LM Steer
1.0.0
Repositório oficial de código para o artigo " LM-Steer: Word Incoreddings são novidades para modelos de idiomas " ( ACL 2024 em destaque em papel ) de Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek Abdelzaher, Heng Ji.
Demoção ao vivo | Papel | Slides | Poster
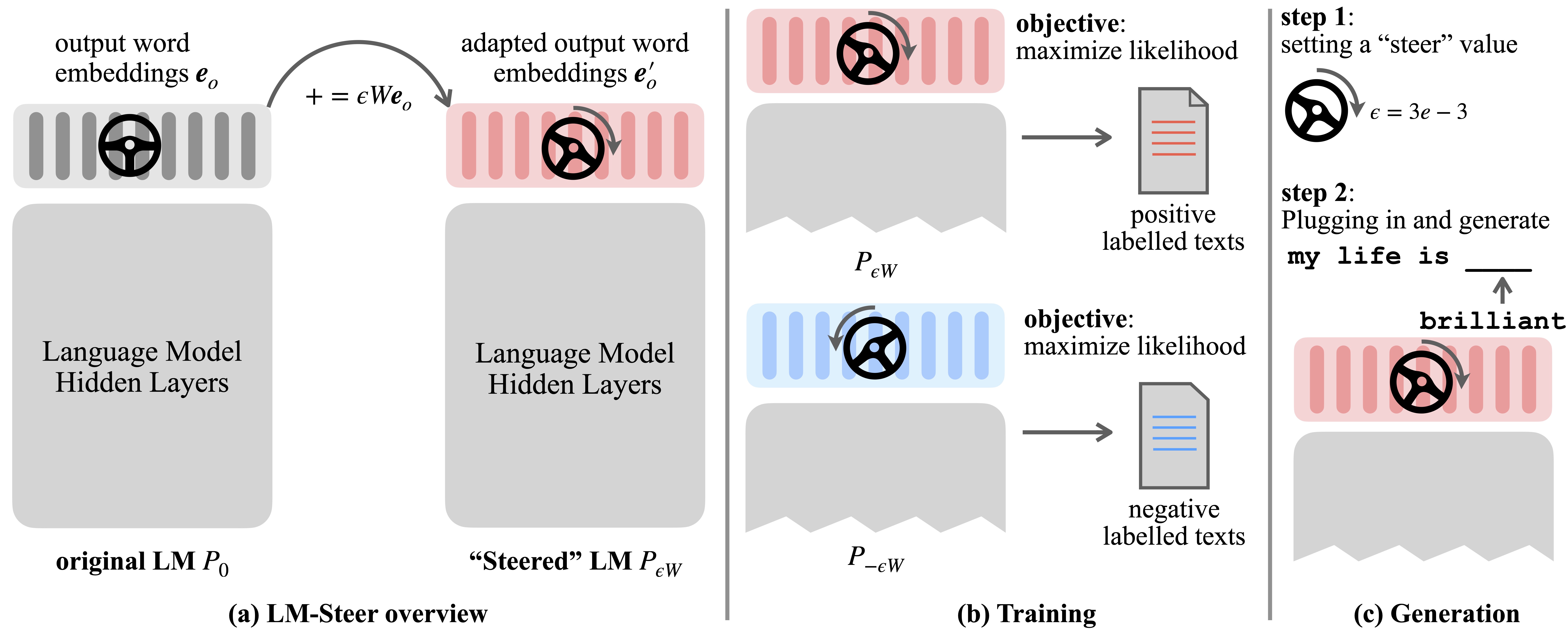
Modelos de idiomas (LMS) aprendem automaticamente incorporações de palavras durante o pré-treinamento em corpora de idiomas. Embora as incorporações de palavras sejam geralmente interpretadas como vetores de recursos para palavras individuais, seus papéis na geração de modelos de idiomas permanecem subexplorados. Neste trabalho, nós, teoricamente e empiricamente, revisamos incorporações de palavras de saída e descobrimos que suas transformações lineares são equivalentes aos estilos de geração de modelos de linguagem de direção. Digitamos esses Steers LM-Steers e os encontramos existentes em LMS de todos os tamanhos. Requer parâmetros de aprendizado iguais a 0,2% do tamanho do LMS original para direcionar cada estilo.
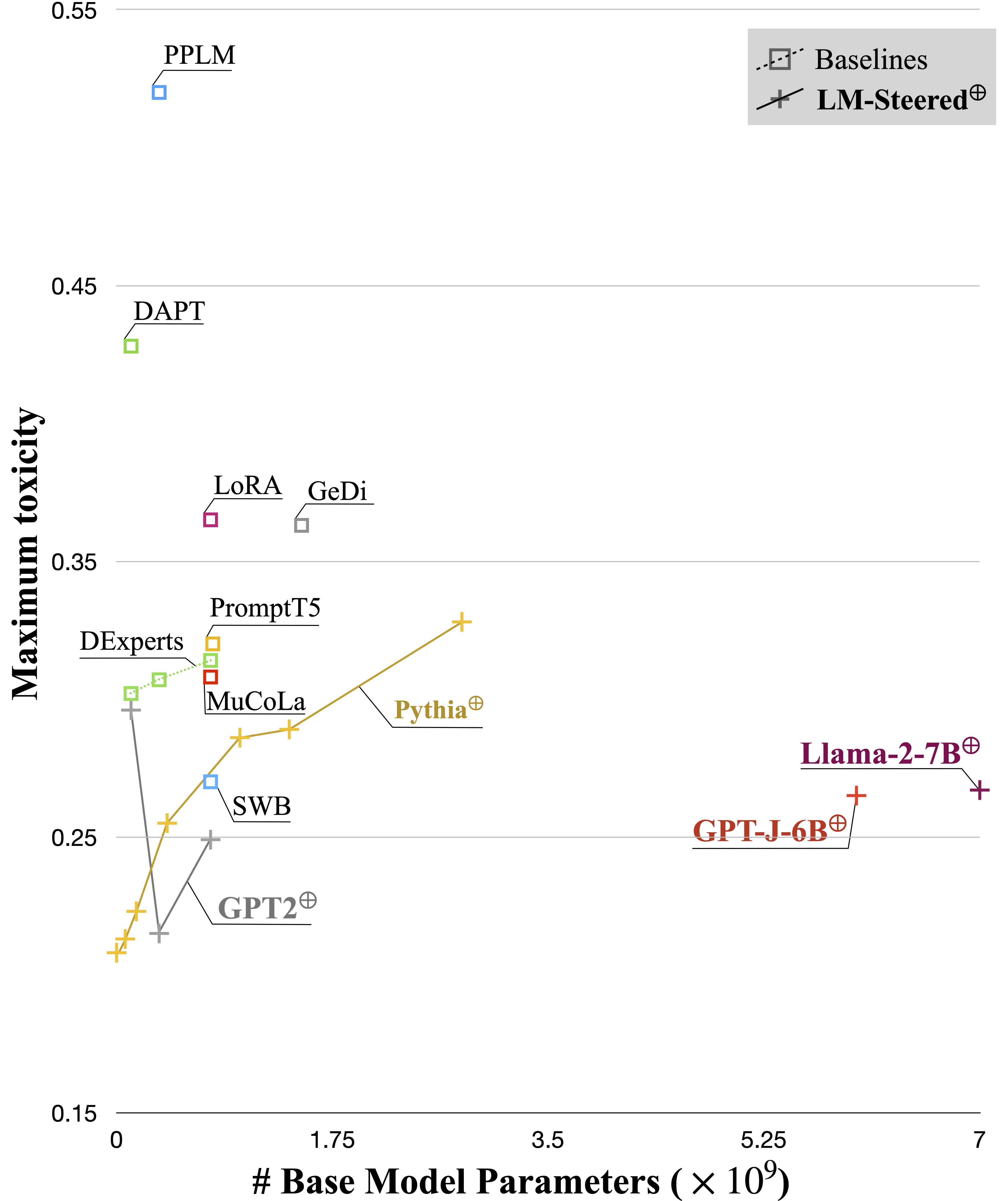
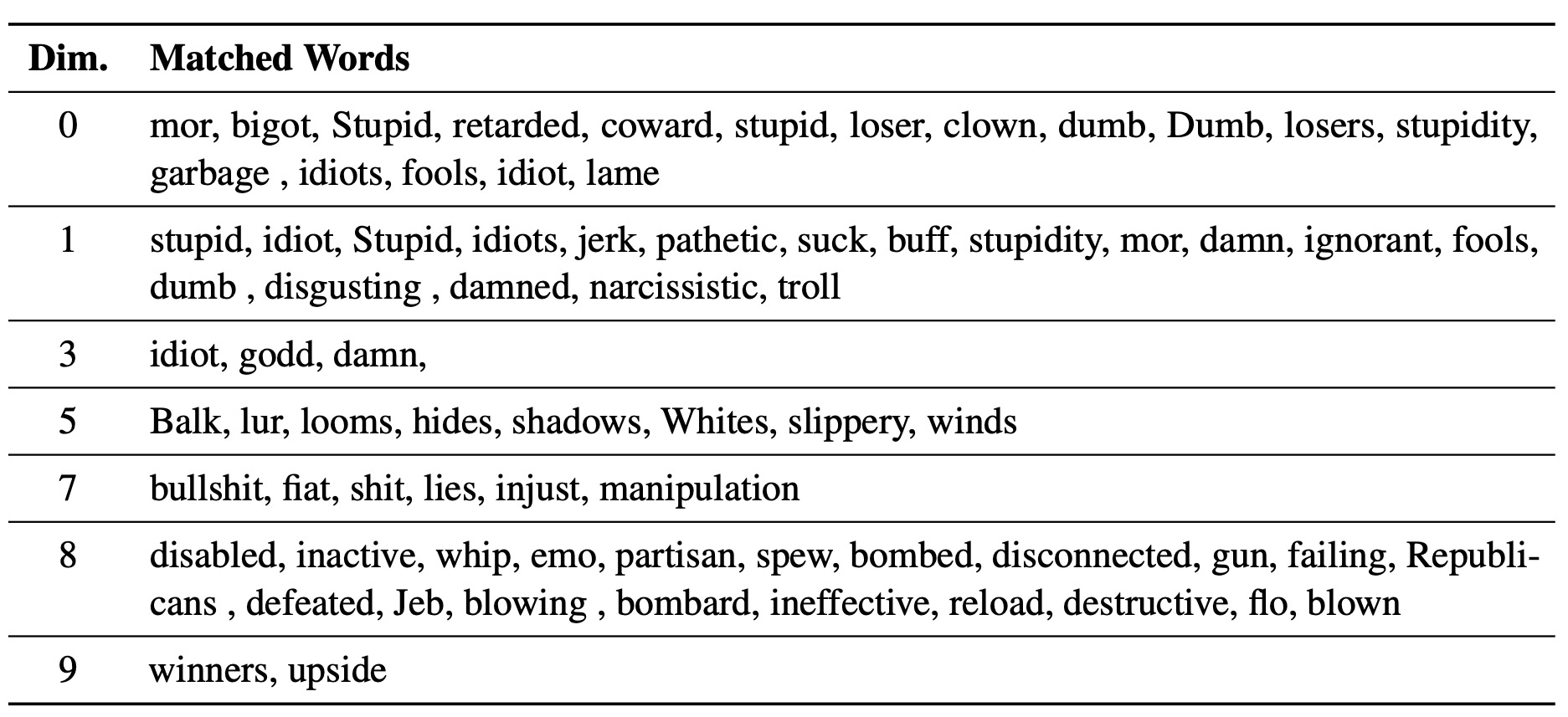

A Steer LM aprendida serve como lente nos estilos de texto: revela que as incorporações de palavras são interpretáveis quando associadas às gerações de modelos de idiomas e podem destacar vãos de texto que indicam as diferenças de estilo.
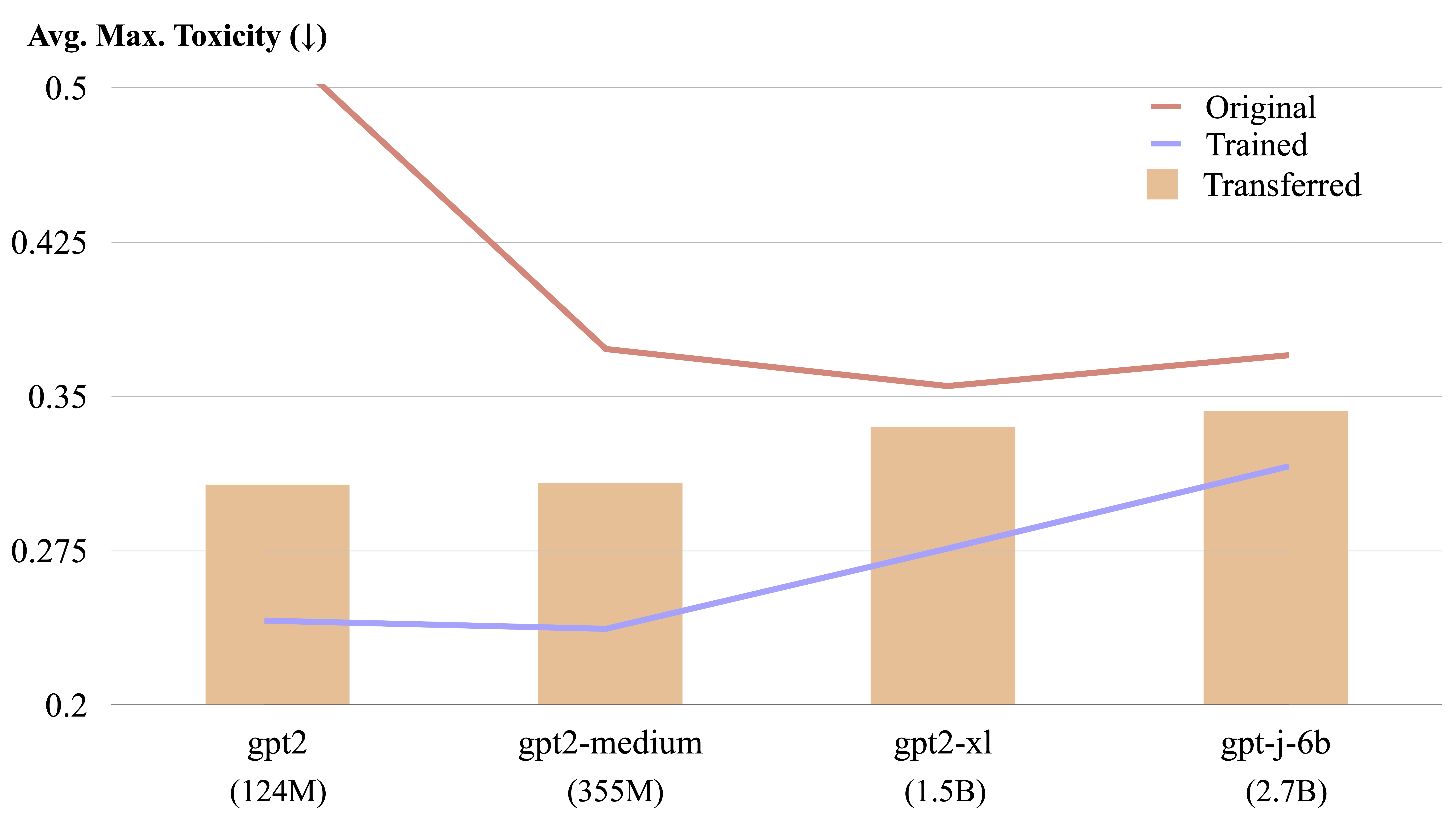
Um Steer LM é transferível entre diferentes modelos de linguagem por um cálculo de forma explícita.
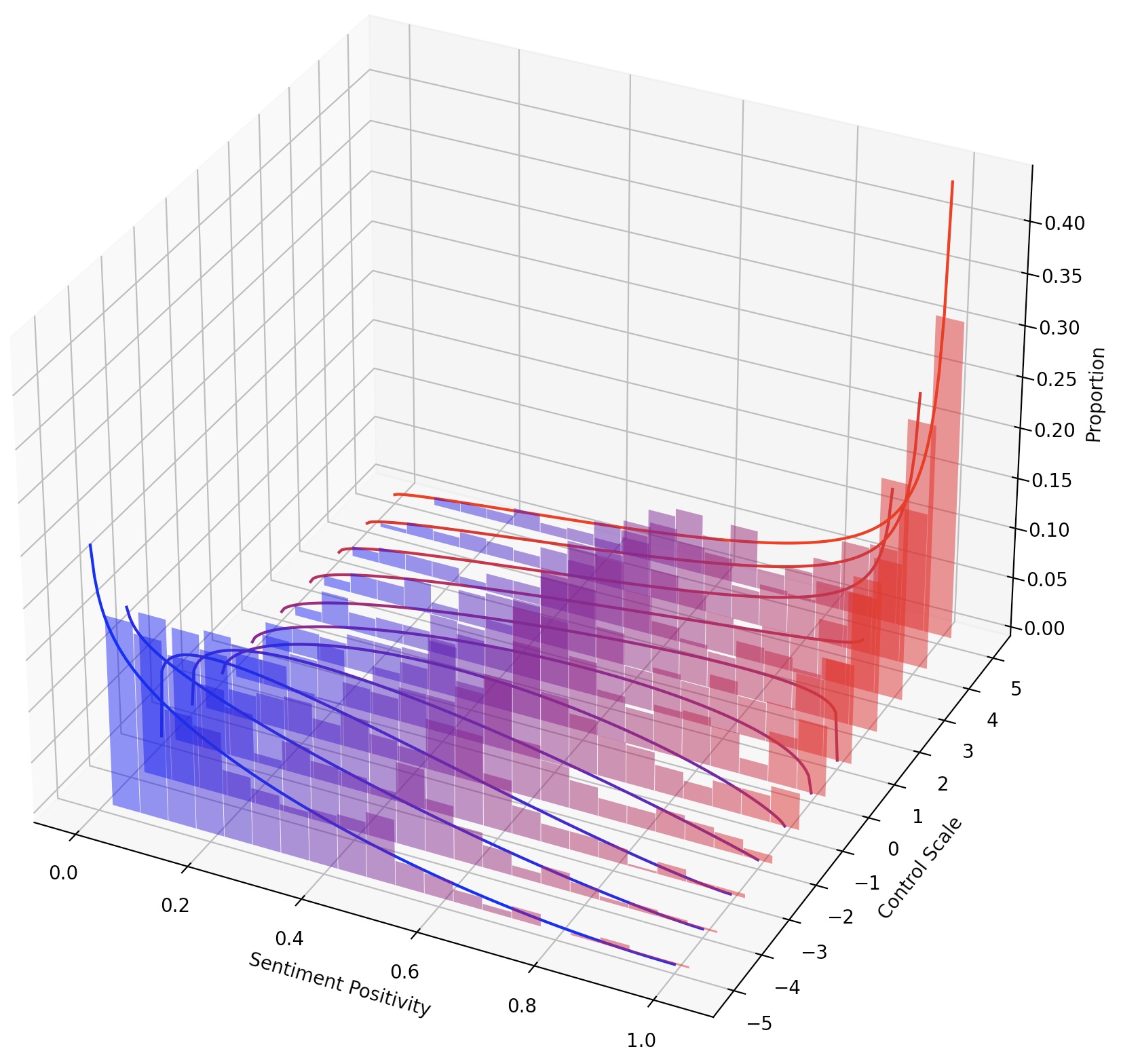
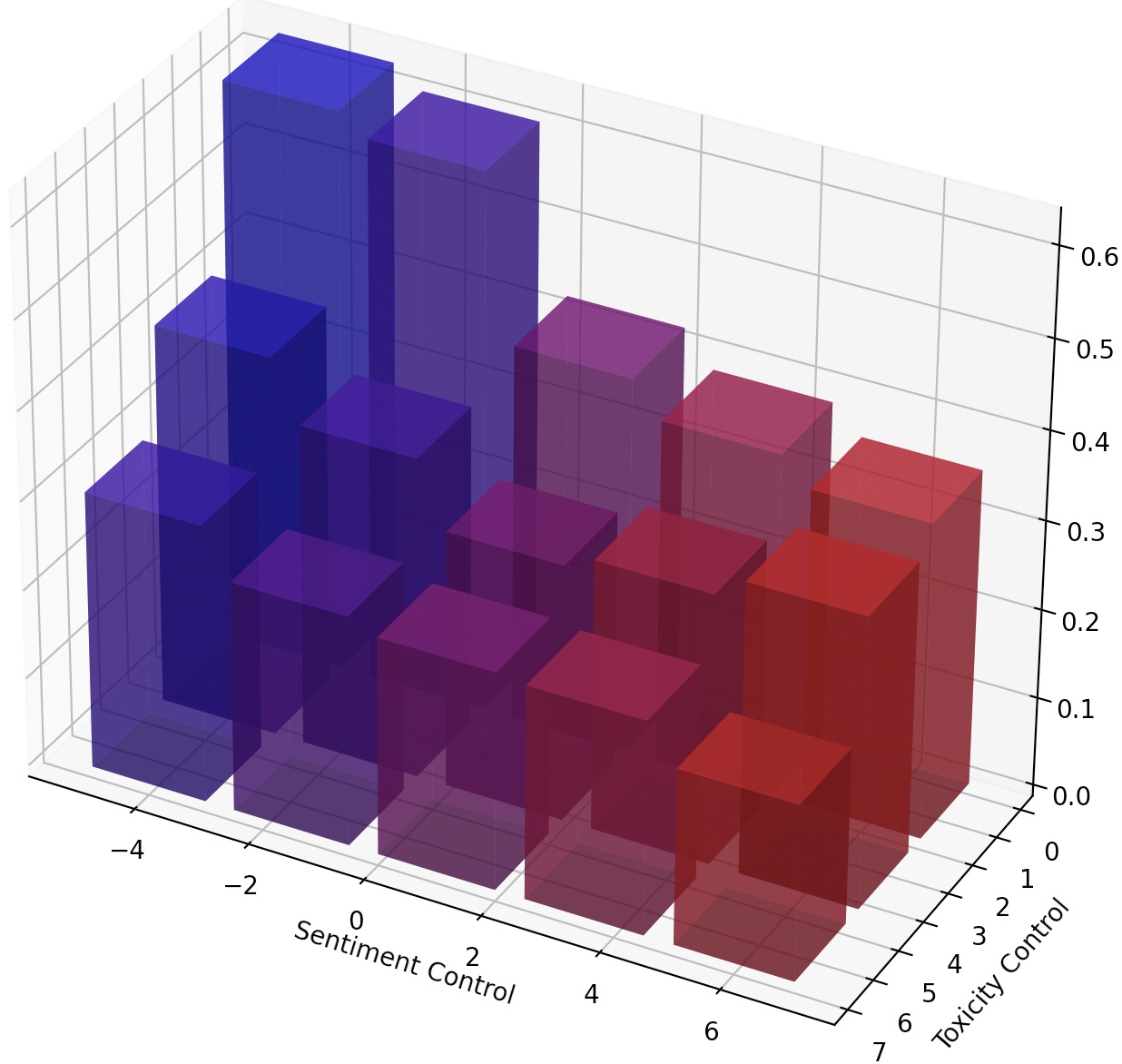
Também é possível direcionar continuamente o LMS simplesmente escalando o lm-steer ou compondo vários Steres LM, adicionando suas transformações.
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
Após a configuração em Mucola, baixamos os dados de treinamento do Kaggle Toxic Comment Classification Challenge. Utilizamos prompts do repositório de código da Mucola (colocado em data/prompts ), que contém prompts para controle de sentimentos e remoção de toxicidade.
Comandos para adquirir dados de treinamento (você precisa configurar uma conta Kaggle e configurar a chave da API Kaggle):
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
Usando o GPT2-Large como modelo básico, treinamos um lm-steer para desintoxicação.
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
O arquivo de previsão será salvo em logs/$TRIAL/predictions.jsonl . Podemos avaliar as previsões usando o seguinte comando. Para avaliar com a API Perspective do Google Cloud, você precisa definir a variável de ambiente export GOOGLE_API_KEY=xxxxxxx . Caso contrário, você pode remover a métrica de "toxicidade" do script de avaliação.
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
O script de avaliação produzirá os resultados da avaliação para logs/$TRIAL/result_stats.txt .
Nesta tarefa, é necessário controlar o sentimento do texto gerado na direção positiva ou negativa. Ao avaliar a capacidade de um sentimento positivo, o modelo é solicitado em avisos neutros e negativos. Ao avaliar a capacidade de um sentimento negativo, o modelo é solicitado em avisos neutros e positivos. Portanto, existem quatro configurações de avaliação no total. Aqui mostra um exemplo de treinamento de um lm para controle negativo de sentimentos e avaliado em avisos positivos.
Nossas pontuações de código e reutilizam modelos treinados, para que você possa treinar um modelo uma vez e avaliá-lo várias vezes em diferentes configurações sem re-treinamento.
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
Utilizamos as experiments/pca_analysis.py para interpretar dimensões de incorporação de palavras que são mais relevantes para a tarefa de desintoxicação. Para executar o script, você precisa especificar o caminho para o ponto de verificação treinado LM-Steer e a variável de ambiente GOOGLE_API_KEY para a API de perspectiva.
Especifique $PATH_TO_CHECKPOINT como o caminho para o ponto de verificação treinado LM-steer.
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
Podemos transferir um LM-Steer treinado de um modelo para outro. Especifique $CHECKPOINT1 como o caminho para o ponto de verificação treinado LM-steer e $CHECKPOINT2 como o caminho para o ponto de verificação do modelo de destino. Aqui está um exemplo de transferência de um lm de ritmo de GPT2-Large para GPT2-Medium.
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
Para alcançar um controle mais fino sobre o estilo de texto, podemos compor múltiplos-steres de LM ou direcionar continuamente o LM. Para a direção contínua, podemos simplesmente dar ao justiça do parâmetro steer_values no script de treinamento, como --steer_values 3 1 , --steer_values 0 1 ou --steer_values -1 1 para diferentes efeitos de direção.
Para compor vários metros de LM, você pode simplesmente adicionar as matrizes dos Steres LM e usar a soma como a parte final do LM. Como alternativa, você pode concatenar os Steters LM e usar o tensor concatenado (que é uma lista mais longa de matrizes no self.projector1 e self.projector2 atributos no arquivo lm_steer/models/steer.py ).
Se você achar útil este repositório, considere citar nosso artigo:
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


