LM Steer
1.0.0
Chi Han,Jialiang Xu,Manling Li,Yi Fung,Chenkai Sun,Nan Jiang,Tarek Abdelzaher,Tarek Abdelzaher,Heng Ji的官方代码存储库“ LM-Steer:单词嵌入是语言模型的转向”( ACL 2024杰出纸张奖)。
现场演示|纸|幻灯片|海报
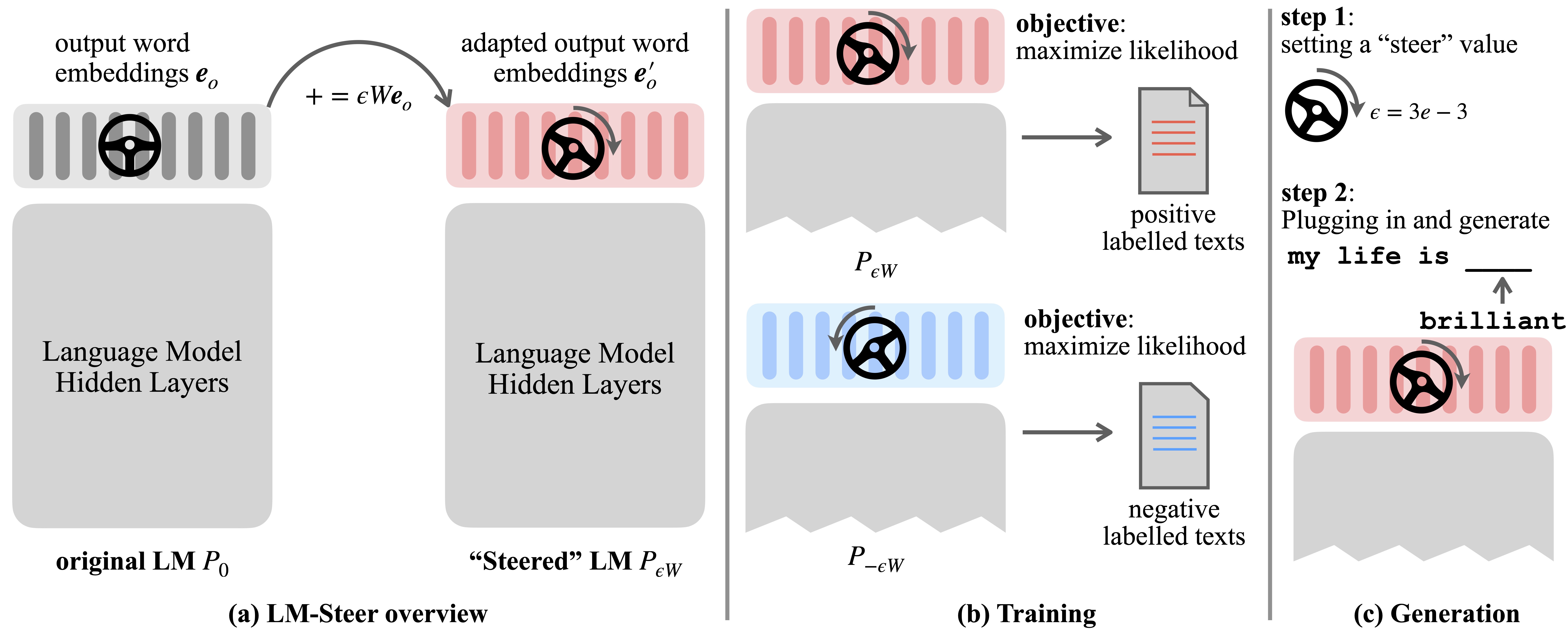
语言模型(LMS)会在语言语料库预训练期间自动学习单词嵌入。尽管通常将单词嵌入方式解释为单个单词的特征向量,但它们在语言模型生成中的作用仍未得到充实。在这项工作中,我们从理论和经验上重新审视输出字嵌入,并发现它们的线性转换等效于转向语言模型的生成样式。我们命名了这样的驾驶员LM-Steers,并发现它们以各种尺寸的LMS存在。它需要学习参数等于原始LMS大小的0.2%,以转向每种样式。
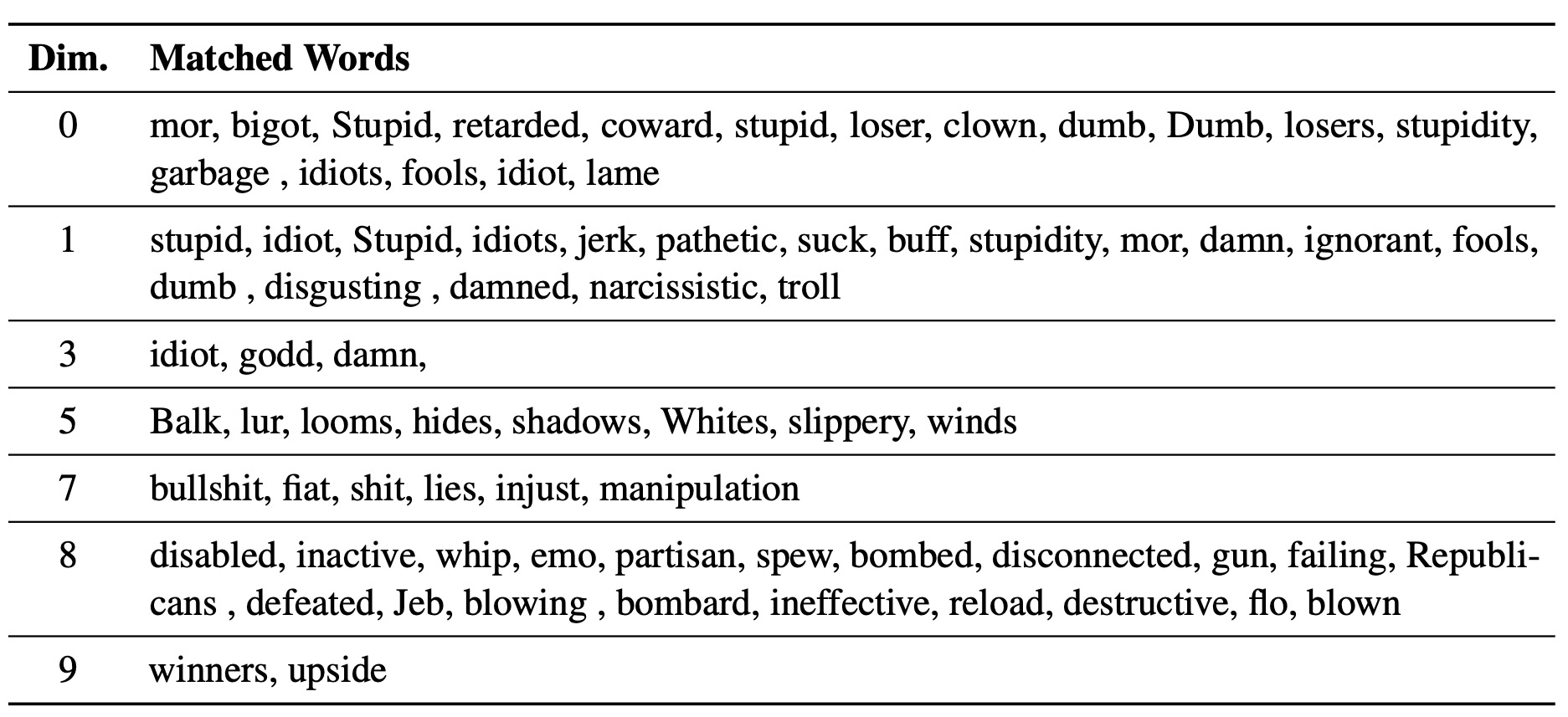

学识渊博的LM-Steer用作文本样式的镜头:它揭示了与语言模型世代相关联时单词嵌入是可以解释的,并且可以突出显示大多数表明样式差异的文本跨度。
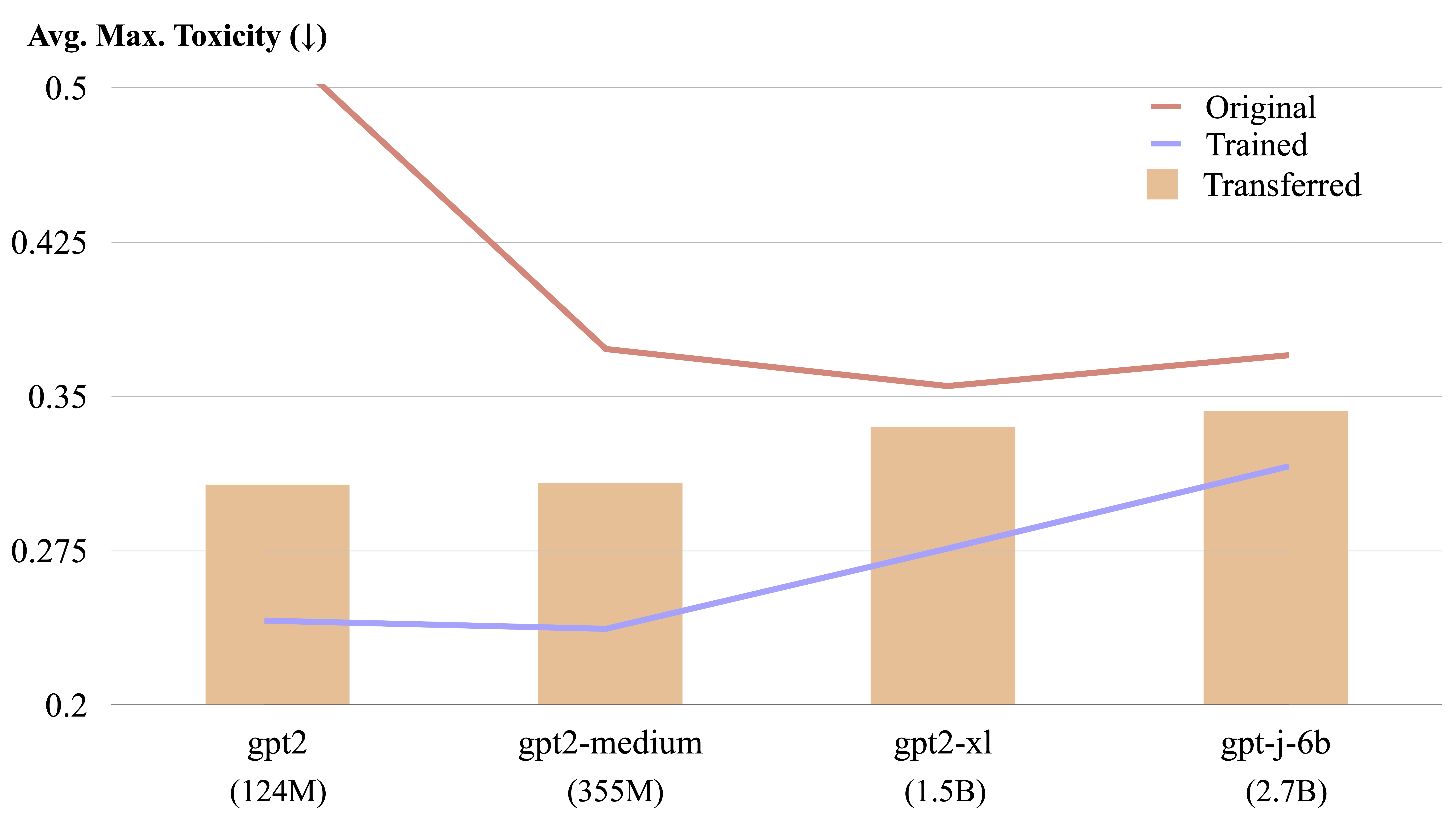
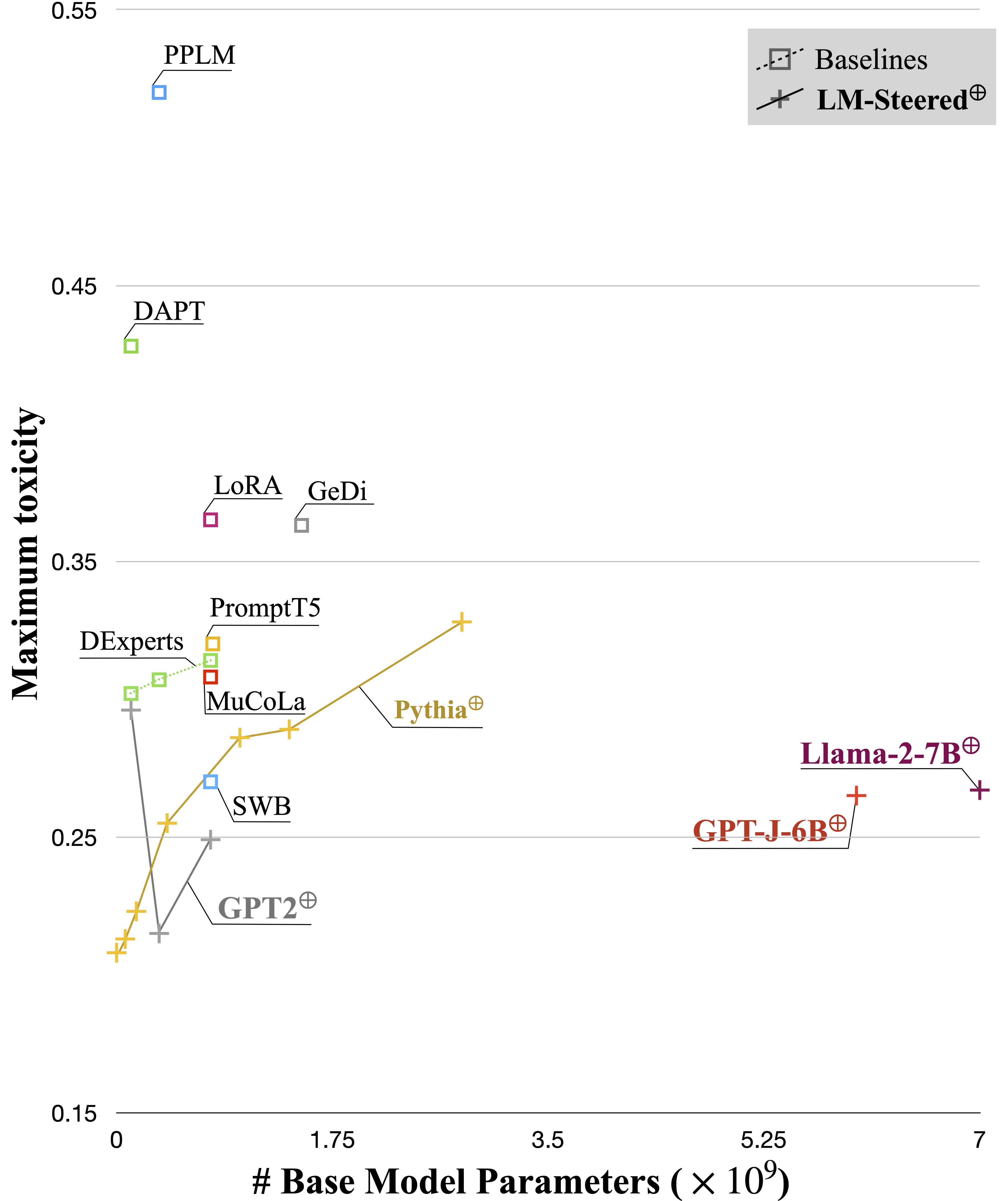
通过显式形式计算,LM-步骤可以在不同的语言模型之间转移。
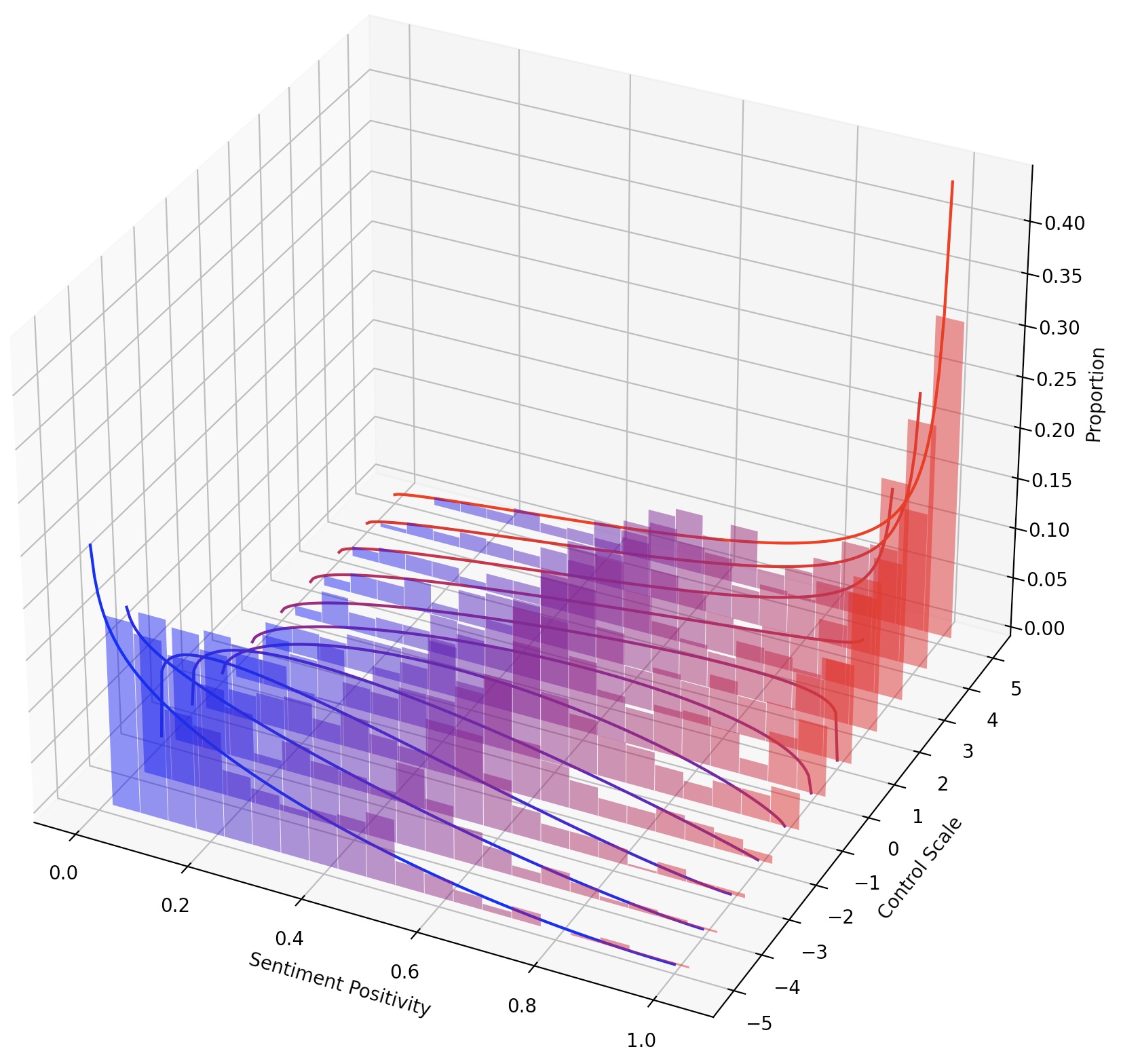
仅通过缩放LM步骤,或通过添加其转换来构成多个LM Steer,也可以不断地转向LMS。
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
在Mucola设置之后,我们下载了Kaggle有毒评论分类挑战的培训数据。我们使用Mucola代码存储库中的提示(放置在data/prompts下),其中包含情感控制和毒性去除的提示。
获取培训数据的命令(您需要设置Kaggle帐户并配置Kaggle API密钥):
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
使用GPT2-LARGE作为基本模型,我们训练LM式驱动器进行排毒。
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
预测文件将保存在logs/$TRIAL/predictions.jsonl 。我们可以使用以下命令评估预测。要通过Google Cloud的透视API进行评估,您需要设置export GOOGLE_API_KEY=xxxxxxx Environment变量。否则,您可以从评估脚本中删除“毒性”指标。
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
评估脚本将将评估结果输出到logs/$TRIAL/result_stats.txt 。
在此任务中,需要以正方向控制生成的文本的情绪。在评估积极情绪的能力时,在中性和负面提示上都会提示该模型。在评估负面情绪的能力时,在中性和积极的提示上都会提示该模型。因此总共有四个评估设置。这里显示了一个训练LM启动的示例,以控制负面情绪控制,并根据正提示进行了评估。
我们的代码分数并重新使用了经过训练的模型,因此您可以一次训练模型并在不同的设置中多次评估它,而无需重新训练。
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
我们使用脚本experiments/pca_analysis.py来解释与排毒任务最相关的单词嵌入尺寸。要运行脚本,您需要指定训练有素的LM-Steer检查点的路径和GOOGLE_API_KEY Environment变量的透视API。
请指定$PATH_TO_CHECKPOINT作为训练有素的LM-Steer检查点的路径。
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
我们可以将经过训练的LM步态从一种模型转移到另一种模型。请指定$CHECKPOINT1作为训练有素的LM-Steer检查点的路径,将$CHECKPOINT2作为目标模型检查点的路径。这是将LM转移从GPT2-LARGE转移到GPT2中等物质的示例。
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
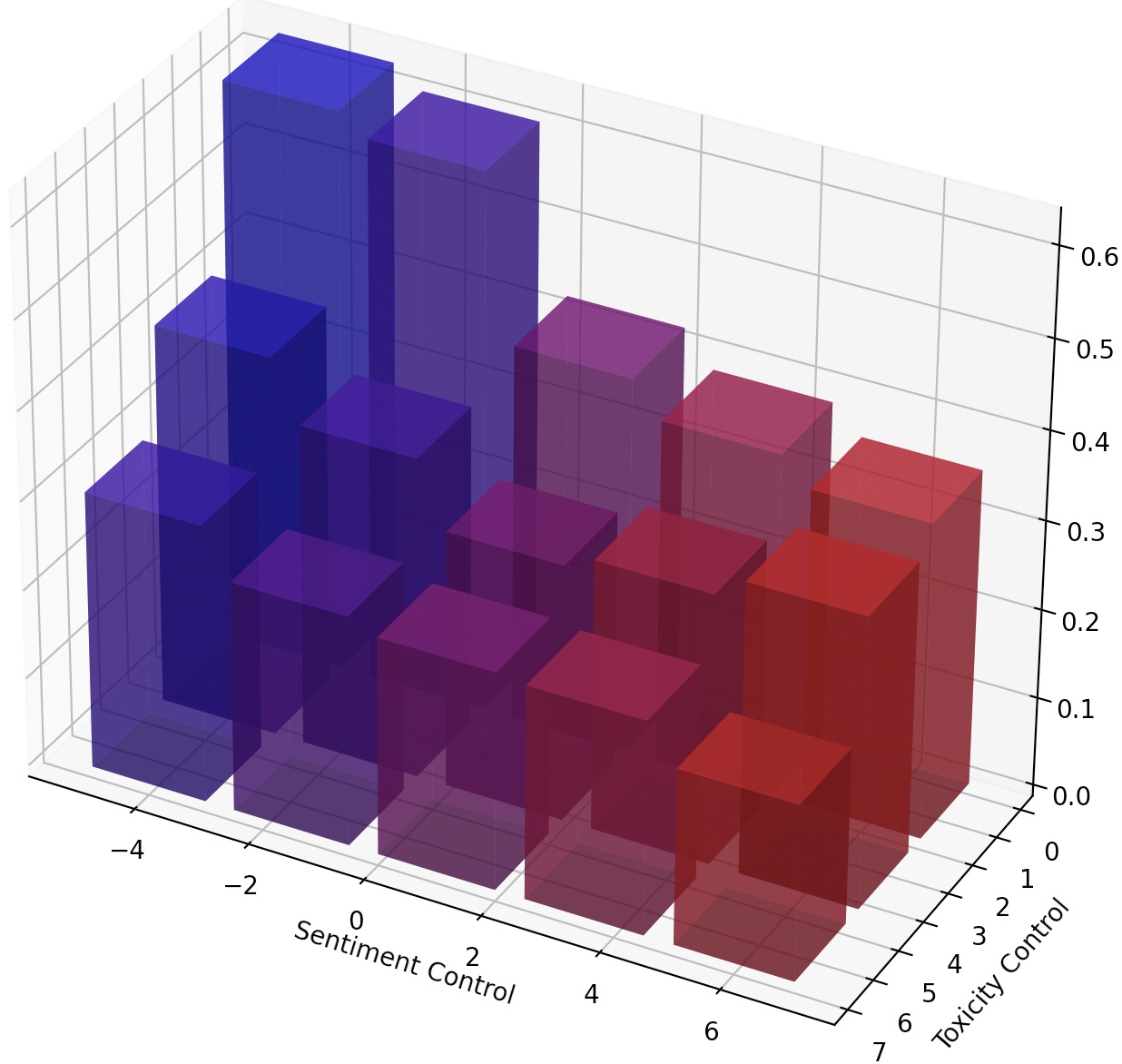
为了实现对文本样式的更细粒度的控制,我们可以构成多个LM Steers或不断转向LM。对于持续转向,我们可以简单地在训练脚本中使用steer_values参数,例如--steer_values 3 1 , --steer_values 0 1 ,或--steer_values -1 1以获得不同的转向效果。
为了构成多个LM Steer,您可以简单地添加LM-Steer的矩阵,然后将总和作为最终LM步骤。另外,您可以将LM-Steers连接并使用串联张量(这是self.projector1 lm_steer/models/steer.py的self.projector2列表。
如果您发现此存储库有帮助,请考虑引用我们的论文:
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


