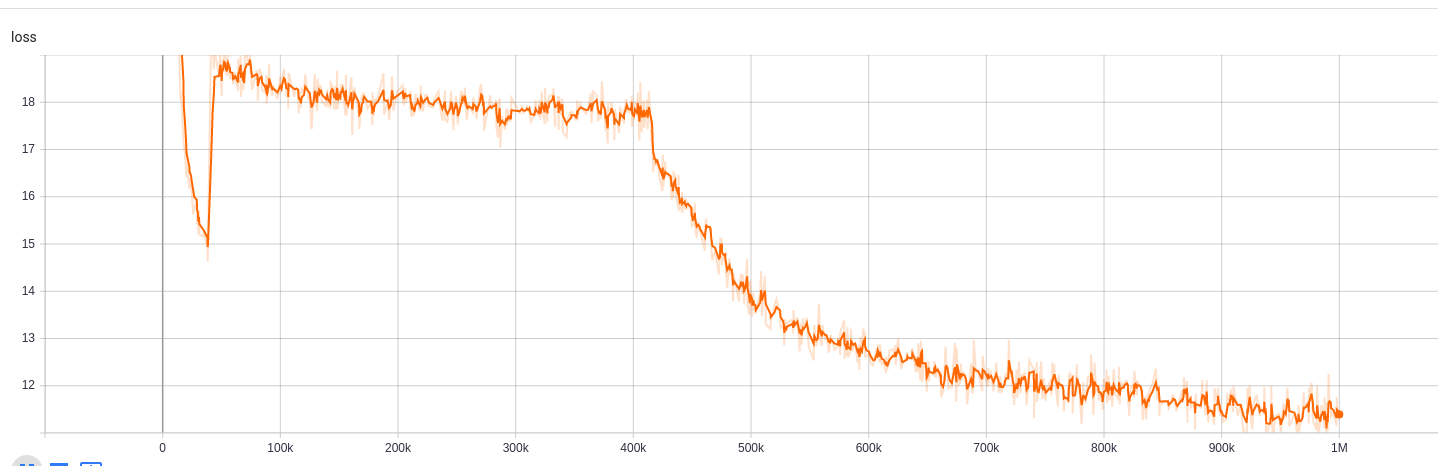
Untuk
| Model/Hyperparameters | train_steps | vocab_size | Batch_Size |
|---|---|---|---|
| Electra-Small | 1m | 64000 | 128 |
Hasil pelatihan dapat diakses di sini:
https://tensorboard.dev/experiment/gc51rmhdtgmj7eq0UyUavw/#scalars https://tensorboard.dev/experiment/q66kfo3lqtwk1kykgjcyyg/#scalars
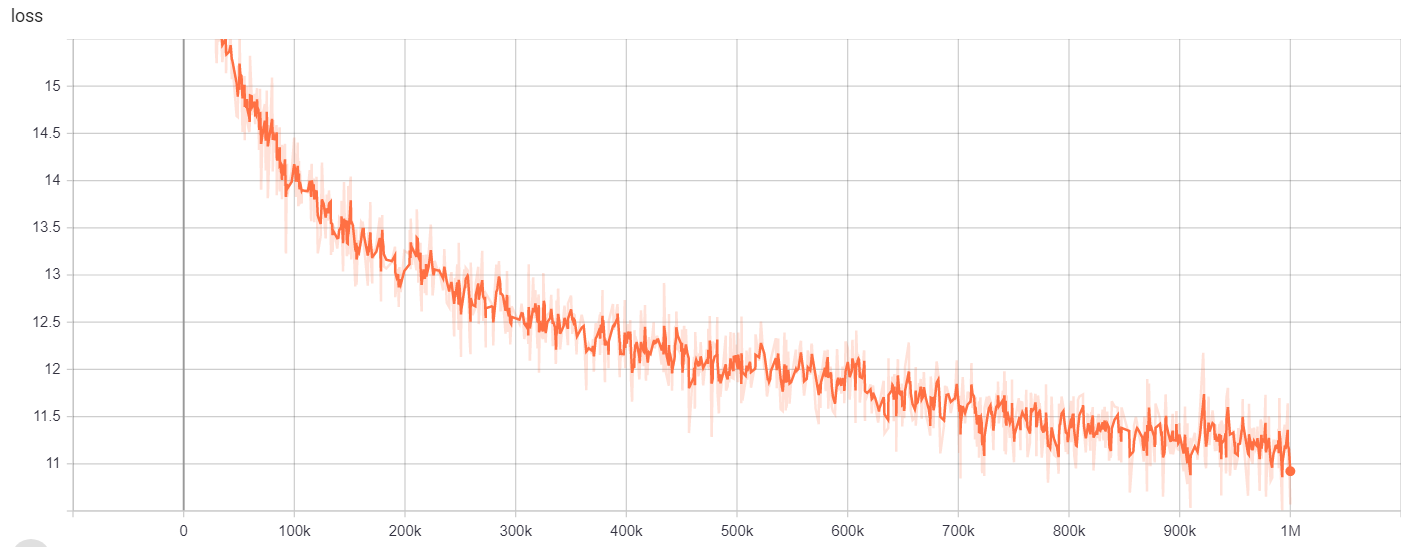
Untuk pengenalan entitas bernama, kami menggunakan ncbi-disease corpus, yang merupakan sumber daya untuk pengenalan nama penyakit yang diterbitkan di PubMed.
| Model | F1 | Kehilangan | ketepatan | presisi | mengingat |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator | 0.8462 | 0,0545 | 0.9827 | 0.8052 | 0.8462 |
| Google/Electra-Small-Discriminator | 0.8294 | 0,0640 | 0.9806 | 0.7998 | 0.8614 |
| Google/electra-base-disriminator | 0.8580 | 0,0675 | 0.9835 | 0.8446 | 0.8718 |
| Distilbert-Base-Incased | 0.8348 | 0,0832 | 0.9815 | 0.8126 | 0.8583 |
| Distilroberta-base | 0.8416 | 0,0828 | 0.9808 | 0.8207 | 0.8635 |
| Model | F1 | Kehilangan | ketepatan | presisi | mengingat |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator | 0.8425 | 0,0545 | 0.9824 | 0.8028 | 0.8864 |
| Google/Electra-Small-Discriminator | 0.8280 | 0,0642 | 0.9807 | 0.7961 | 0.8625 |
| Google/electra-base-disriminator | 0.8648 | 0,0682 | 0.9838 | 0.8442 | 0.8864 |
| Distilbert-Base-Incased | 0.8373 | 0,0806 | 0.9814 | 0.8153 | 0.8604 |
| Distilroberta-base | 0.8329 | 0,0811 | 0.9801 | 0.8100 | 0.8572 |
| Model | F1 | Kehilangan | ketepatan | presisi | mengingat |
|---|---|---|---|---|---|
| Enelpi/Med-Electra-Small-Discriminator | 0.8463 | 0,0559 | 0.9823 | 0.8071 | 0.8895 |
| Google/Electra-Small-Discriminator | 0.8280 | 0,0691 | 0.9806 | 0.8025 | 0.8552 |
| Google/electra-base-disriminator | 0.8542 | 0,0645 | 0.9840 | 0.8307 | 0.8791 |
| Distilbert-Base-Incased | 0.8424 | 0,0799 | 0.9822 | 0.8251 | 0.8604 |
| Distilroberta-base | 0.8339 | 0,0924 | 0.9806 | 0.8136 | 0.8552 |
Untuk tugas menjawab pertanyaan, kami menggunakan dataset pertanyaan bioasq.
| Model | Sacc | Lacc |
|---|---|---|
| enelpi/med-electra-small-disriminator-128 | 0.2821 | 0.4359 |
| Google/electra-small-diskriminator-128 | 0.3077 | 0.5128 |
| enelpi/med-electra-small-disriminator-512 | 0.1538 | 0.3590 |
| Google/electra-small-disriminator-512 | 0.2564 | 0.5128 |
Anda dapat mengakses video presentasi dari YouTube. https://www.youtube.com/watch?v=fao9clyfldc&list=plhnxo6hzwbglge_iywgyxnmpz-3pgpggt&index=2
https://github.com/google-research/electra https://chriskhanhtran.github.io/_posts/2020-06-11-electra-panish//github.com/allenai/s2orc https://github.com/allenai/s2orc https://github.com/allenai/s2orc https://github.com/allenai/s2orc https://github.com/abachaa/medquad https://www.ncbi.nlm.nih.gov/pmc/articles/pmc5530755/ https://pubmed.ncbi.nlm.nih.gov/243937/ https://github.com/lasseregin/medical-question-answer-data https://huggingface.co/blog/how-train-train https://arxiv.org/1909.06146 https://wwww.nl.nih.nihassdown/ddown/ddown/ddown/www.nl.nihl.nihasspDINDS://www.nlm.


