LM Steer
1.0.0
Официальный репозиторий кода для статьи « LM-Steer: Word Enterdings-это рулевые для языковых моделей » ( ACL 2024 Award Award ) Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek Abdelzaher, Heng Ji.
Живая демонстрация | Бумага | Слайды | Плакат
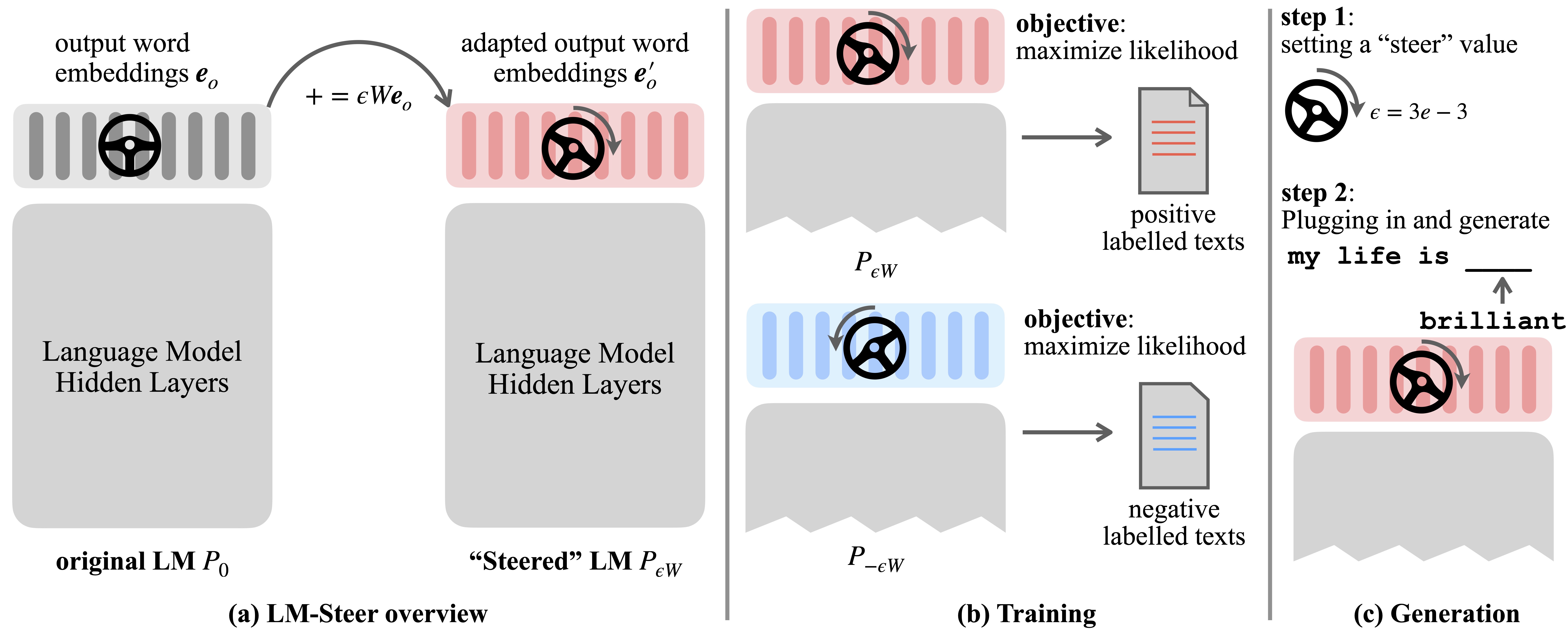
Языковые модели (LMS) автоматически изучают встраивание слов во время предварительной тренировки по языковой корпорации. Хотя встроения слов обычно интерпретируются как векторы признаков для отдельных слов, их роль в генерации языковых моделей остается недооцененной. В этой работе мы теоретически и эмпирически пересматриваем выходные слова и обнаруживаем, что их линейные преобразования эквивалентны стилям генерации моделей рулевого языка. Мы называем таких управляющих Steers и находим их существующие в LMS всех размеров. Требуются параметры обучения, равные 0,2% от исходного размера LMS для управления каждым стилем.
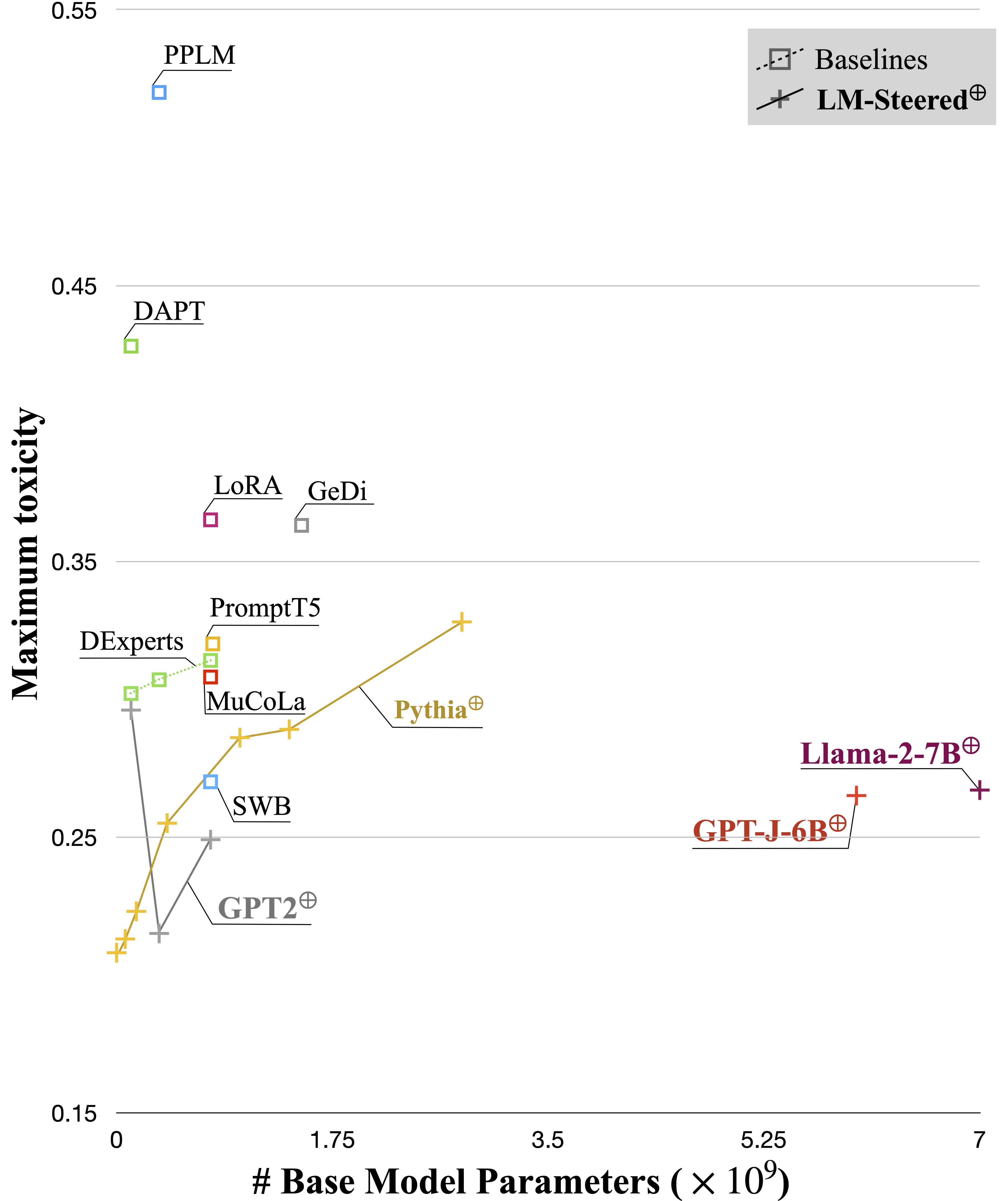
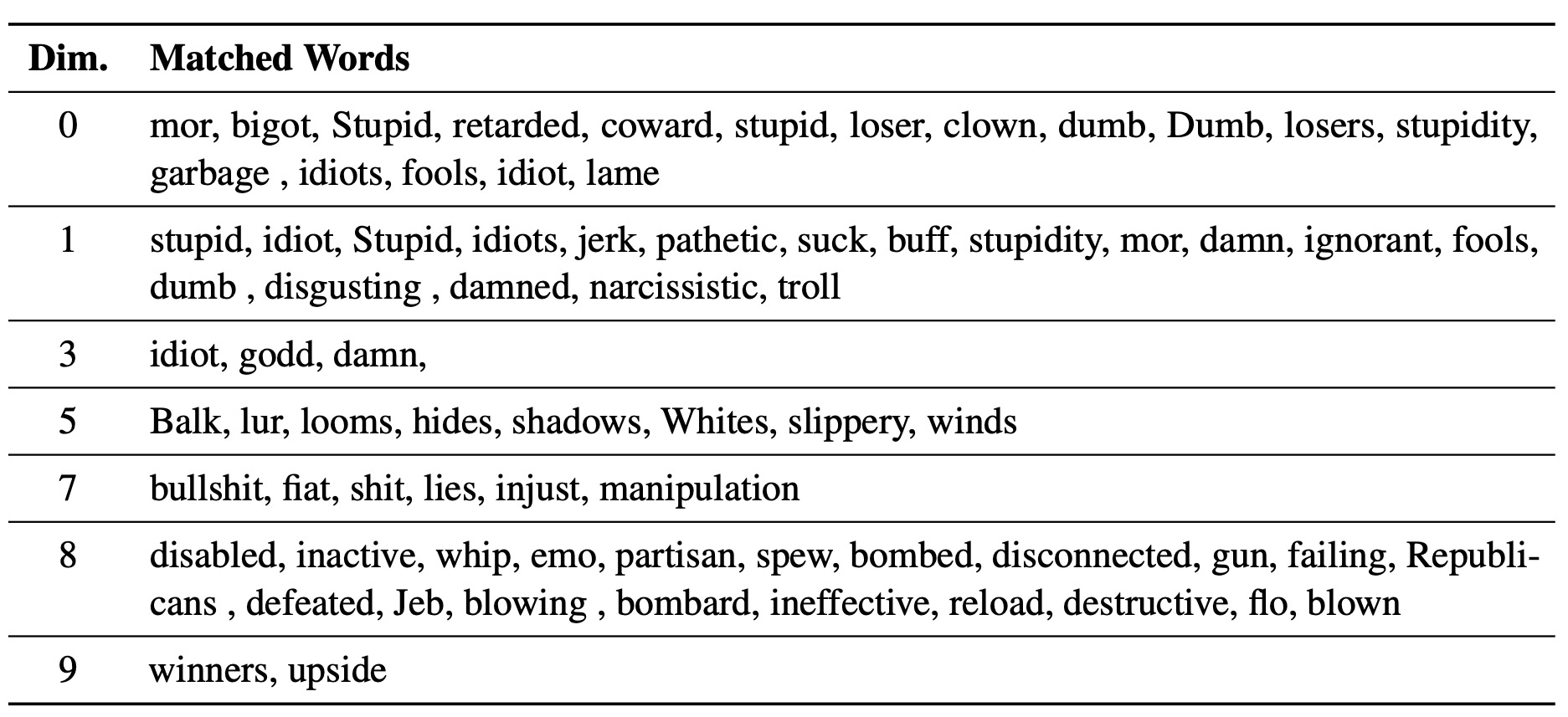

Ученый LM-Steer служит объективом в стилях текста: он показывает, что встроения слов интерпретируются, когда связаны с поколениями языковых моделей, и могут выделять текстовые промежутки, которые наиболее указывают различия в стиле.
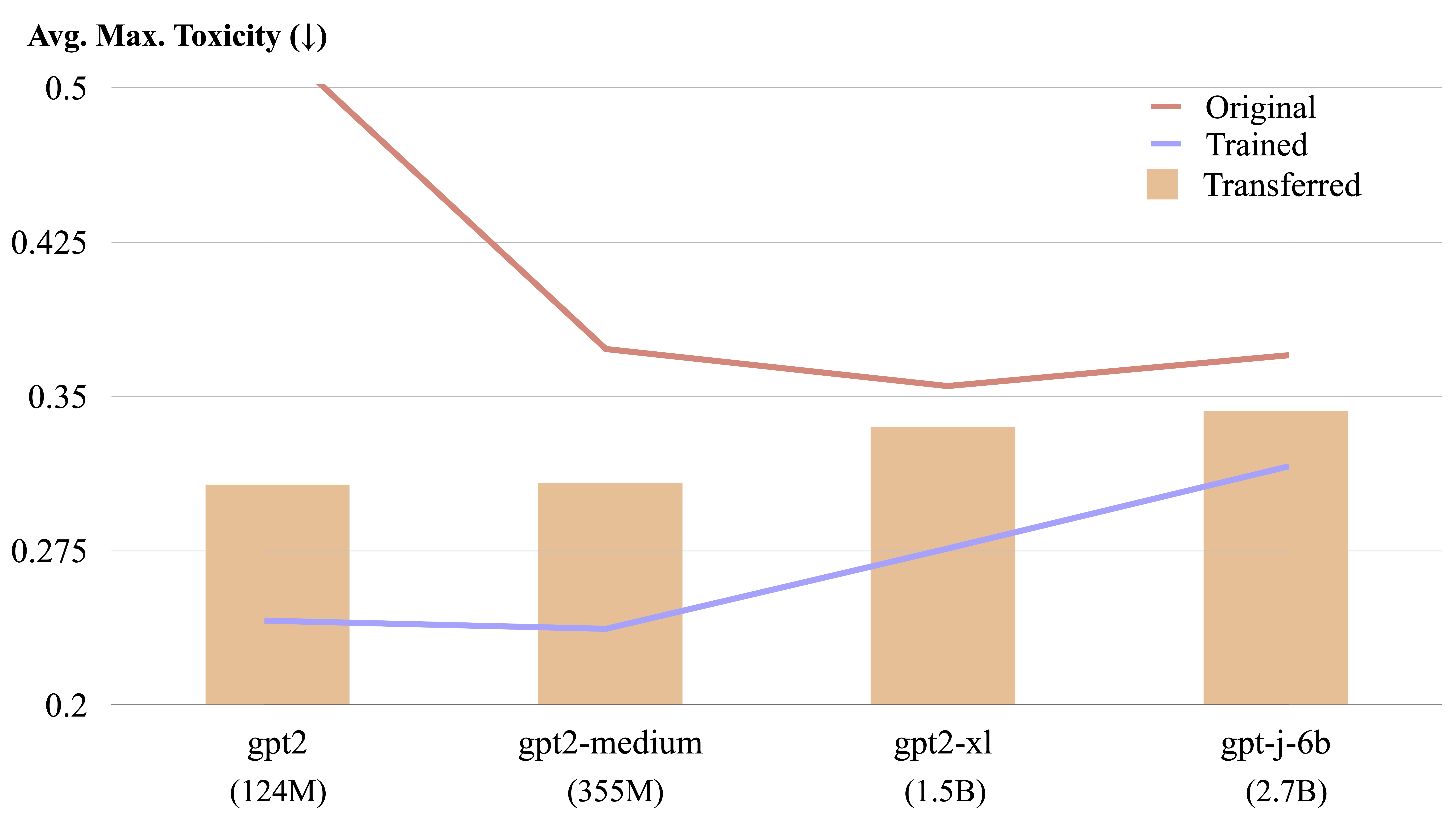
LM-Steer передается между различными языковыми моделями с помощью расчета явного формы.
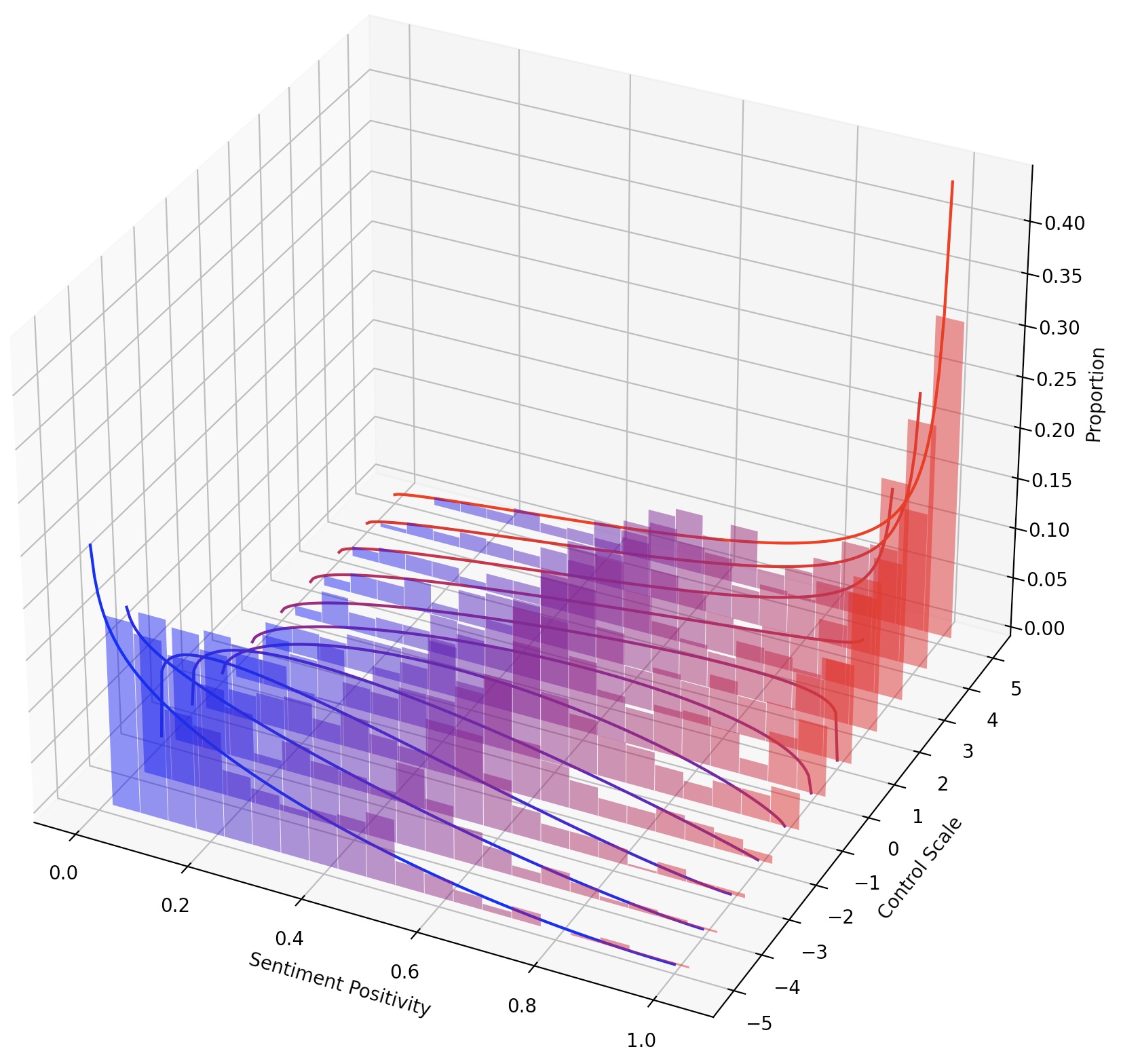
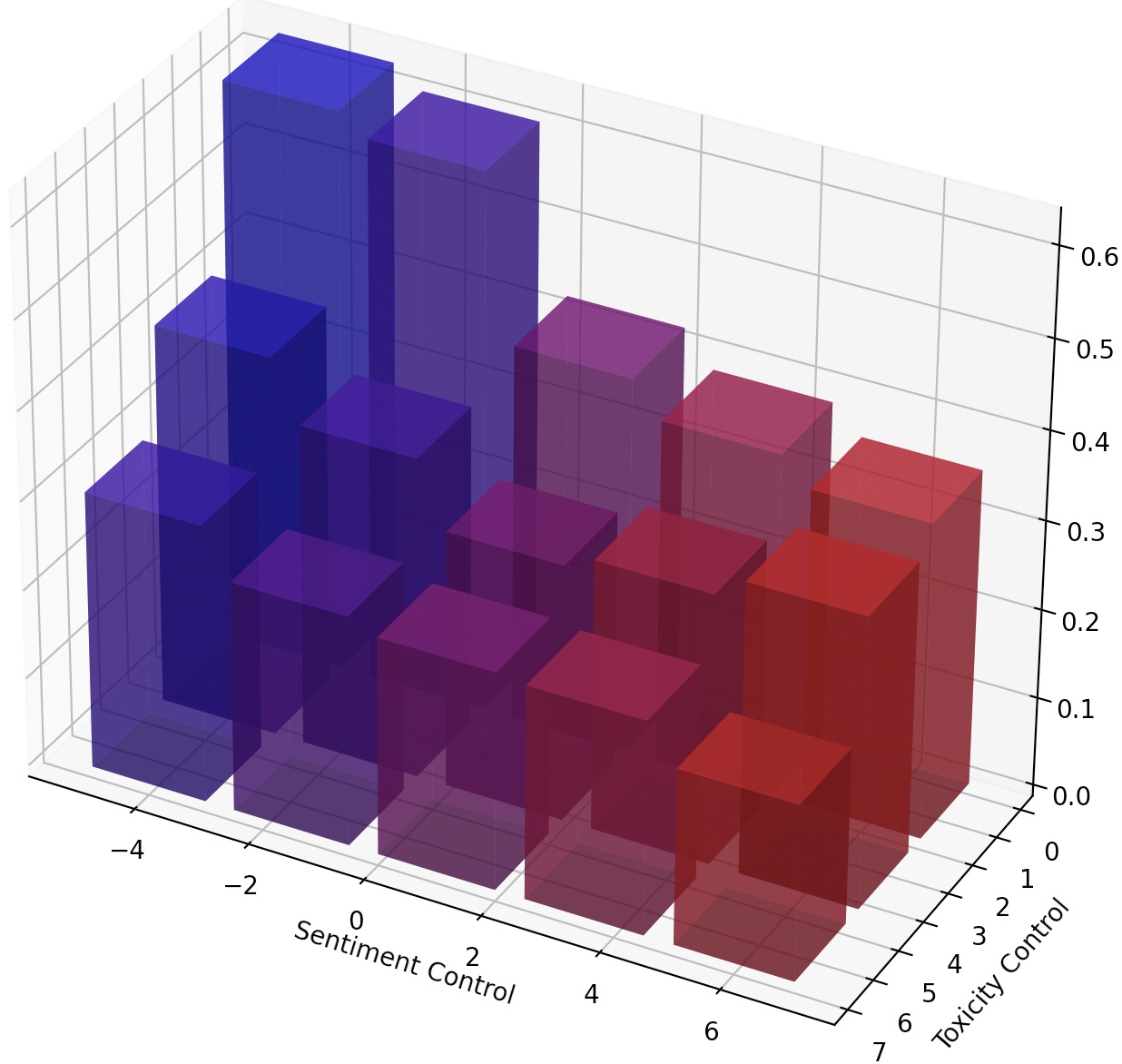
Можно также непрерывно направлять LMS, просто масштабируя LM-Steer, или составив несколько LM-стекло, добавив их преобразования.
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
После настройки в Mucola мы загружаем учебные данные из задачи классификации токсичных комментариев Kaggle. Мы используем подсказки из репозитория кода Mucola (размещенные в соответствии с data/prompts ), который содержит подсказки для контроля настроения и удаления токсичности.
Команды для получения данных обучения (вам нужно настроить учетную запись Kaggle и настроить ключ Kaggle API):
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
Используя GPT2-Large в качестве базовой модели, мы тренируем LM-Steer для детоксикации.
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
Файл прогнозирования будет сохранен в logs/$TRIAL/predictions.jsonl . Мы можем оценить прогнозы, используя следующую команду. Чтобы оценить с перспективным API из Google Cloud, вам необходимо установить export GOOGLE_API_KEY=xxxxxxx переменная среды. В противном случае вы можете удалить метрику «токсичности» из сценария оценки.
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
Сценарий оценки выведет результаты оценки в logs/$TRIAL/result_stats.txt .
В этой задаче необходимо управлять чувством сгенерированного текста в положительном или отрицательном направлении. При оценке способности к положительному настроению модель подразумевается как на нейтральных, так и на отрицательных подсказках. При оценке способности к отрицательному настроению модель подручается как на нейтральных, так и на положительных подсказках. Таким образом, в общей сложности есть четыре настройки оценки. Здесь показан пример обучения LM-Steer для контроля отрицательных настроений и оценивается по положительным подсказкам.
Наш код оценивает и повторно использует обученные модели, поэтому вы можете тренировать модель один раз и оценить ее несколько раз в разных настройках без повторного обучения.
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
Мы используем experiments/pca_analysis.py для интерпретации измерений встроенных слов, которые наиболее актуальны для задачи детоксикации. Чтобы запустить сценарий, вам необходимо указать путь к обученной контрольной точке LM-Steer и переменной среды GOOGLE_API_KEY для перспективного API.
Пожалуйста, укажите $PATH_TO_CHECKPOINT в качестве пути к обученной контрольной точке LM-Steer.
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
Мы можем перенести обученный LM-Стир из одной модели в другую. Пожалуйста, укажите $CHECKPOINT1 в качестве пути к обученной контрольной точке LM-Steer и $CHECKPOINT2 в качестве пути к контрольной точке целевой модели. Вот пример передачи LM-Steer от GPT2-Large в GPT2-Medium.
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
Чтобы достичь более мелкозернистого контроля над текстовым стилем, мы можем составить несколько LM-стеклов или непрерывно управлять LM. Для непрерывного рулевого управления мы можем просто подтолкнуть параметр steer_values в учебном сценарии, например, --steer_values 3 1 , --steer_values 0 1 или --steer_values -1 1 для различных эффектов рулевого управления.
Для составления нескольких LM-стеклох вы можете просто добавить матрицы LM-стереров и использовать сумму в качестве окончательного LM-Steer. В качестве альтернативы, вы можете объединить LM-стелы и использовать конкатенированный тензор (который представляет собой более длинный список матриц в атрибутах self.projector1 и self.projector2 в файле lm_steer/models/steer.py ).
Если вы обнаружите этот репозиторий полезным, пожалуйста, рассмотрите возможность ссылаться на нашу статью:
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


