LM Steer
1.0.0
Repositori kode resmi untuk makalah " LM-Steer: Word Embeddings adalah sapi jantan untuk model bahasa " ( ACL 2024 Outstanding Paper Award ) oleh Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek Abdelzaher, Heng Ji.
Demo langsung | Kertas | Slide | Poster
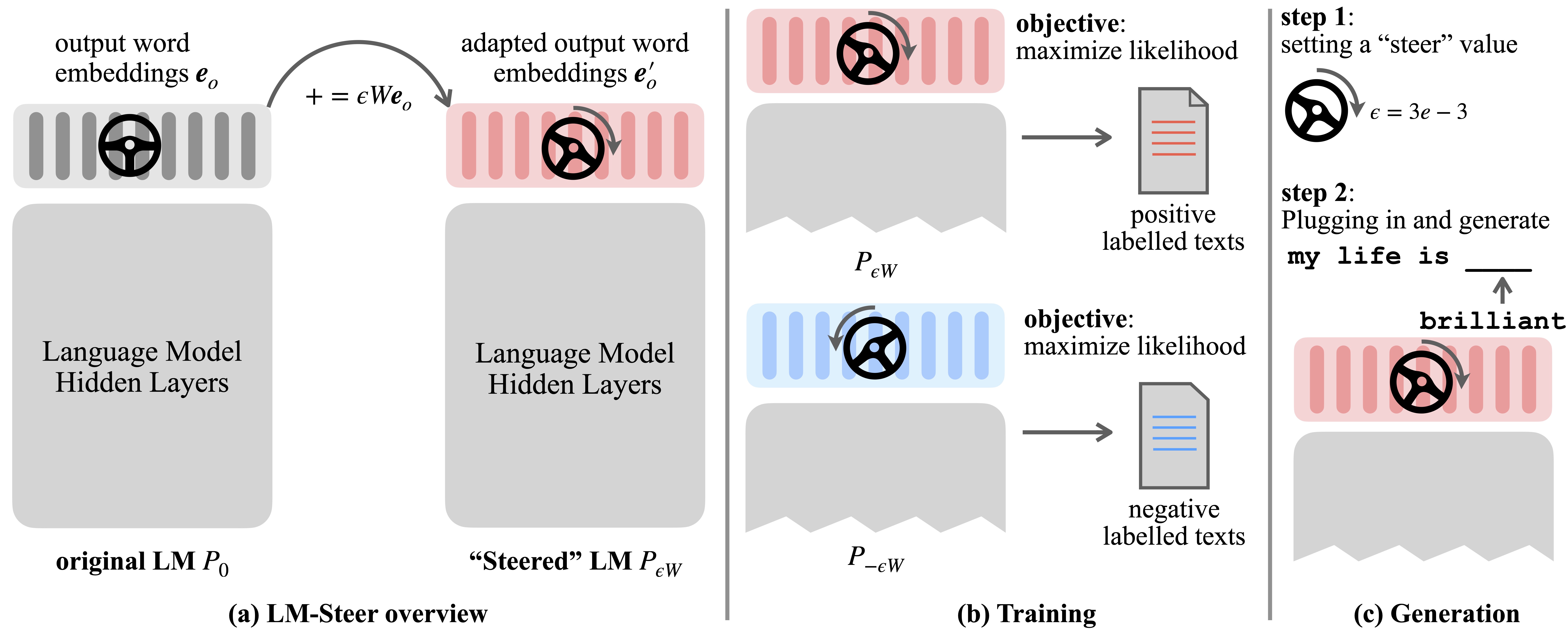
Model Bahasa (LMS) secara otomatis mempelajari embedding kata selama pra-pelatihan pada korpora bahasa. Meskipun embedding kata biasanya ditafsirkan sebagai vektor fitur untuk kata -kata individual, peran mereka dalam generasi model bahasa tetap kurang dieksplorasi. Dalam karya ini, kami secara teoritis dan empiris meninjau kembali embeddings output kata dan menemukan bahwa transformasi liniernya setara dengan gaya pembuatan model bahasa yang mengarah. Kami menyebutkan steer LM dan menemukan mereka ada di LMS dari semua ukuran. Ini membutuhkan parameter pembelajaran yang sama dengan 0,2% dari ukuran LMS asli untuk mengarahkan setiap gaya.
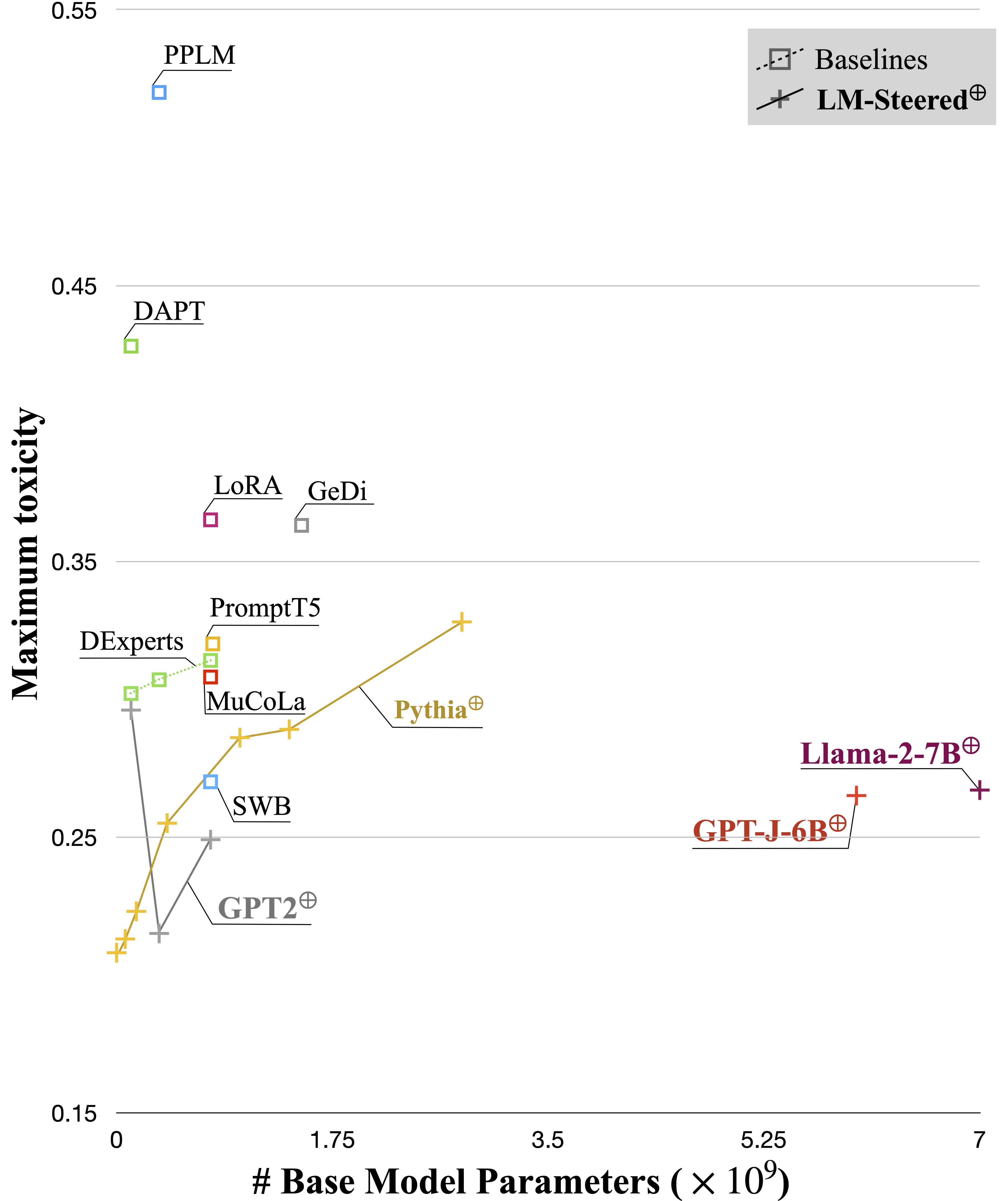
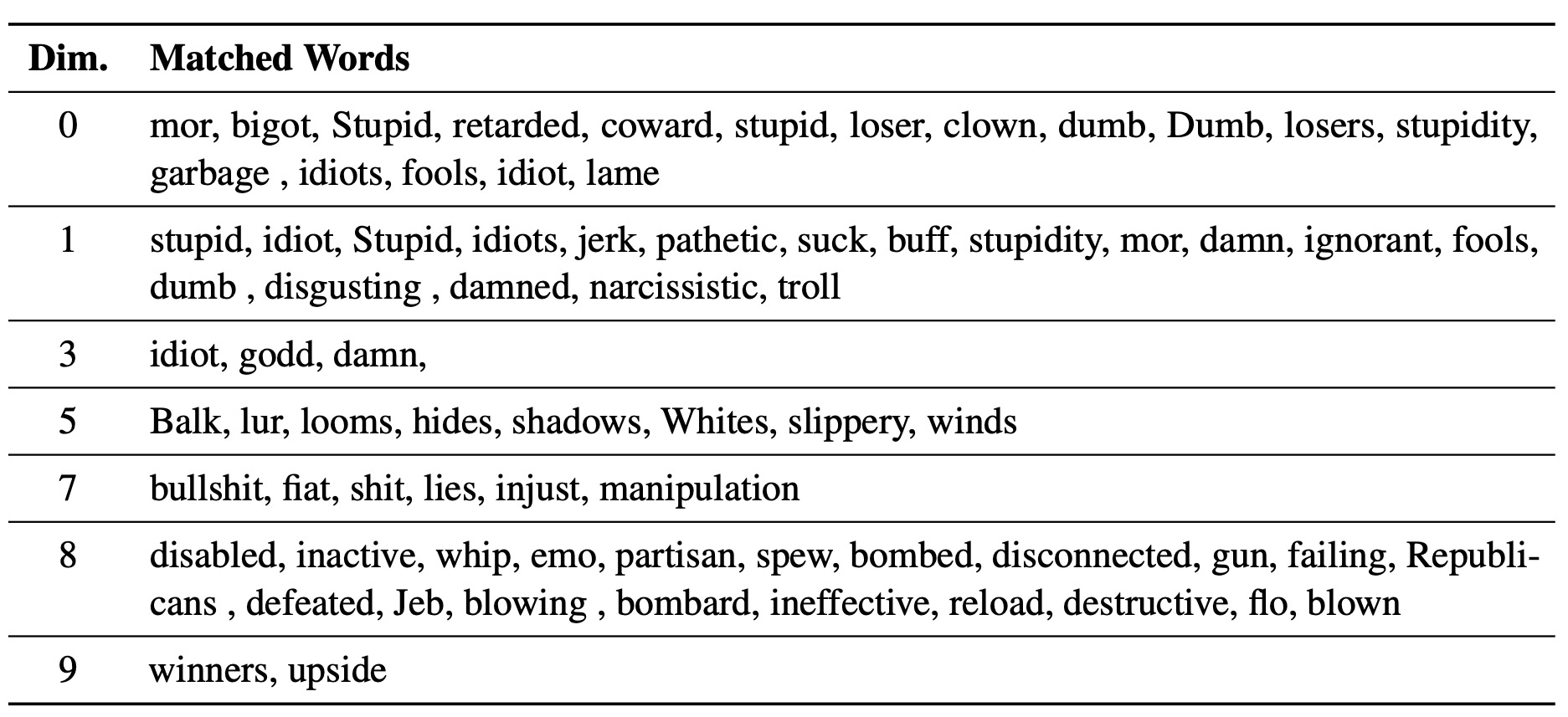

LM-Steer yang dipelajari berfungsi sebagai lensa dalam gaya teks: ia mengungkapkan bahwa kata embeddings dapat ditafsirkan ketika dikaitkan dengan generasi model bahasa, dan dapat menyoroti rentang teks yang paling menunjukkan perbedaan gaya.
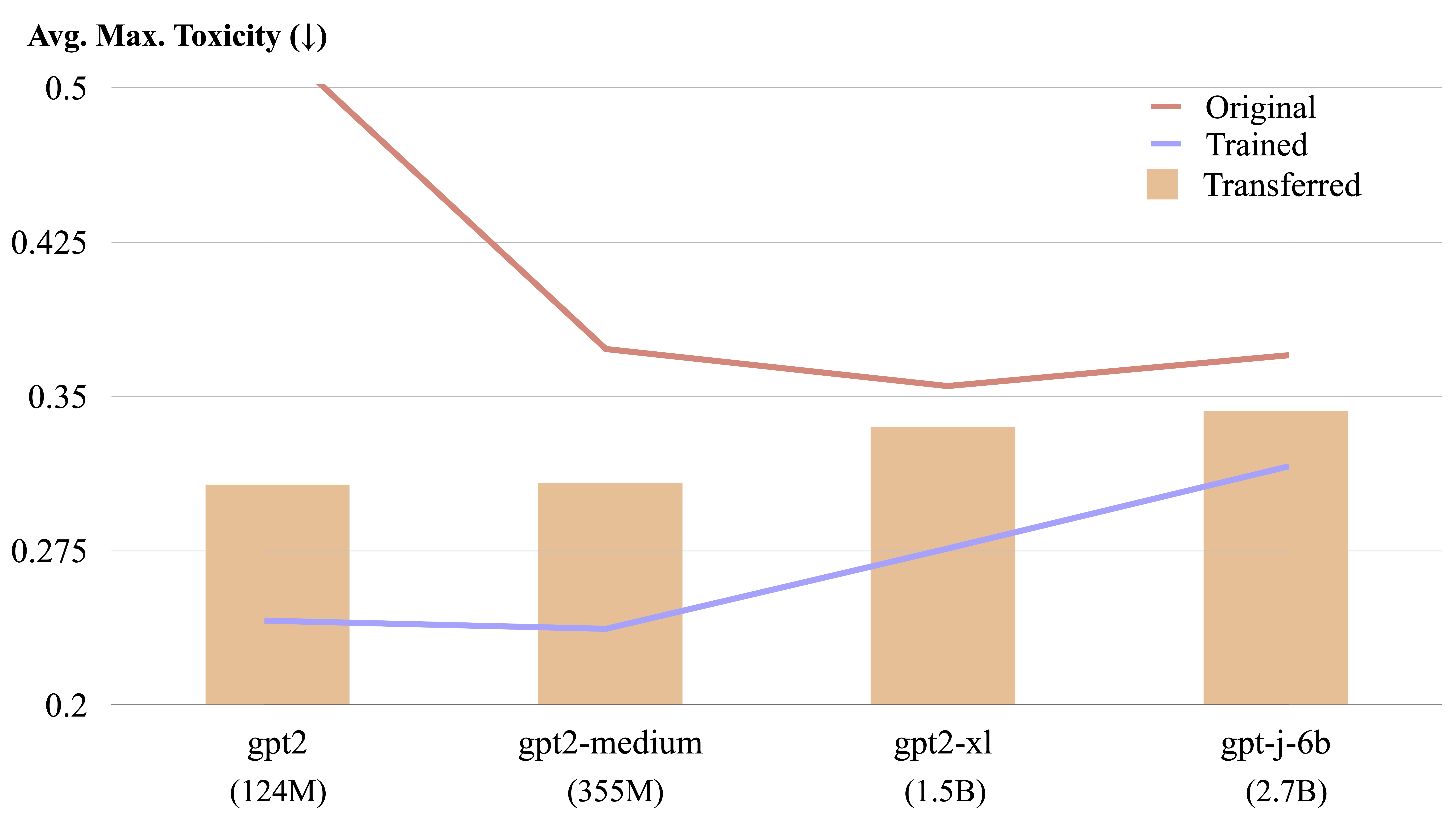
LM-Steer dapat ditransfer antara model bahasa yang berbeda dengan perhitungan bentuk eksplisit.
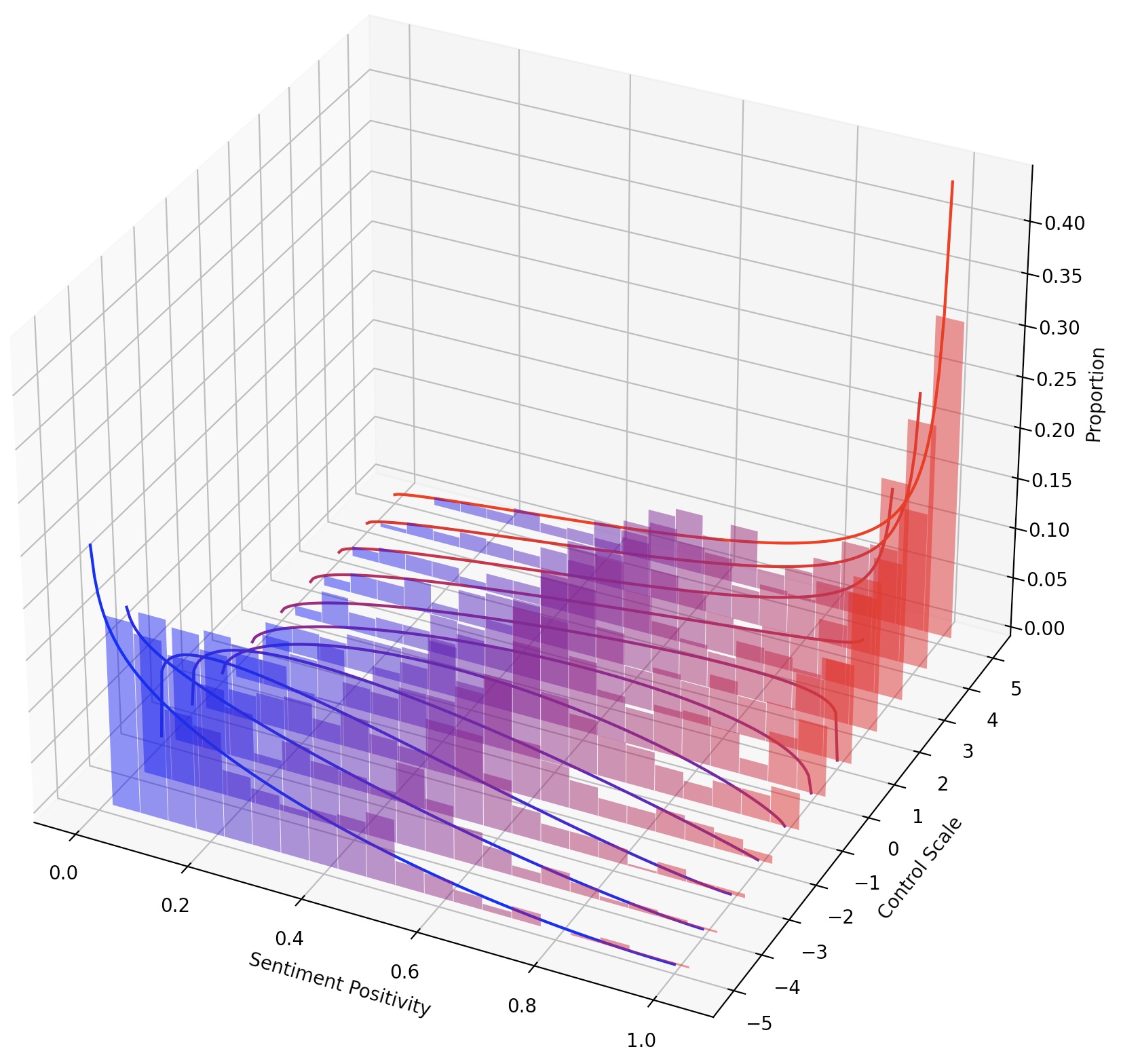
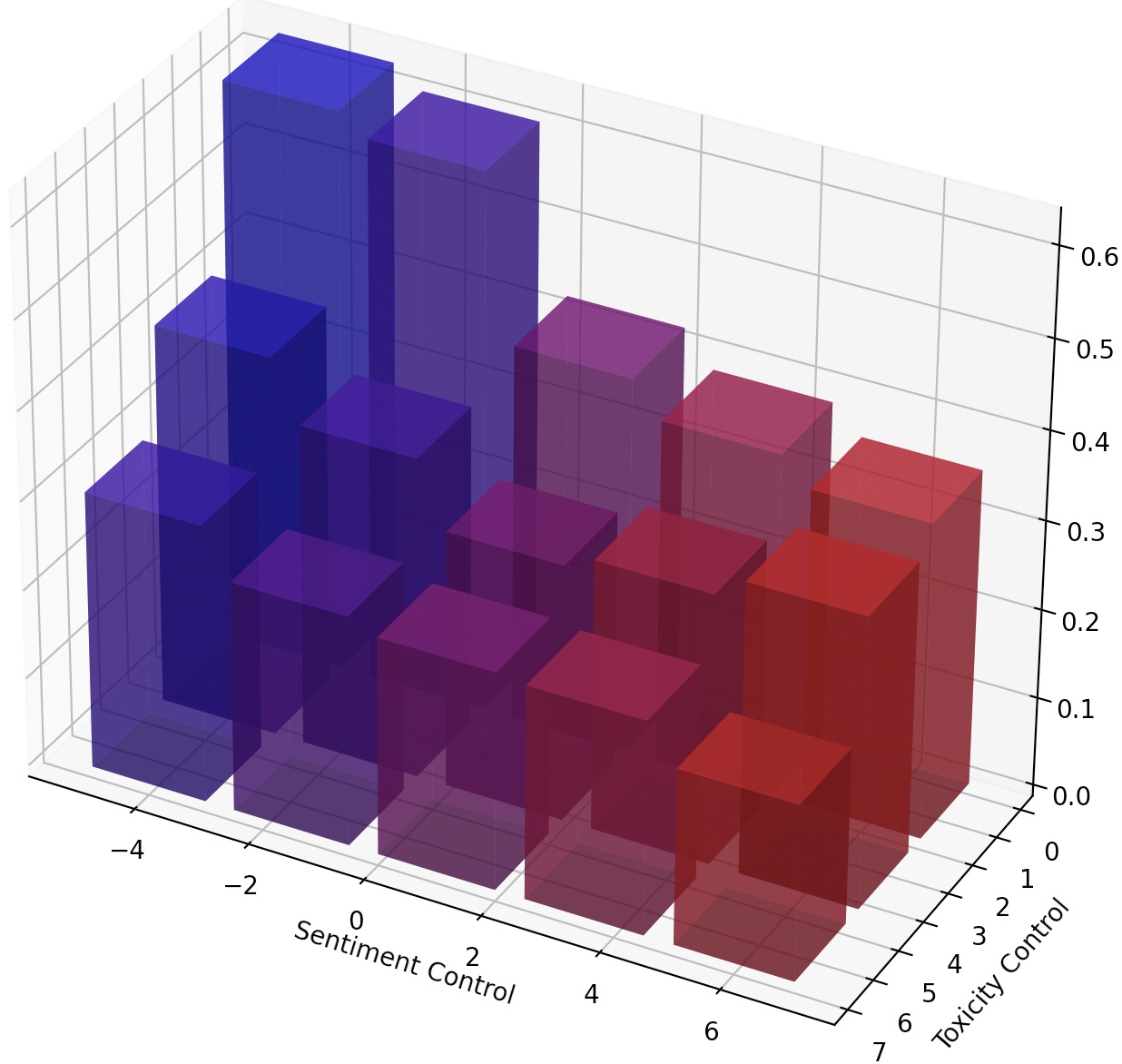
Seseorang juga dapat terus-menerus mengarahkan LMS hanya dengan menskalakan LM-Steer, atau menyusun banyak LM-steer dengan menambahkan transformasi mereka.
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
Mengikuti pengaturan di Mucola, kami mengunduh data pelatihan dari Kaggle Toxic Comment Classification Challenge. Kami menggunakan petunjuk dari repositori kode Mucola (ditempatkan di bawah data/prompts ), yang berisi permintaan untuk kontrol sentimen dan penghapusan toksisitas.
Perintah untuk memperoleh data pelatihan (Anda perlu mengatur akun Kaggle dan mengkonfigurasi kunci API Kaggle):
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
Menggunakan GPT2-Large sebagai model dasar, kami melatih LM-Steer untuk detoksifikasi.
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
File prediksi akan disimpan di logs/$TRIAL/predictions.jsonl . Kami dapat mengevaluasi prediksi menggunakan perintah berikut. Untuk mengevaluasi dengan API perspektif dari Google Cloud, Anda perlu mengatur variabel lingkungan export GOOGLE_API_KEY=xxxxxxx . Jika tidak, Anda dapat menghapus metrik "toksisitas" dari skrip evaluasi.
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
Script evaluasi akan menghasilkan hasil evaluasi ke logs/$TRIAL/result_stats.txt .
Dalam tugas ini, seseorang diminta untuk mengontrol sentimen teks yang dihasilkan dalam arah positif atau negatif. Saat mengevaluasi kemampuan menuju sentimen positif, model ini diminta pada dorongan netral dan negatif. Saat mengevaluasi kemampuan menuju sentimen negatif, model ini diminta pada dorongan netral dan positif. Jadi ada empat pengaturan evaluasi secara total. Di sini menunjukkan contoh pelatihan LM-Steer untuk kontrol sentimen negatif dan dievaluasi pada petunjuk positif.
Kode kami skor dan menggunakan kembali model terlatih, sehingga Anda dapat melatih model sekali dan mengevaluasinya beberapa kali dalam pengaturan yang berbeda tanpa pelatihan ulang.
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
Kami menggunakan experiments/pca_analysis.py untuk menafsirkan dimensi embeddings kata yang paling relevan dengan tugas detoksifikasi. Untuk menjalankan skrip, Anda perlu menentukan jalur ke pos pemeriksaan LM-Steer terlatih dan variabel lingkungan GOOGLE_API_KEY untuk API perspektif.
Harap tentukan $PATH_TO_CHECKPOINT sebagai jalur ke pos pemeriksaan LM-Steer yang terlatih.
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
Kami dapat mentransfer LM-Steer terlatih dari satu model ke model lainnya. Harap tentukan $CHECKPOINT1 sebagai jalur ke LM-Steer Checkpoint yang terlatih dan $CHECKPOINT2 sebagai jalur ke pos pemeriksaan model target. Berikut adalah contoh mentransfer LM-Steer dari GPT2-Large ke GPT2-Medium.
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
Untuk mencapai kontrol yang lebih halus atas gaya teks, kami dapat menyusun beberapa LM-steer atau terus-menerus mengarahkan LM. Untuk kemudi terus menerus, kita dapat dengan mudah mendapatkan parameter steer_values dalam skrip pelatihan, seperti --steer_values 3 1 , --steer_values 0 1 , atau --steer_values -1 1 untuk efek kemudi yang berbeda.
Untuk menyusun beberapa steer LM, Anda cukup menambahkan matriks LM-Steers dan menggunakan jumlah sebagai LM-Steer akhir. Atau, Anda dapat menggabungkan LM-Steers dan menggunakan tensor gabungan (yang merupakan daftar matriks yang lebih panjang dalam atribut self.projector1 dan self.projector2 dalam file lm_steer/models/steer.py ).
Jika Anda menemukan repositori ini bermanfaat, harap pertimbangkan mengutip makalah kami:
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


