LM Steer
1.0.0
論文の公式コードリポジトリ「 LM-steer:Word Embeddingsは言語モデルのステアです」( ACL 2024未解決の論文賞)Chi Han、Jialiang Xu、Manling Li、Yi Fung、Chenkai Sun、Nan Jiang、Tarek Abdelzaher、Heng Ji。
ライブデモ|論文|スライド|ポスター
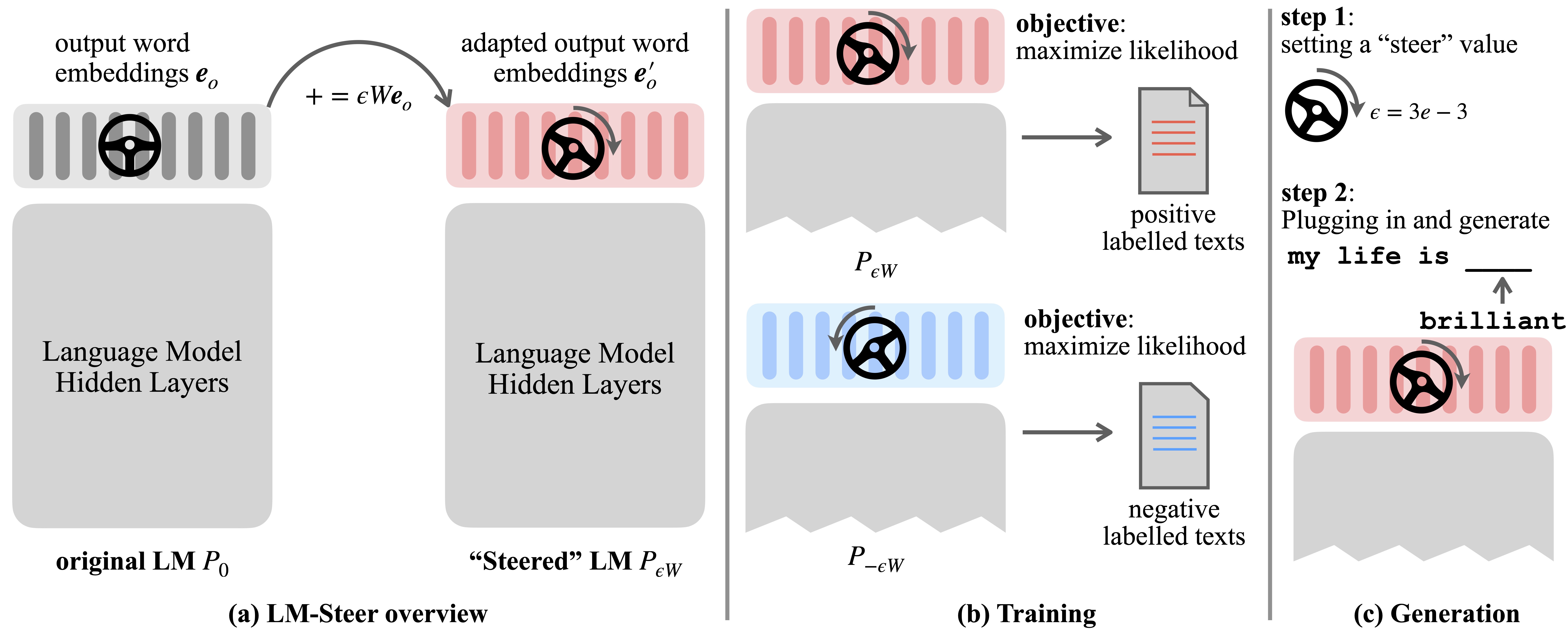
言語モデル(LMS)は、言語コーパスの事前トレーニング中に単語の埋め込みを自動的に学習します。単語の埋め込みは通常、個々の単語の特徴ベクトルとして解釈されますが、言語モデル生成におけるその役割は露出度の低いままです。この作業では、理論的および経験的に出力ワードの埋め込みを再検討し、それらの線形変換がステアリング言語モデル生成スタイルと同等であることを発見します。このようなステアズLM-Steersに名前を付け、あらゆるサイズのLMSに存在していることがわかります。各スタイルをステアリングするには、元のLMSのサイズの0.2%に等しい学習パラメーターが必要です。

学習したLM-steerは、テキストスタイルのレンズとして機能します。単語の埋め込みは、言語モデルの世代に関連付けられている場合に解釈可能であり、スタイルの違いを最も示すテキストスパンを強調できることを明らかにします。
LMステアは、明示的な形式の計算により、異なる言語モデル間で転送可能です。
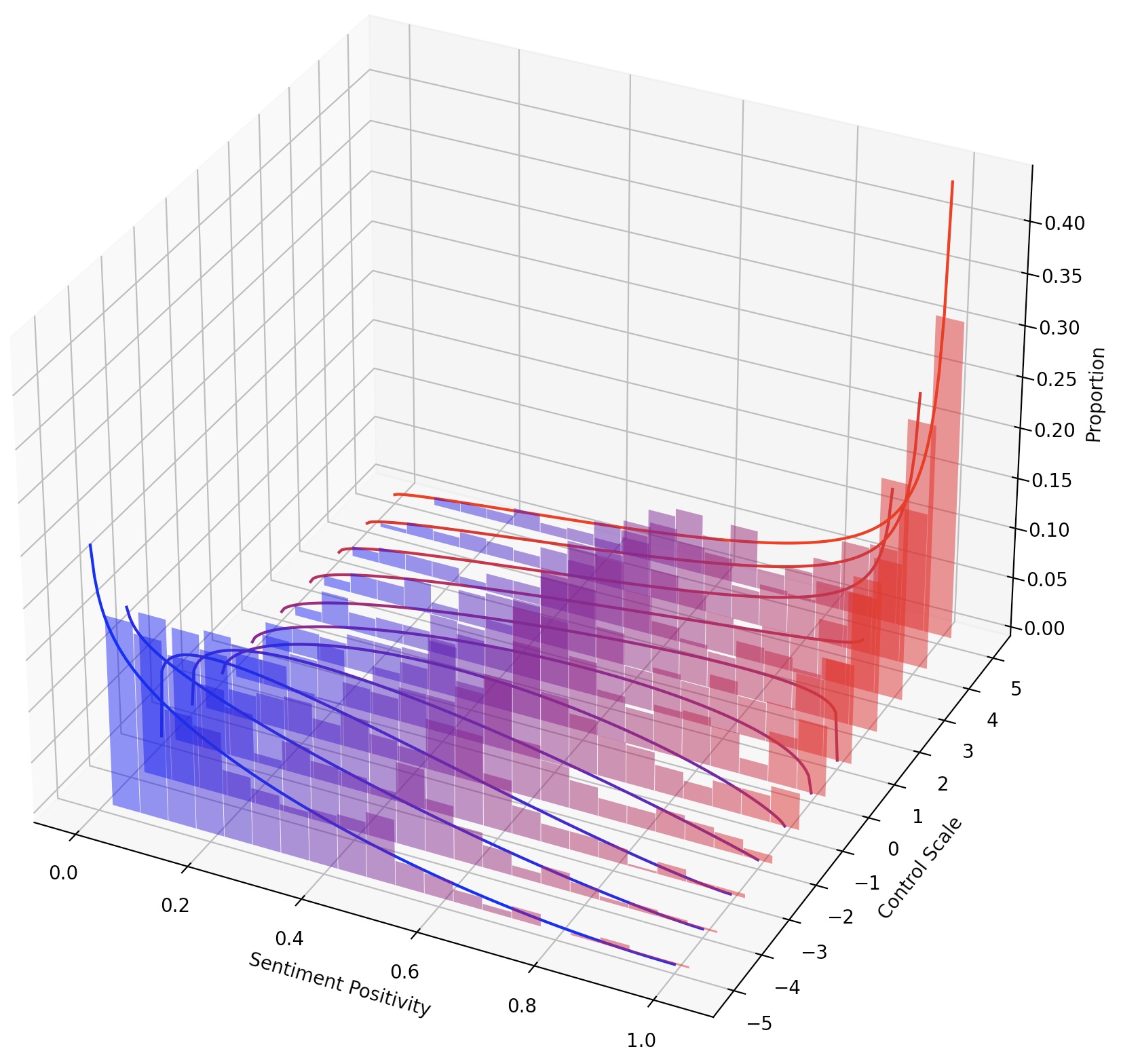
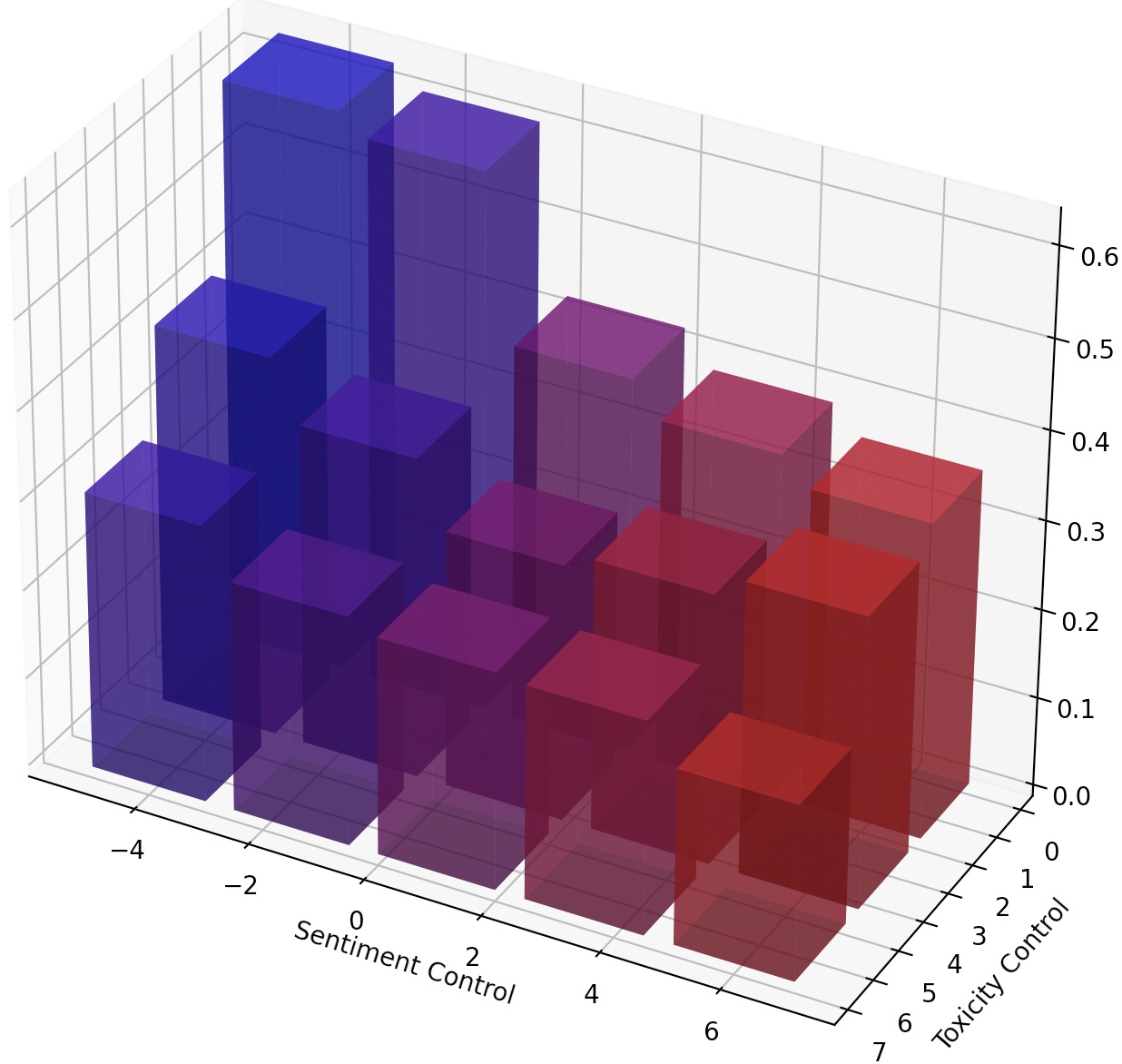
また、LM-SteerをスケーリングするだけでLMSを継続的に操縦したり、変換を追加して複数のLMステアを作成することもできます。
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
Mucolaの設定に続いて、Kaggle Toxic Comment Comment Conglearge Challengeからトレーニングデータをダウンロードします。 Mucolaのコードリポジトリ( data/promptsの下に配置)のプロンプトを使用します。これには、感情制御と毒性除去のプロンプトが含まれています。
トレーニングデータを取得するためのコマンド(Kaggleアカウントを設定し、Kaggle APIキーを構成する必要があります):
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
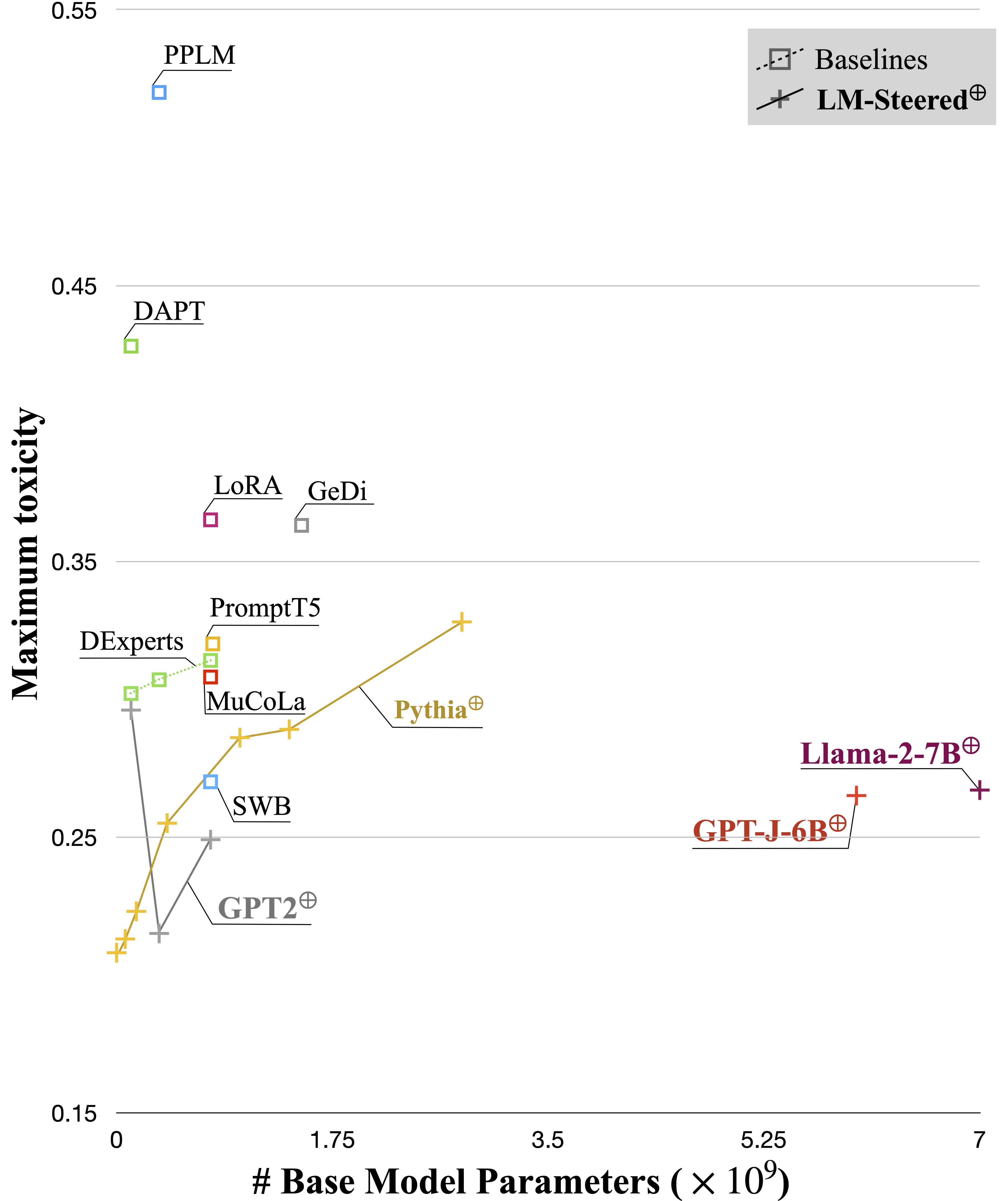
GPT2-Largeを基本モデルとして使用して、解毒のためにLMステアを訓練します。
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
予測ファイルはlogs/$TRIAL/predictions.jsonlに保存されます。次のコマンドを使用して予測を評価できます。 Google CloudのPerspective APIで評価するには、 export GOOGLE_API_KEY=xxxxxxxする必要があります。それ以外の場合は、評価スクリプトから「毒性」メトリックを削除できます。
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
評価スクリプトは、評価結果をlogs/$TRIAL/result_stats.txtに出力します。
このタスクでは、生成されたテキストの感情を正または負の方向に制御するために必要です。肯定的な感情に向けて能力を評価するとき、モデルは中立プロンプトと負のプロンプトの両方で促されます。否定的な感情に向けて能力を評価するとき、モデルは中立と正の両方のプロンプトの両方で促されます。したがって、合計で4つの評価設定があります。ここでは、否定的な感情制御のためにLMステアをトレーニングし、肯定的なプロンプトで評価された例を示しています。
コードスコアとトレーニングモデルを再利用するため、モデルを一度トレーニングして、再トレーニングをせずに異なる設定で複数回評価できます。
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
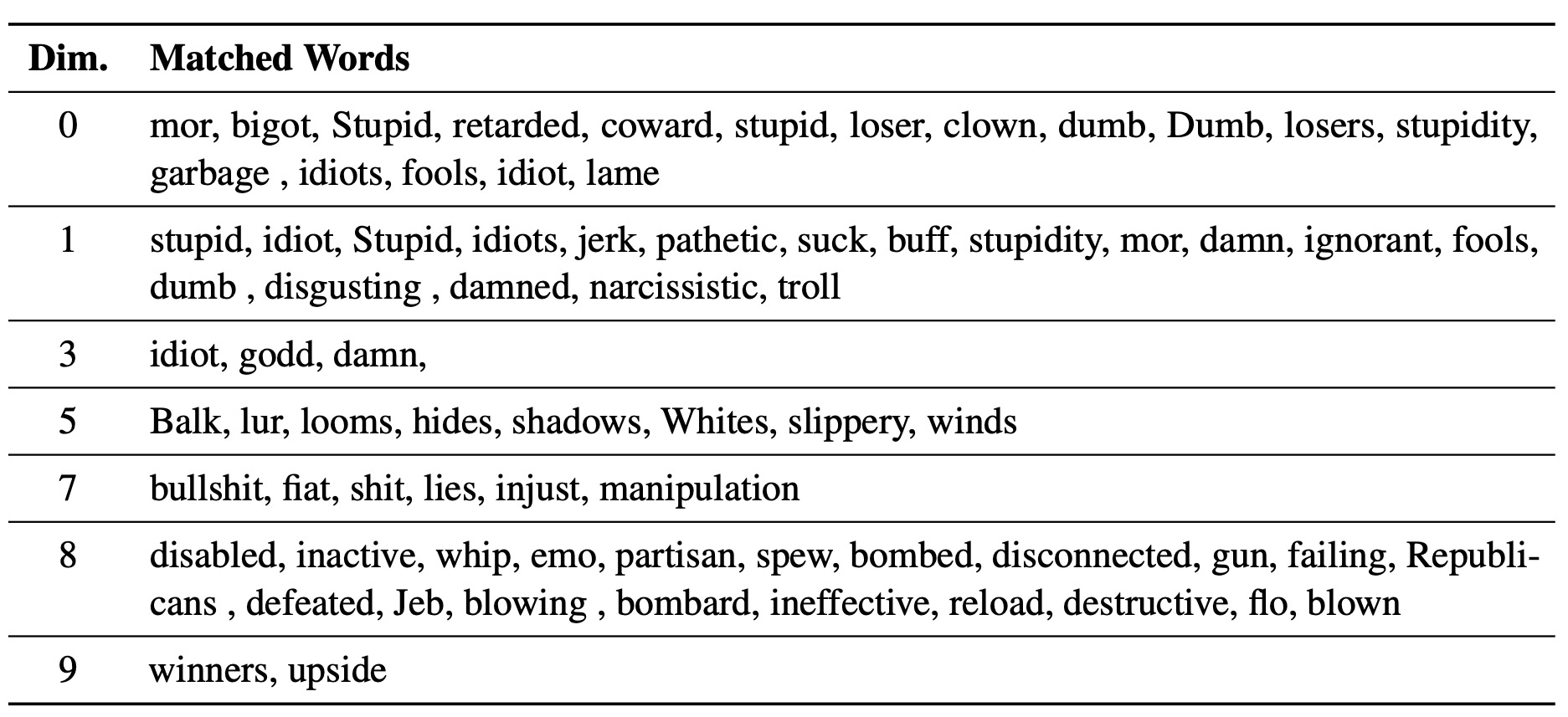
スクリプトexperiments/pca_analysis.pyを使用して、解毒のタスクに最も関連する単語埋め込み寸法を解釈します。スクリプトを実行するには、Perspective APIのトレーニングされたLM-SteerチェックポイントとGOOGLE_API_KEY環境変数へのパスを指定する必要があります。
トレーニングされたLMステアチェックポイントへのパスとして$PATH_TO_CHECKPOINTを指定してください。
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
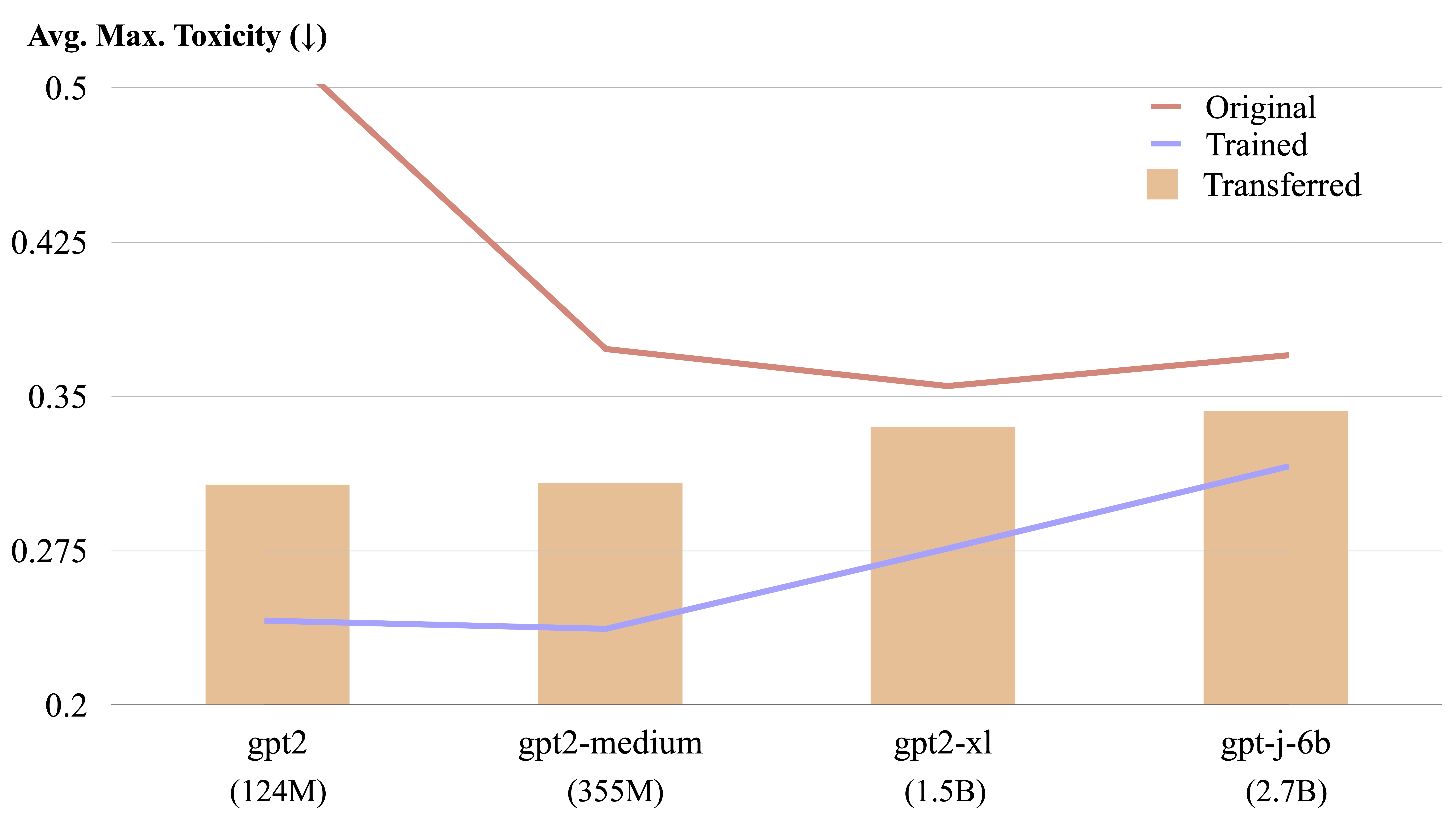
訓練されたLMステアをあるモデルから別のモデルに転送できます。トレーニングされたLMステアチェックポイントへのパスとして$CHECKPOINT1 、ターゲットモデルチェックポイントへのパスとして$CHECKPOINT2指定してください。 LMステアをGPT2-LargeからGPT2-Mediumに転送する例を次に示します。
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
テキストスタイルをより細かく制御するために、複数のLMステアを作成するか、LMを継続的に操縦することができます。継続的なステアリングの場合、 --steer_values 3 1 、 --steer_values 0 1 、または--steer_values -1 1など、さまざまなステアリング効果について、トレーニングスクリプトのsteer_valuesパラメーターを単純にajustできます。
複数のLMステアを作成するには、LM-Steersのマトリックスを追加して、最終的なLMステアとして合計を使用できます。または、LM-Steersを連結して、連結したテンソルを使用することができます(これは、 self.projector1およびself.projector2のマトリックスの長いリストでありlm_steer/models/steer.pyファイル)。
このリポジトリが役立つ場合は、私たちの論文を引用することを検討してください。
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


