LM Steer
1.0.0
Référentiel de code officiel pour l'article " LM-Steer: Word Embeddings sont des bouvillons pour les modèles de langues " ( ACL 2024 Outstanding Paper Award ) par Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek Abdelzaher, Heng Ji.
Démo en direct | Papier | Diapositives | Affiche
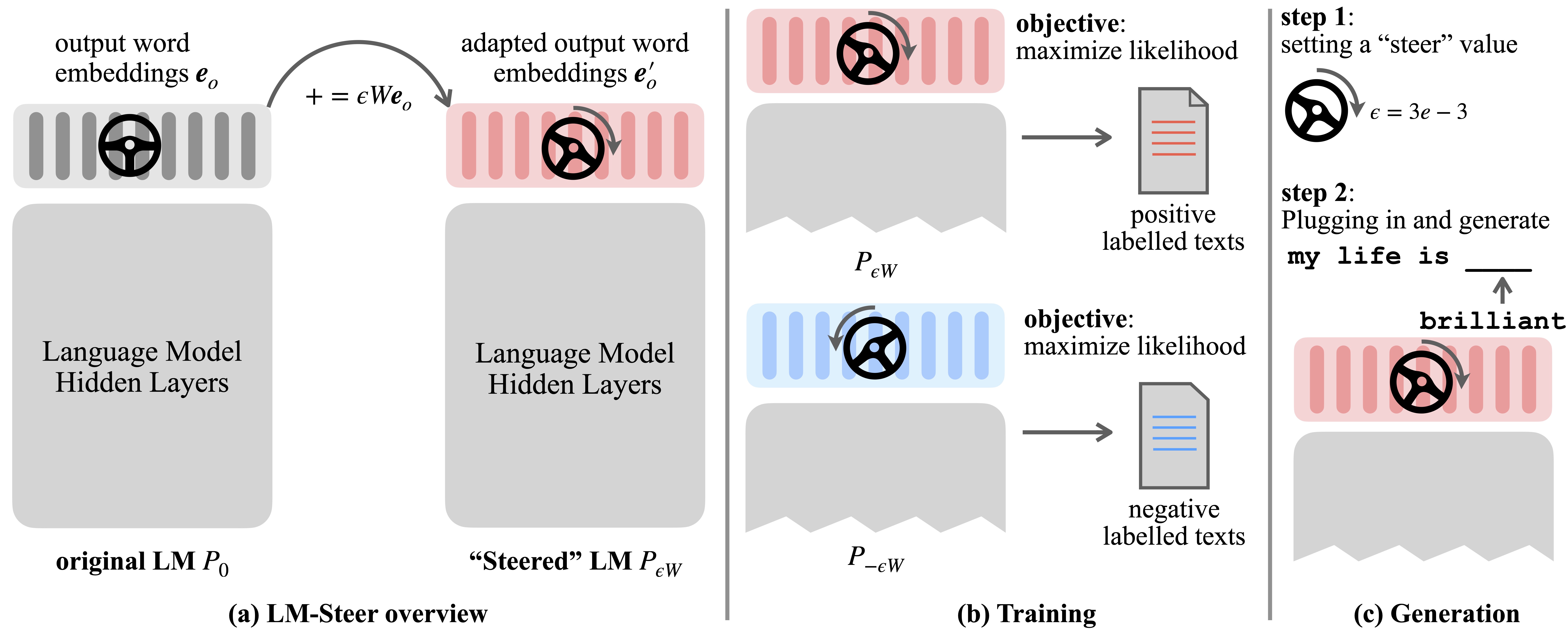
Les modèles linguistiques (LMS) apprennent automatiquement les incorporations de mots lors de la pré-formation sur les corpus linguistiques. Bien que les incorporations de mots soient généralement interprétées comme des vecteurs de caractéristiques pour les mots individuels, leur rôle dans la génération de modèles de langage reste sous-exploré. Dans ce travail, nous révisons théoriquement et empiriquement les incorporations de mots de sortie et constatons que leurs transformations linéaires sont équivalentes aux styles de génération de modèles de langage de direction. Nous nommons de tels dirigeants LM-Steers et les trouvons existant dans LMS de toutes tailles. Il nécessite des paramètres d'apprentissage égaux à 0,2% de la taille de LMS d'origine pour la direction de chaque style.
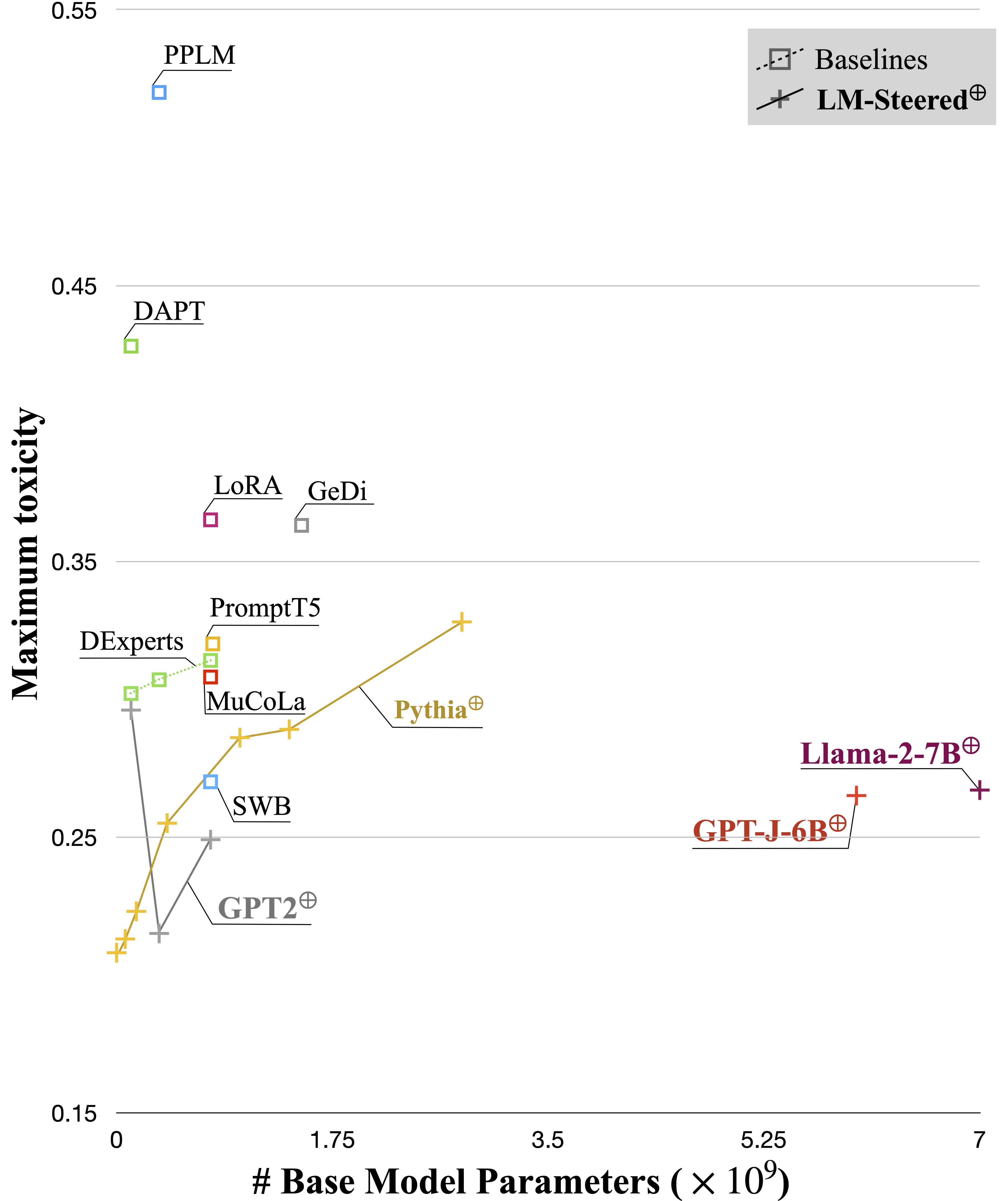
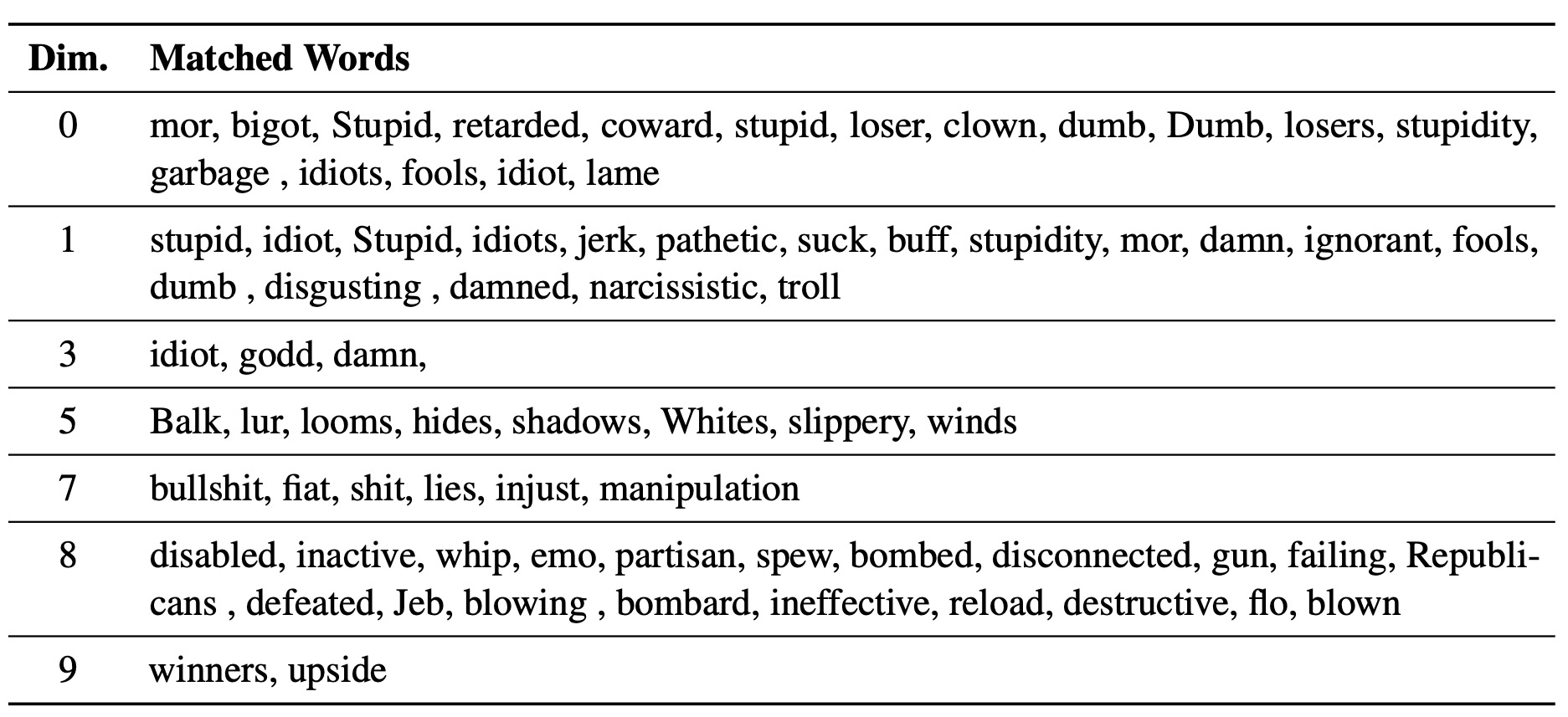

Le savant LM-Steer sert d'objectif dans les styles de texte: il révèle que les incorporations de mots sont interprétables lorsqu'elles sont associées aux générations du modèle de langue, et peuvent mettre en évidence des travées de texte qui indiquent le plus les différences de style.
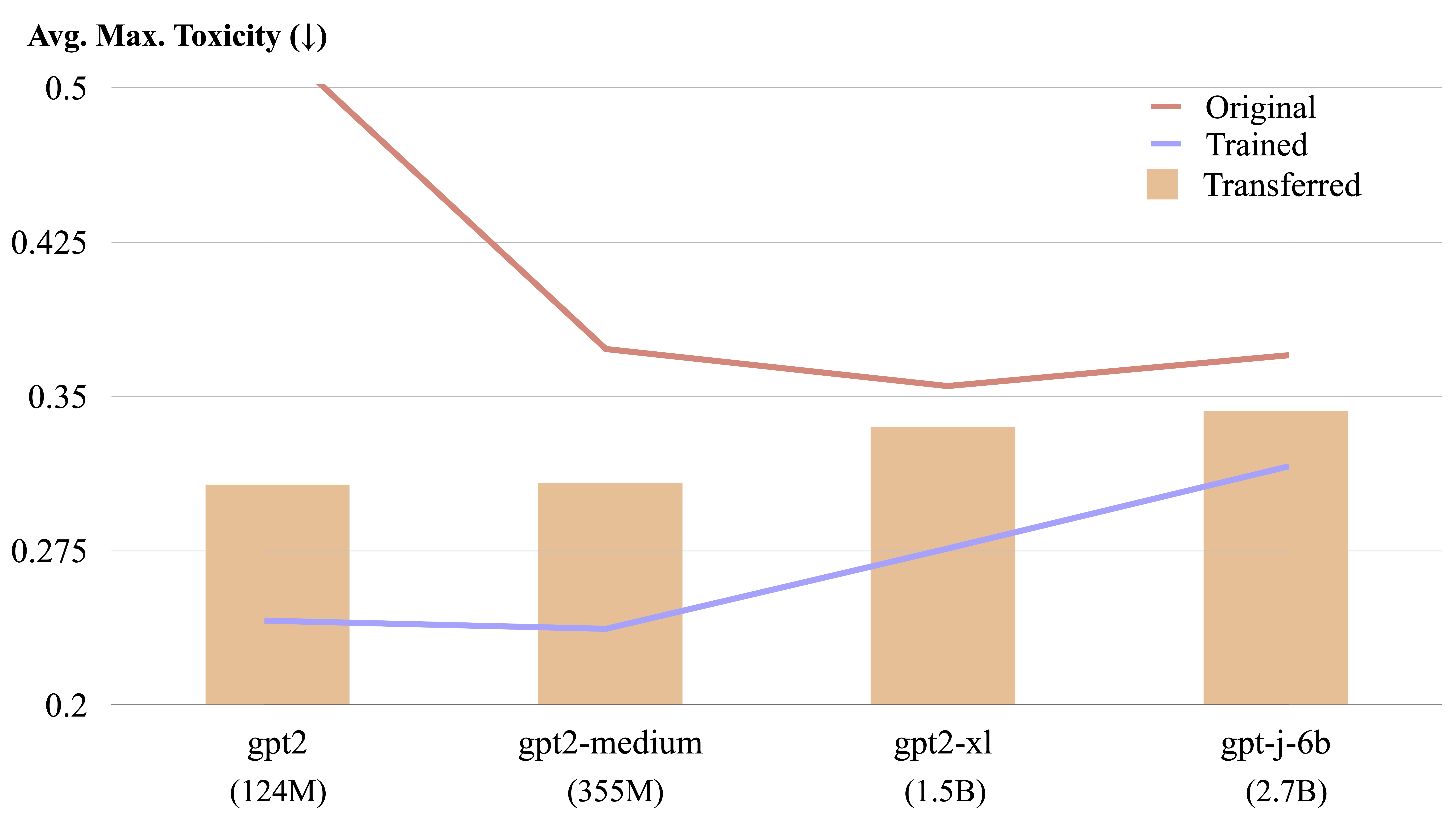
Un steer LM est transférable entre différents modèles de langage par un calcul de forme explicite.
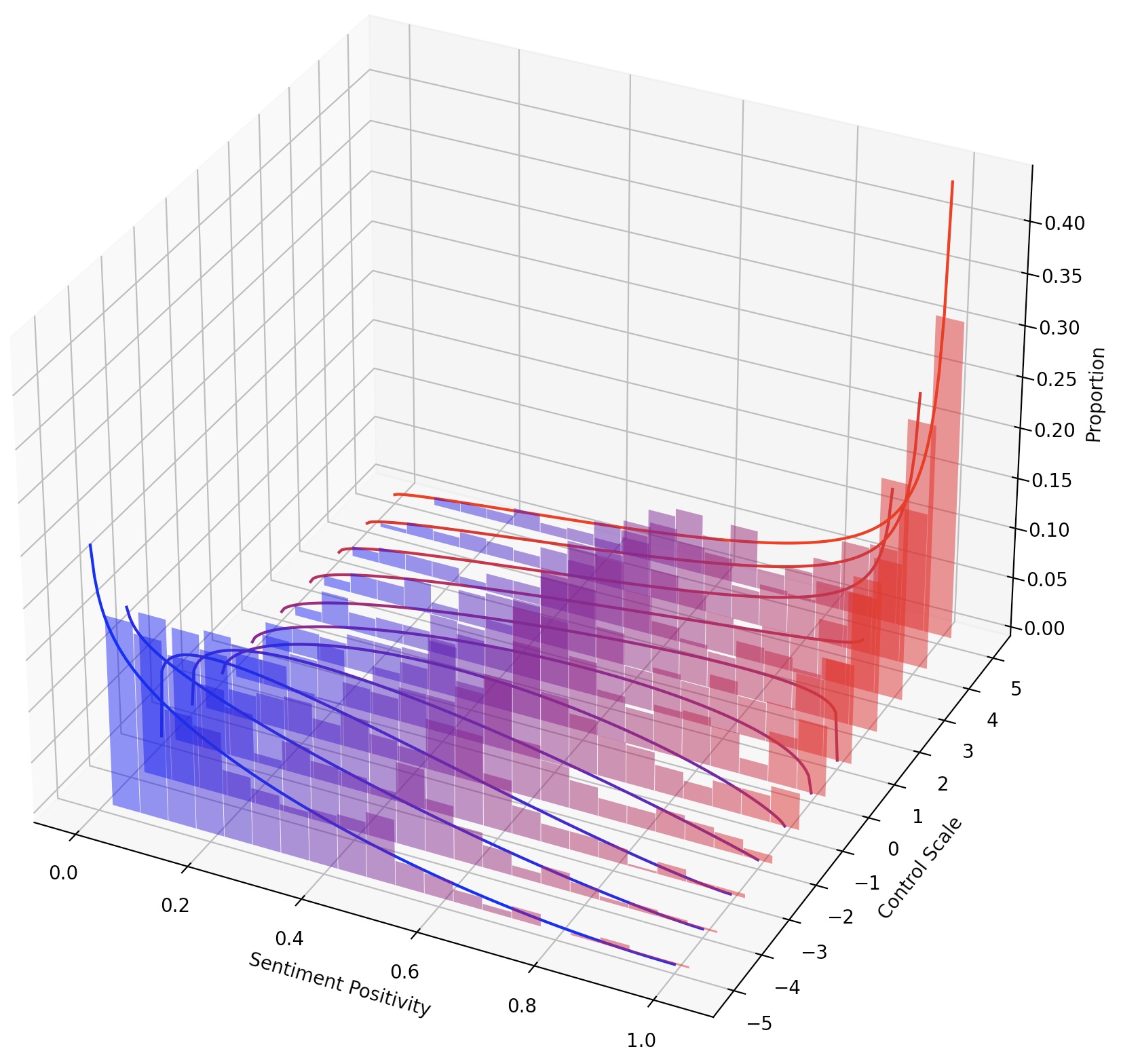
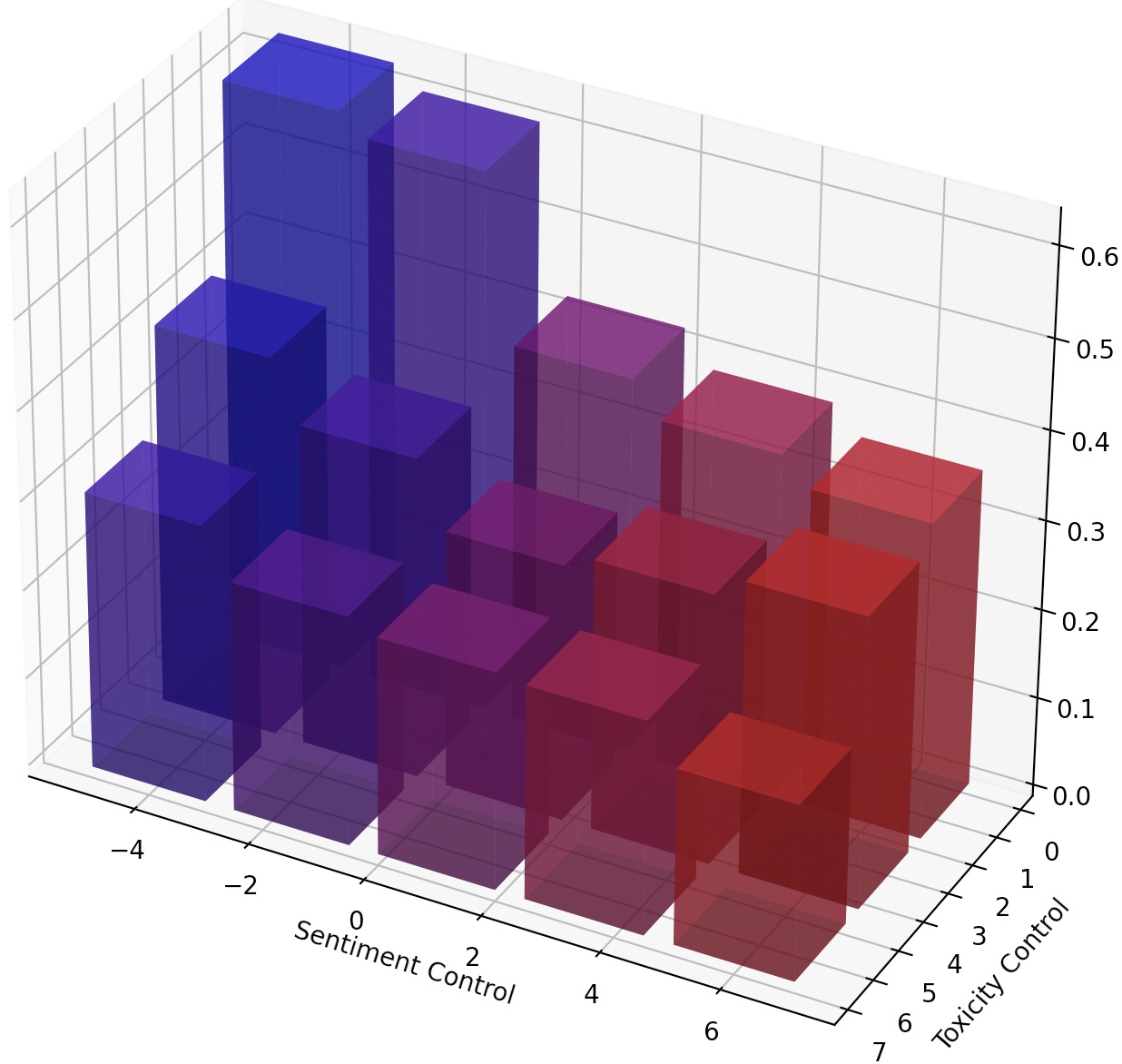
On peut également diriger en permanence LMS simplement en élargissant le steer LM, ou composer plusieurs steers LM en ajoutant leurs transformations.
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
Après le décor dans Mucola, nous téléchargeons les données de formation de Kaggle Toxic Commentaire Classification Challenge. Nous utilisons des invites du référentiel de code de Mucola (placée sous data/prompts ), qui contient des invites pour le contrôle des sentiments et l'élimination de la toxicité.
Commandes pour acquérir des données de formation (vous devez configurer un compte Kaggle et configurer la touche API Kaggle):
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
En utilisant GPT2-GARD comme modèle de base, nous formons un steer LM pour la détoxification.
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
Le fichier de prédiction sera enregistré sur logs/$TRIAL/predictions.jsonl . Nous pouvons évaluer les prédictions en utilisant la commande suivante. Pour évaluer avec l'API Perspective de Google Cloud, vous devez définir la variable d'environnement export GOOGLE_API_KEY=xxxxxxx . Sinon, vous pouvez supprimer la métrique "toxicité" du script d'évaluation.
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
Le script d'évaluation sortira les résultats de l'évaluation aux logs/$TRIAL/result_stats.txt .
Dans cette tâche, on est nécessaire pour contrôler le sentiment du texte généré dans une direction positive ou négative. Lors de l'évaluation de la capacité vers un sentiment positif, le modèle est invité à des invites neutres et négatives. Lors de l'évaluation de la capacité vers un sentiment négatif, le modèle est invité à des invites neutres et positives. Il y a donc quatre paramètres d'évaluation au total. Ici montre un exemple de formation d'un steer LM pour le contrôle négatif des sentiments et évalué sur des invites positives.
Notre code marque et réutilise les modèles formés, vous pouvez donc former un modèle une fois et l'évaluer plusieurs fois dans différents paramètres sans reconstitution.
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
Nous utilisons les experiments/pca_analysis.py pour interpréter les dimensions d'intégration des mots qui sont les plus pertinentes pour la tâche de détoxification. Pour exécuter le script, vous devez spécifier le chemin du chemin vers le point de contrôle LM-Steer formé et la variable d'environnement GOOGLE_API_KEY pour l'API Perspective.
Veuillez spécifier $PATH_TO_CHECKPOINT comme chemin vers le point de contrôle LM-Steer formé.
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
Nous pouvons transférer un steer LM formé d'un modèle à un autre. Veuillez spécifier $CHECKPOINT1 comme chemin vers le point de contrôle LM-Steer formé et $CHECKPOINT2 comme chemin vers le point de contrôle du modèle cible. Voici un exemple de transfert d'un steer LM de GPT2-grand à GPT2-Medium.
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
Pour obtenir un contrôle plus fin sur le style de texte, nous pouvons composer plusieurs steers LM ou diriger en continu le LM. Pour la direction continue, nous pouvons simplement ajuster le paramètre steer_values dans le script d'entraînement, tel que --steer_values 3 1 , --steer_values 0 1 , ou --steer_values -1 1 pour différents effets de direction.
Pour composer plusieurs steers LM, vous pouvez simplement ajouter les matrices des LM-Steers et utiliser la somme comme steer LM final. Alternativement, vous pouvez concaténer les LM-Steers et utiliser le tenseur concaténé (qui est une liste plus longue des matrices dans les attributs self.projector1 et self.projector2 dans le fichier lm_steer/models/steer.py ).
Si vous trouvez ce référentiel utile, veuillez envisager de citer notre papier:
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


