LM Steer
1.0.0
مستودع التعليمات البرمجية الرسمية للورقة " LM-Steer: Word embedings is steers لنماذج اللغة " ( ACL 2024 جائزة الورق المتميز ) من تأليف Chi Han و Jialiang Xu و Manling Li و Yi Fung و Chenkai Sun و Nan Jiang و Tarek Abdelzaher و Heng Ji.
العرض التوضيحي الحية | ورقة | الشرائح | ملصق
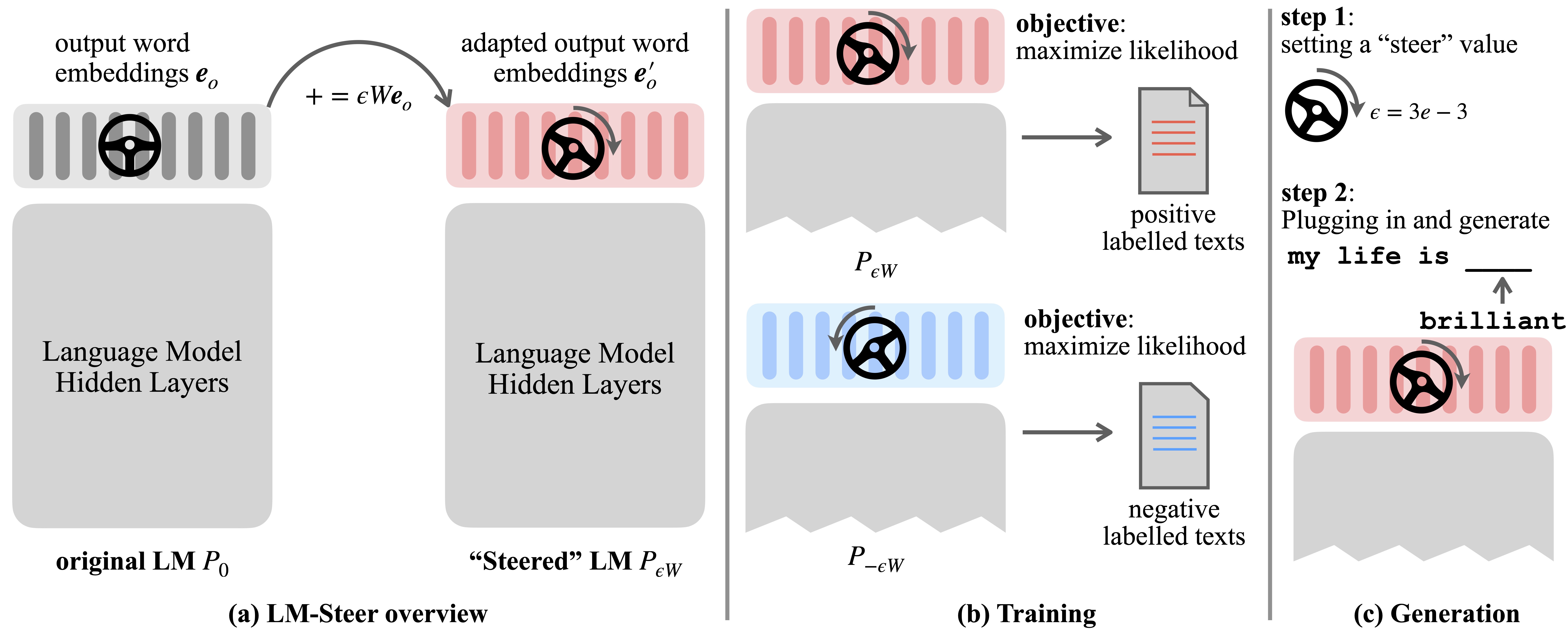
نماذج اللغة (LMS) تتعلم تلقائيًا تضمينات الكلمات أثناء التدريب قبل التدريب على اللغة. على الرغم من أن تضمينات الكلمات عادة ما يتم تفسيرها على أنها متجهات ميزة للكلمات الفردية ، إلا أن أدوارها في توليد نموذج اللغة لا تزال غير مستقرة. في هذا العمل ، نعيد نظريًا وتجريبيًا أن نعيّن التضمينات الإخراج ونجد أن التحولات الخطية الخاصة بهم تعادل أنماط توليد نموذج لغة التوجيه. نحن نسمي مثل هذه steers steers وتجدها موجودة في LMS من جميع الأحجام. يتطلب الأمر تعلم معلمات تساوي 0.2 ٪ من حجم LMS الأصلي لتوجيه كل نمط.
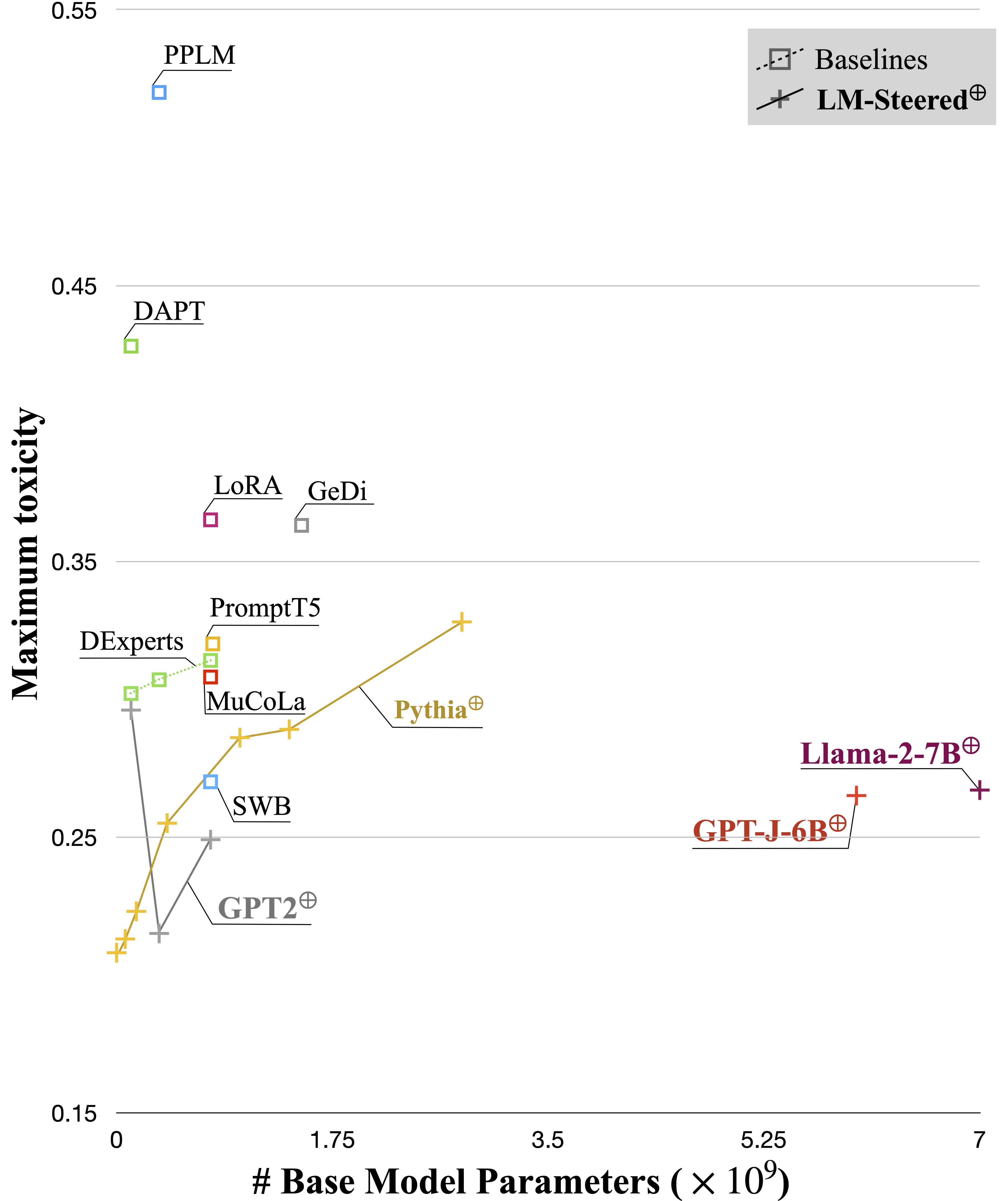

يعمل LM-Steer المستفاد كعدسة في أنماط النص: يكشف أن تضمينات الكلمات قابلة للتفسير عند الارتباط بها بأجيال نموذج اللغة ، ويمكنها تسليط الضوء على فترات النص التي تشير إلى اختلافات النمط.
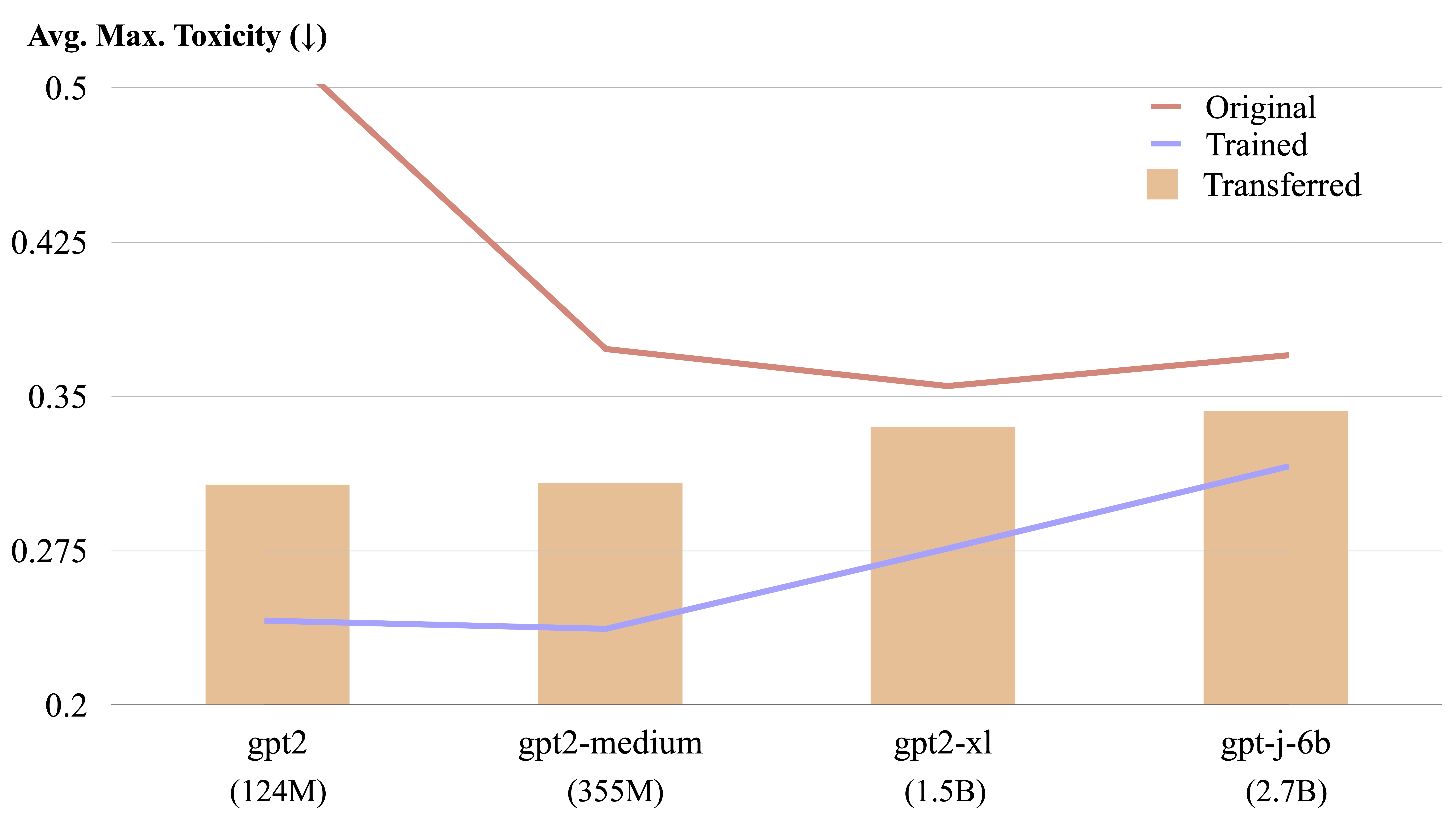
يمكن نقل LM-steer بين نماذج اللغة المختلفة عن طريق حساب صريح.
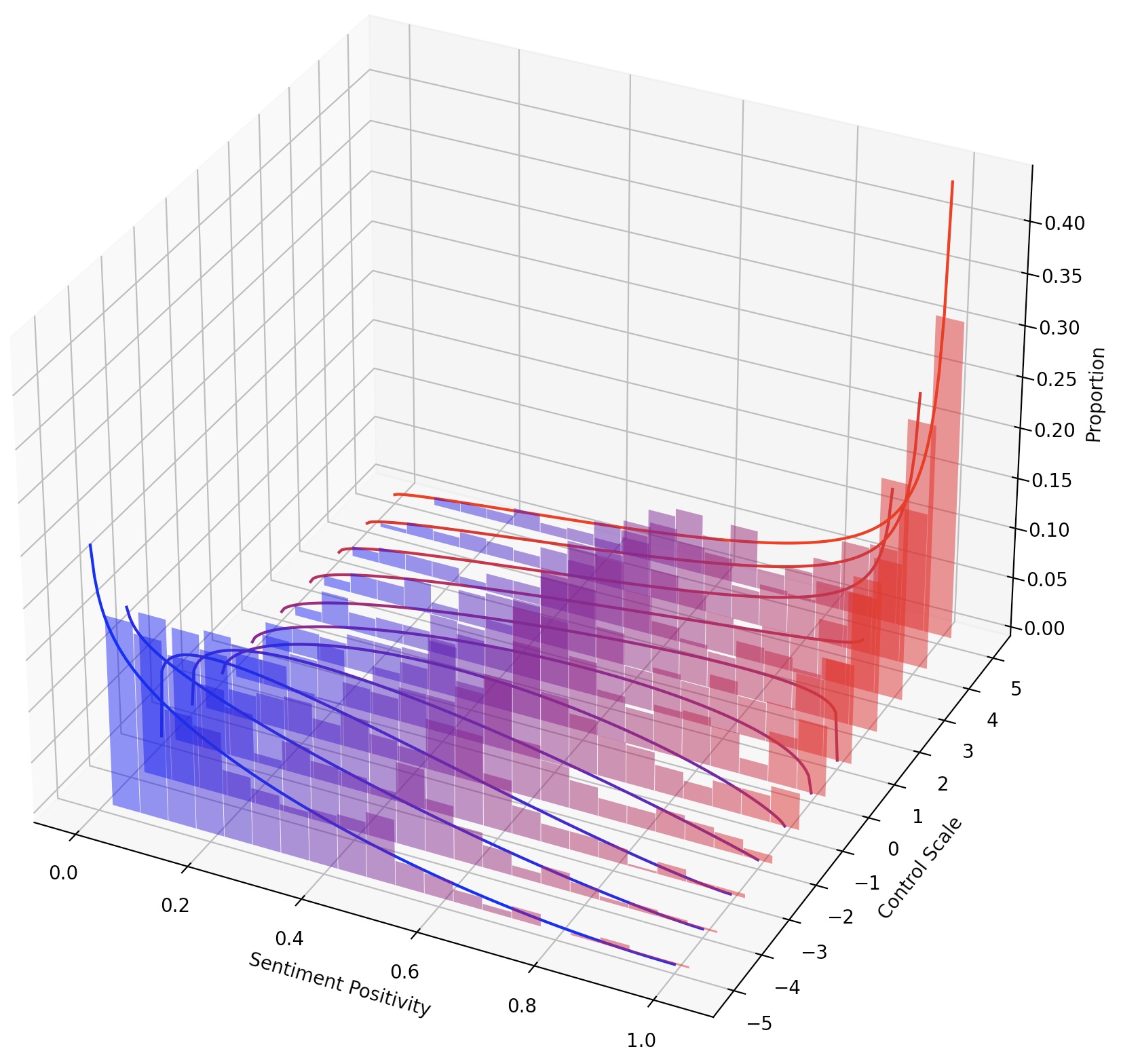
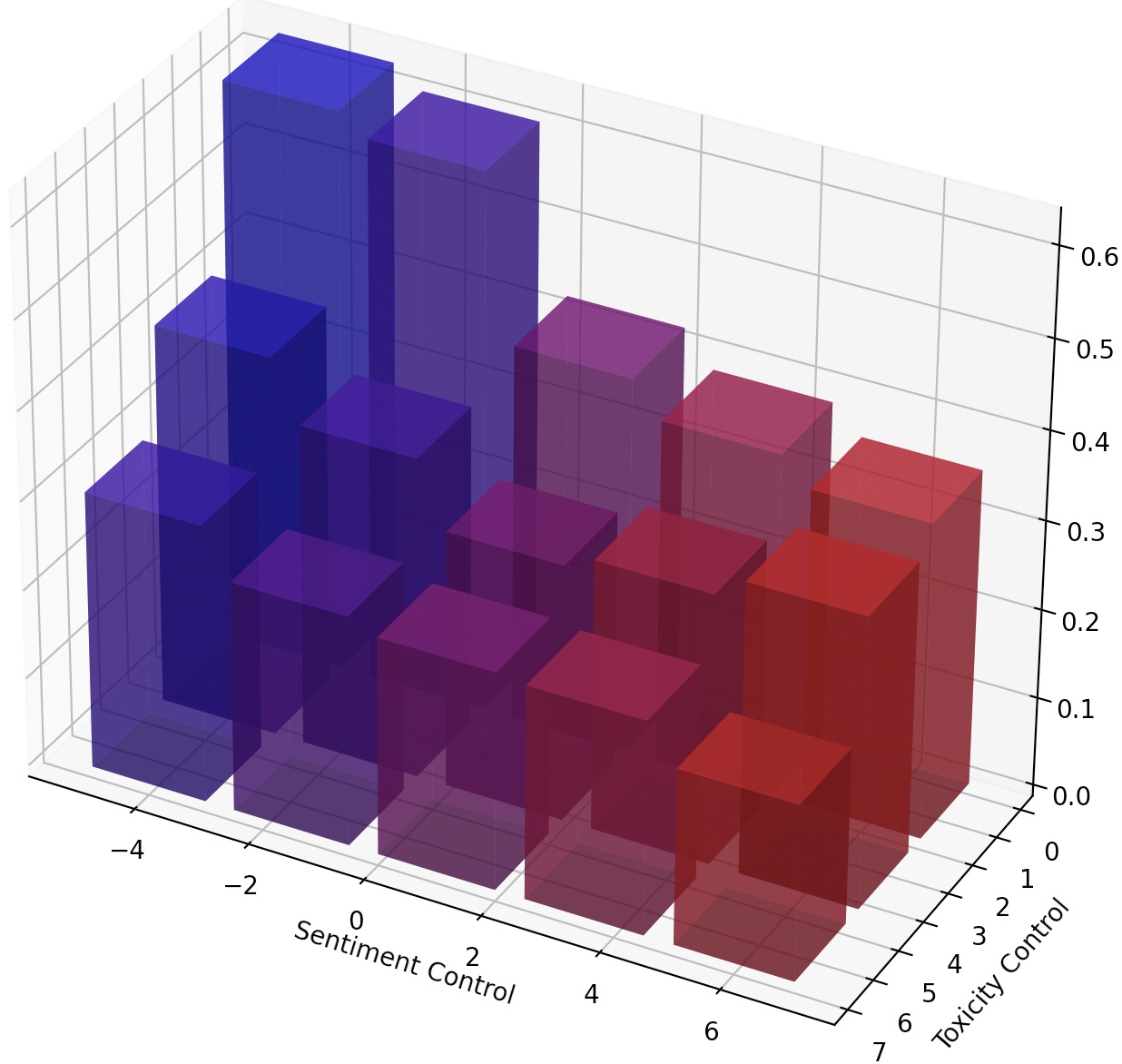
يمكن للمرء أيضًا توجيه LMS بشكل مستمر ببساطة عن طريق توسيع نطاق LM-steer ، أو تكوين عقيدة LM متعددة عن طريق إضافة تحويلاتها.
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
بعد الإعداد في Mucola ، نقوم بتنزيل بيانات التدريب من تحدي تصنيف التعليقات السامة Kaggle. نستخدم مطالبات من مستودع رمز Mucola (الموضوعة ضمن data/prompts ) ، والتي تحتوي على مطالبات للتحكم في المعنويات وإزالة السمية.
أوامر للحصول على بيانات التدريب (تحتاج إلى إعداد حساب Kaggle وتكوين مفتاح API Kaggle):
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
باستخدام GPT2-LARGE كنموذج أساسي ، نقوم بتدريب LM-steer لإزالة السموم.
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
سيتم حفظ ملف التنبؤ في logs/$TRIAL/predictions.jsonl . يمكننا تقييم التنبؤات باستخدام الأمر التالي. للتقييم باستخدام API منظور من Google Cloud ، تحتاج إلى تعيين متغير export GOOGLE_API_KEY=xxxxxxx . خلاف ذلك ، يمكنك إزالة مقياس "السمية" من البرنامج النصي للتقييم.
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
سيقوم البرنامج النصي للتقييم بإخراج نتائج التقييم إلى logs/$TRIAL/result_stats.txt .
في هذه المهمة ، يتعين على المرء التحكم في شعور النص الذي تم إنشاؤه في اتجاه إيجابي أو سلبي. عند تقييم القدرة على الشعور الإيجابي ، تتم مطالب النموذج على كل من المطالبات المحايدة والسلبية. عند تقييم القدرة على المشاعر السلبية ، تتم مطالب النموذج على كل من المطالبات المحايدة والإيجابية. لذلك هناك أربعة إعدادات تقييم في المجموع. يوضح هنا مثالًا على تدريب LM-steer للتحكم السلبي في المشاعر وتقييمه على مطالبات إيجابية.
درجات التعليمات البرمجية لدينا ونماذج إعادة استخدامها ، حتى تتمكن من تدريب نموذج مرة واحدة وتقييمه عدة مرات في إعدادات مختلفة دون إعادة التدريب.
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
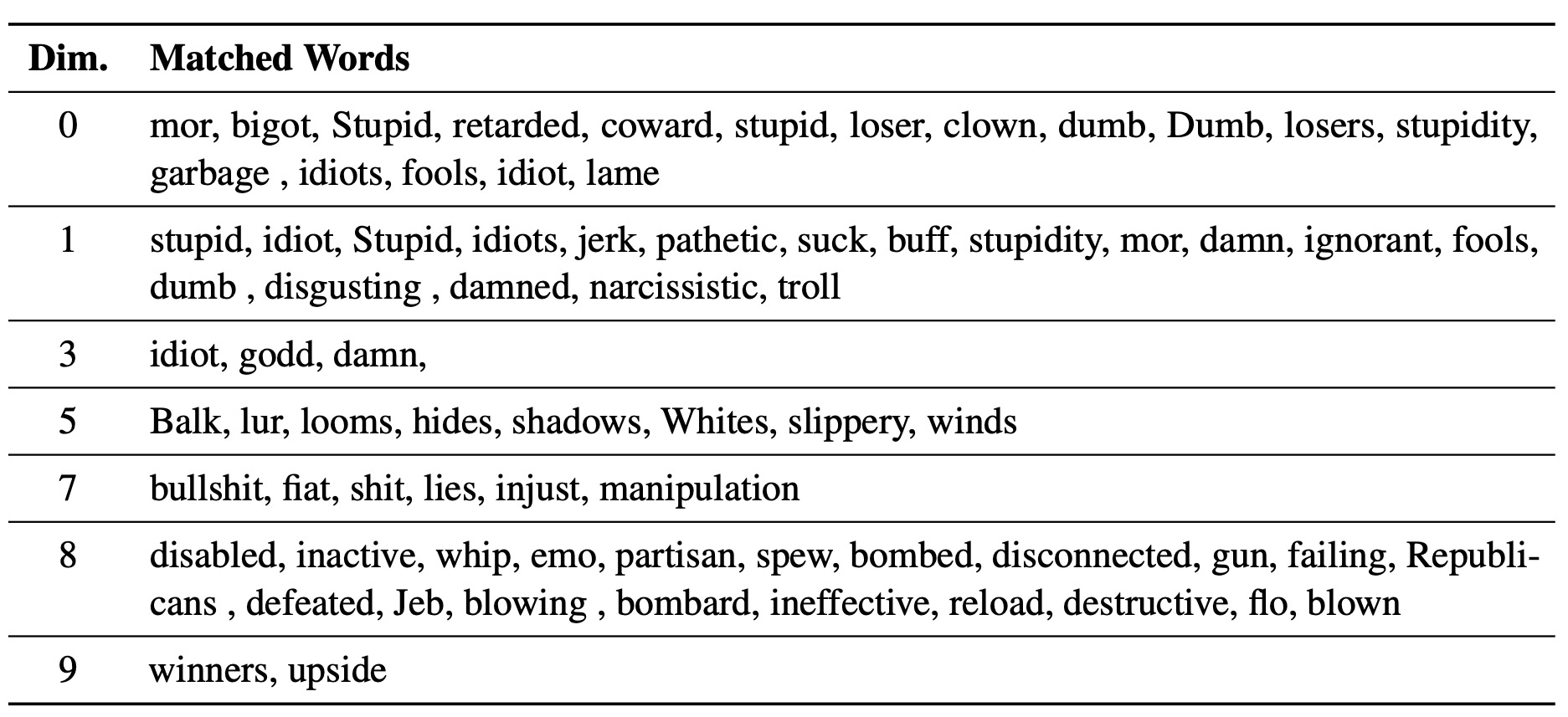
نستخدم experiments/pca_analysis.py لتفسير أبعاد تضمينات الكلمات الأكثر صلة بمهمة إزالة السموم. لتشغيل البرنامج النصي ، تحتاج إلى تحديد المسار إلى نقطة تفتيش LM-steer المدربة ومتغير بيئة GOOGLE_API_KEY في منظور API.
يرجى تحديد $PATH_TO_CHECKPOINT كمسار إلى نقطة تفتيش LM-steer المدربة.
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
يمكننا نقل LM-steer مدربة من طراز إلى آخر. يرجى تحديد $CHECKPOINT1 كمسار إلى نقطة تفتيش LM-Steer المدربة و $CHECKPOINT2 كمسار إلى نقطة تفتيش الطراز الهدف. فيما يلي مثال على نقل LM-Steer من GPT2-LARGE إلى GPT2-Medium.
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
لتحقيق عنصر تحكم أكثر حبيبات في نمط النص ، يمكننا تكوين عدة LM من LM أو توجيه LM بشكل مستمر. للتوجيه المستمر ، يمكننا ببساطة أن نتعامل مع معلمة steer_values في البرنامج النصي التدريبي ، مثل --steer_values 3 1 ، --steer_values 0 1 ، أو --steer_values -1 1 لتأثيرات التوجيه المختلفة.
لتكوين عدة LM-Steers ، يمكنك ببساطة إضافة مصفوفات LM-Steers واستخدام SUM باعتباره LM-Steer النهائي. بدلاً من ذلك ، يمكنك تسلسل أدوات LM واستخدام الموتر المتسلسل (وهو قائمة أطول من المصفوفات في سمات self.projector1 و self.projector2 في ملف lm_steer/models/steer.py ).
إذا وجدت هذا المستودع مفيدًا ، فيرجى التفكير في ذكر ورقتنا:
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


