LM Steer
1.0.0
Repositorio de código oficial para el documento " LM-Steer: Word Increddings son novillos para modelos de idiomas " ( ACL 2024 Premio de papel sobresaliente ) por Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek Abdelzaher, Heng JI.
Demostración en vivo | Papel | Diapositivas | Póster
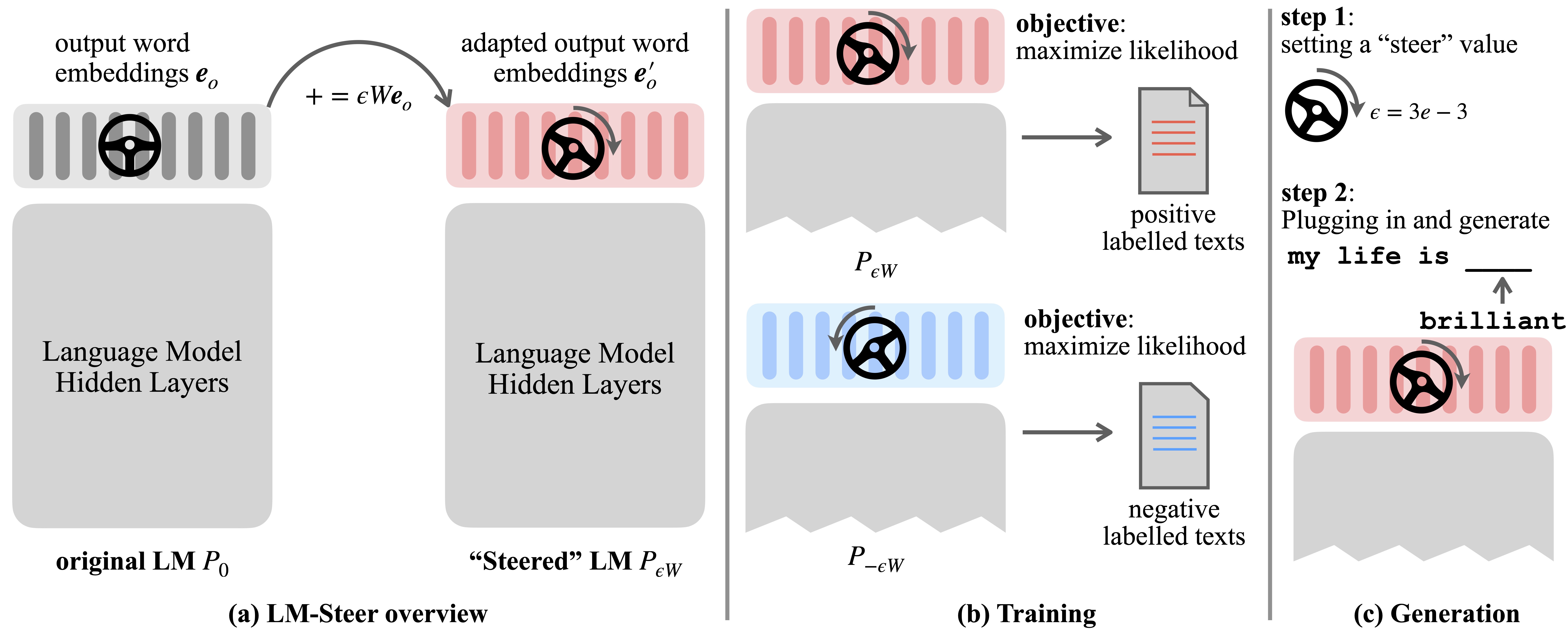
Los modelos de idiomas (LMS) aprenden automáticamente los incrustaciones de palabras durante la pre-entrenamiento en los corpus de idiomas. Aunque los incrustaciones de palabras generalmente se interpretan como vectores de características para palabras individuales, sus roles en la generación de modelos de lenguaje siguen siendo subexplorados. En este trabajo, revisamos teórica y empíricamente los incrustaciones de palabras de salida y descubrimos que sus transformaciones lineales son equivalentes a los estilos de generación de modelos de lenguaje de dirección. Nombramos tales novillos LM-Steers y los encontramos existentes en LM de todos los tamaños. Requiere parámetros de aprendizaje igual al 0.2% del tamaño original de LMS para dirigir cada estilo.
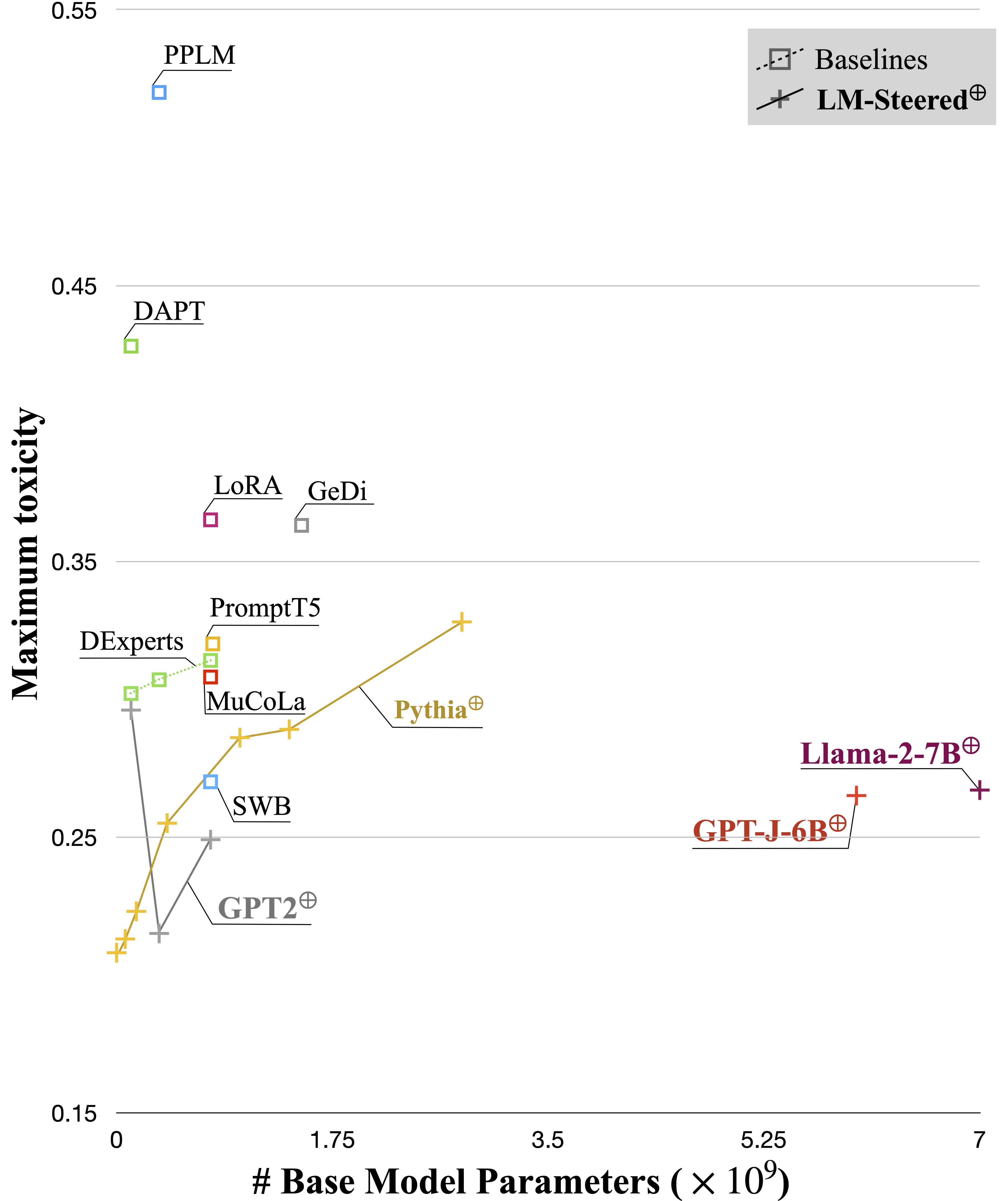
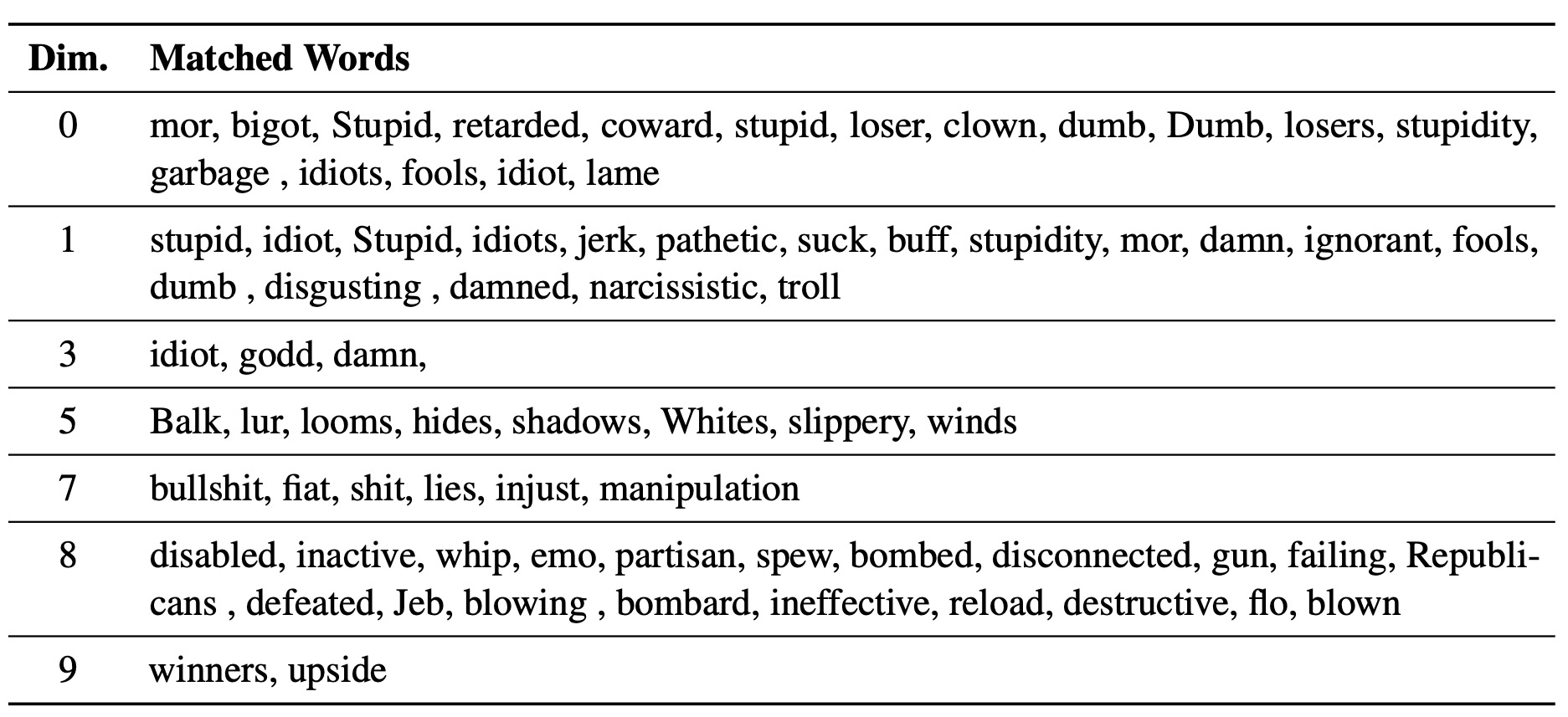

El LM-Steer erudito sirve como una lente en los estilos de texto: revela que los incrustaciones de palabras son interpretables cuando están asociadas con generaciones de modelos de lenguaje, y puede resaltar los tramos de texto que más indican las diferencias de estilo.
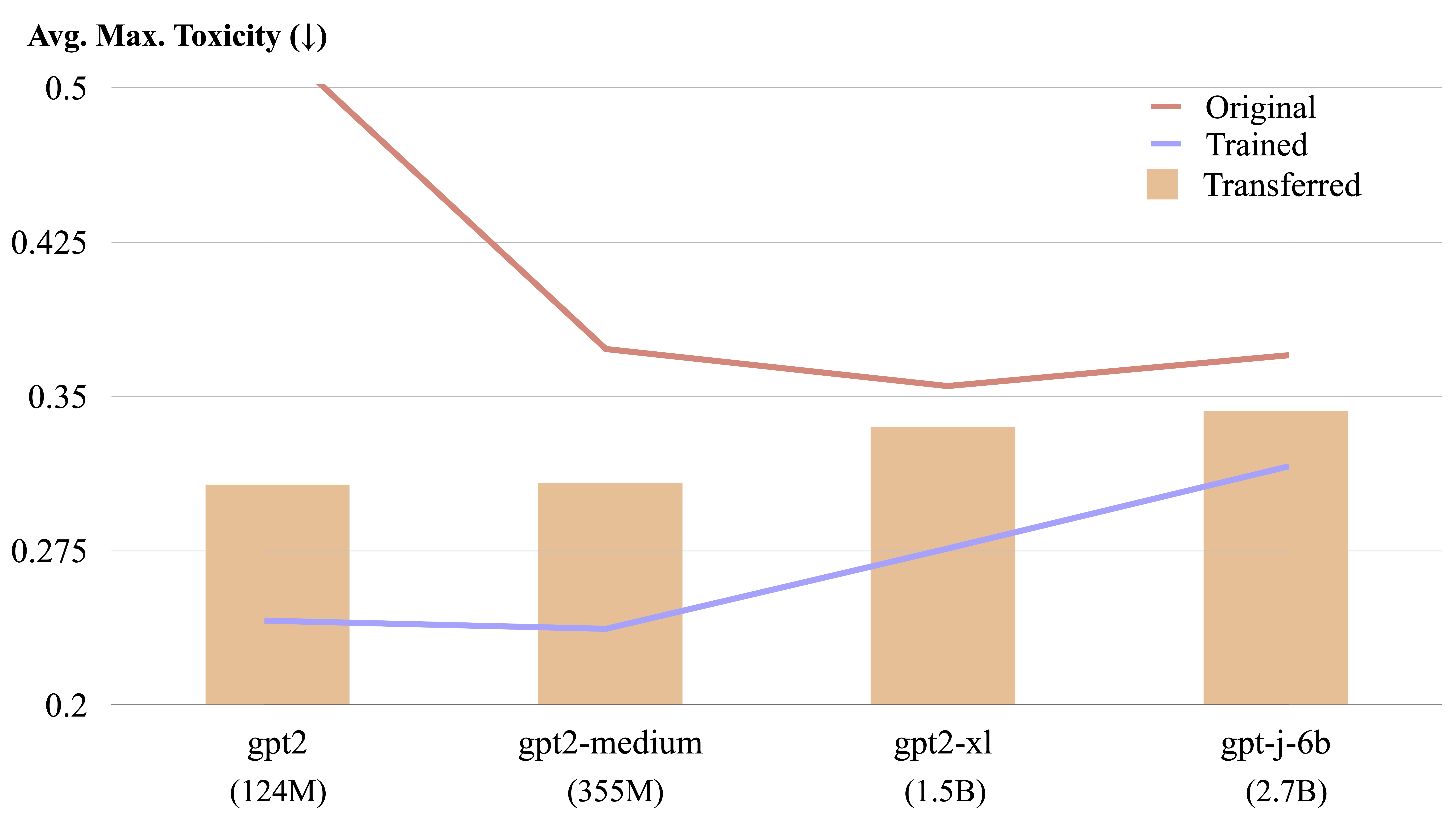
Una estraza LM es transferible entre diferentes modelos de lenguaje mediante un cálculo de forma explícita.
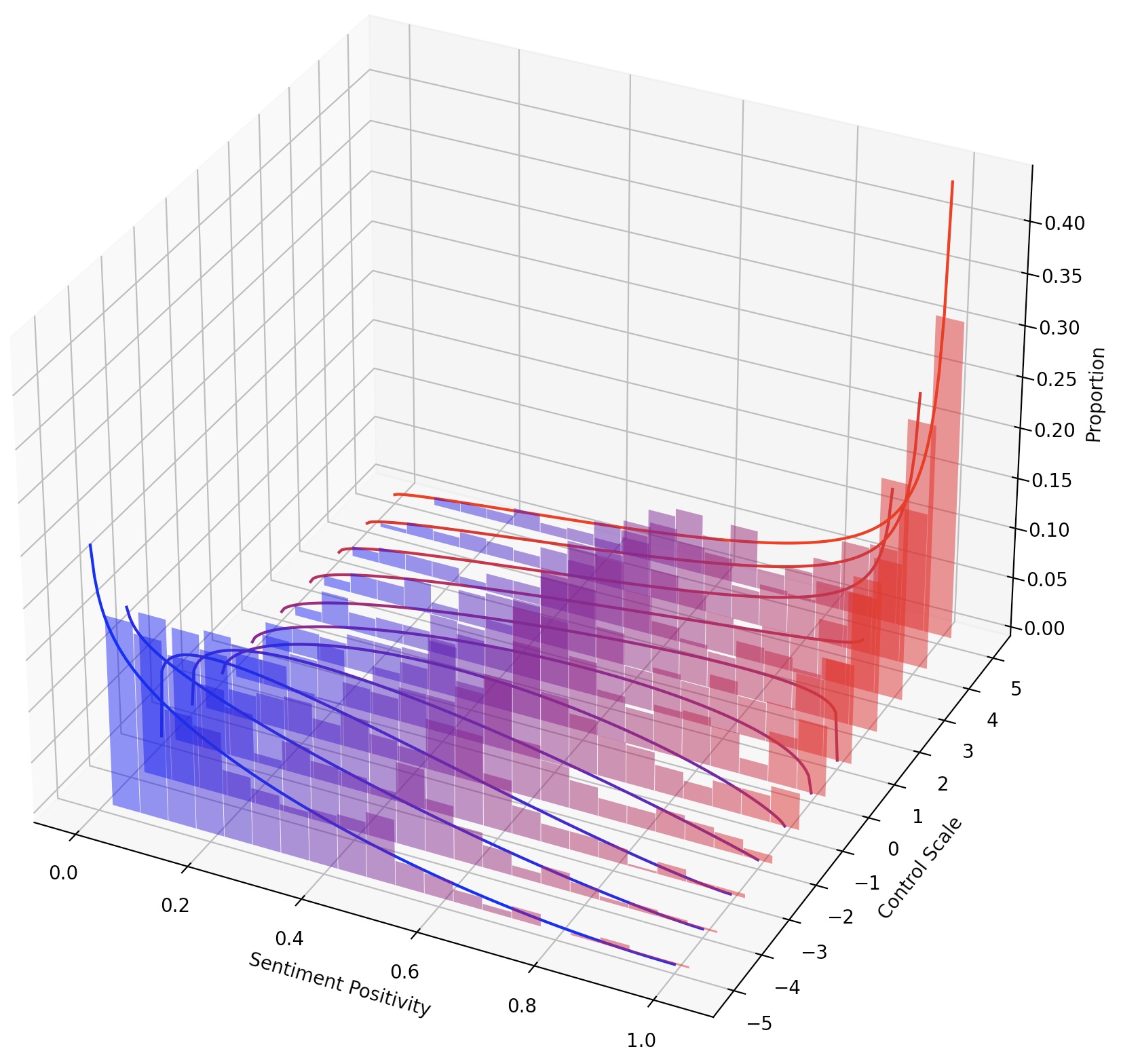
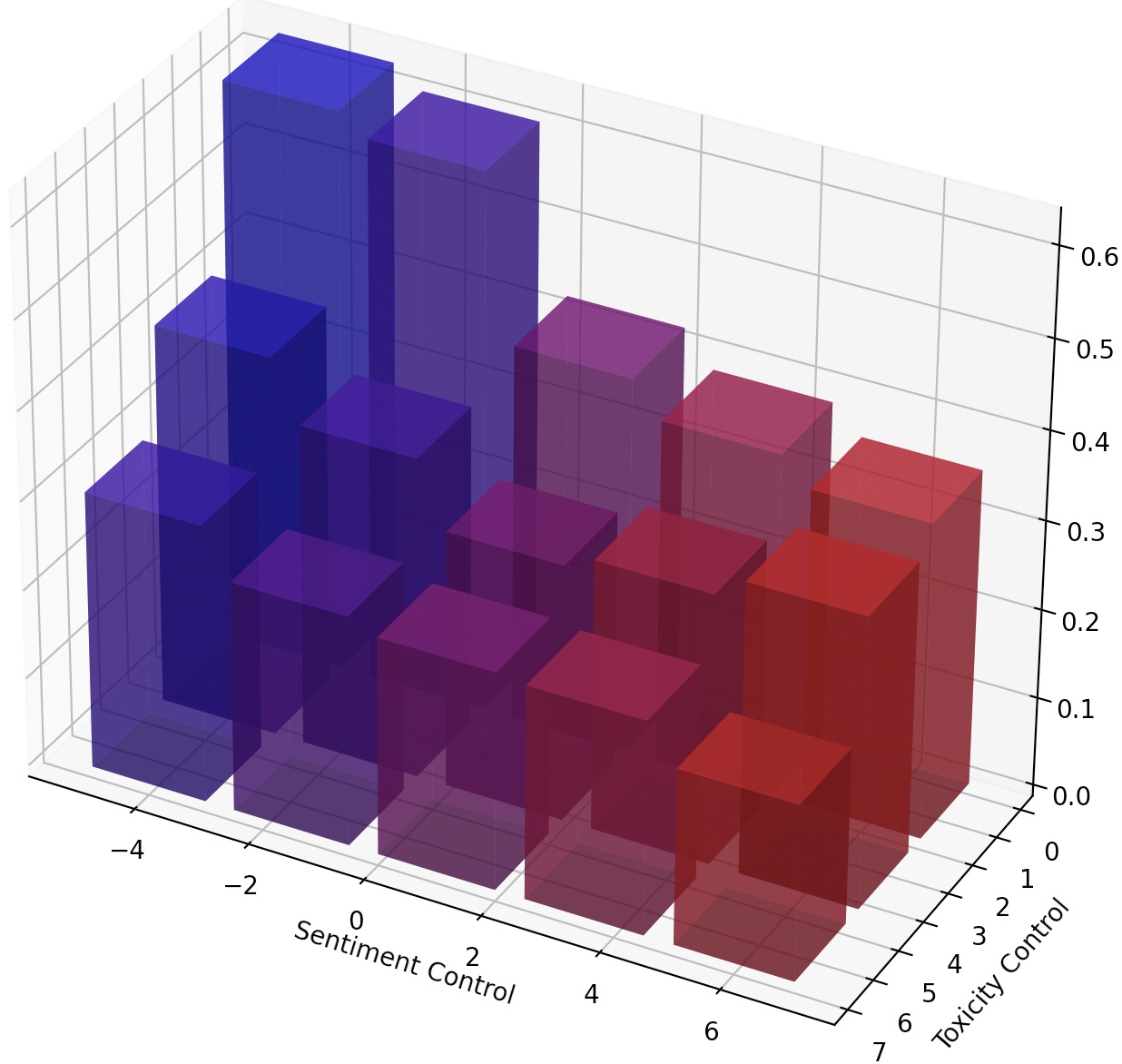
También se puede dirigir continuamente LM simplemente escalando el LM-Steer o componer múltiples parentes de LM agregando sus transformaciones.
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
Después de la configuración en Mucola, descargamos los datos de capacitación del desafío de clasificación de comentarios tóxicos de Kaggle. Utilizamos las indicaciones del repositorio de código de Mucola (ubicado en data/prompts ), que contiene indicaciones para el control de sentimientos y la eliminación de toxicidad.
Comandos para adquirir datos de capacitación (debe configurar una cuenta de Kaggle y configurar la clave de la API Kaggle):
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
Usando GPT2-Large como modelo base, entrenamos a un LM-Steer para la desintoxicación.
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
El archivo de predicción se guardará en logs/$TRIAL/predictions.jsonl . Podemos evaluar las predicciones utilizando el siguiente comando. Para evaluar con la API de perspectiva de Google Cloud, debe establecer la export GOOGLE_API_KEY=xxxxxxx de entorno. De lo contrario, puede eliminar la métrica de "toxicidad" del script de evaluación.
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
El script de evaluación producirá los resultados de la evaluación a logs/$TRIAL/result_stats.txt .
En esta tarea, se requiere que controle el sentimiento del texto generado en dirección positiva o negativa. Al evaluar la capacidad hacia un sentimiento positivo, el modelo se solicita en indicaciones neutrales y negativas. Al evaluar la capacidad hacia un sentimiento negativo, el modelo se solicita tanto en indicaciones neutrales como positivas. Entonces hay cuatro configuraciones de evaluación en total. Aquí muestra un ejemplo de capacitación de una estufa de LM para el control de sentimientos negativos y evaluado en indicaciones positivas.
Nuestro código anota y reutiliza modelos capacitados, por lo que puede capacitar a un modelo una vez y evaluarlo varias veces en diferentes entornos sin volver a entrenar.
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
Utilizamos el script experiments/pca_analysis.py para interpretar dimensiones de incrustaciones de palabras que son más relevantes para la tarea de desintoxicación. Para ejecutar el script, debe especificar la ruta al punto de control LM-Steer capacitado y la variable de entorno GOOGLE_API_KEY para la API de perspectiva.
Especifique $PATH_TO_CHECKPOINT como la ruta al punto de control LM-Steer capacitado.
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
Podemos transferir un estador LM capacitado de un modelo a otro. Especifique $CHECKPOINT1 como la ruta al punto de control LM-Steer capacitado y $CHECKPOINT2 como la ruta al modelo de control del modelo de destino. Aquí hay un ejemplo de transferencia de una estufa LM de GPT2-Large a GPT2-Medio.
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
Para lograr un control de grano más fino sobre el estilo de texto, podemos componer múltiples parientes LM o dirigir continuamente el LM. Para la dirección continua, simplemente podemos ajustar el parámetro steer_values en el script de entrenamiento, como --steer_values 3 1 , --steer_values 0 1 o --steer_values -1 1 para diferentes efectos de dirección.
Para componer múltiples parentesca LM, simplemente puede agregar las matrices de los Steers LM y usar la suma como el Estado LM final. Alternativamente, puede concatenar a los parentesca LM y usar el tensor concatenado (que es una lista más larga de matrices en el self.projector1 y los atributos de self.projector2 en el archivo lm_steer/models/steer.py ).
Si encuentra útil este repositorio, considere citar nuestro documento:
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


