LM Steer
1.0.0
논문의 공식 코드 저장소 " LM Steer : Word Embeddings는 언어 모델의 조향입니다 "( ACL 2024 뛰어난 종이 상 )는 Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek Abdelzaher, Heng Ji.
라이브 데모 | 종이 | 슬라이드 | 포스터
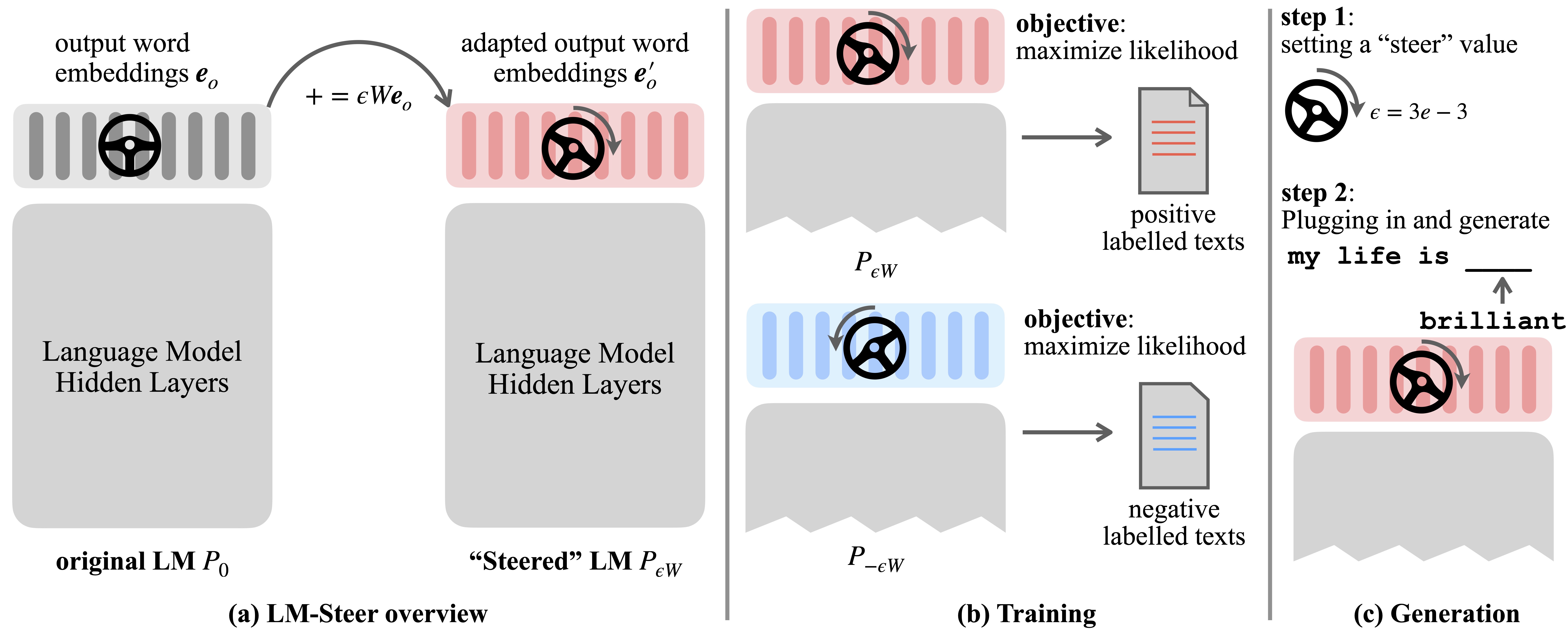
언어 모델 (LMS)은 언어 Corpora에서 사전 훈련 중에 단어 임베딩을 자동으로 학습합니다. 단어 임베딩은 일반적으로 개별 단어의 특징 벡터로 해석되지만 언어 모델 생성에서의 역할은 미숙 한 상태로 남아 있습니다. 이 작업에서, 우리는 이론적으로 그리고 경험적으로 출력 단어 임베드를 다시 방문하고 그들의 선형 변환이 스티어링 언어 모델 생성 스타일과 동일하다는 것을 발견했다. 우리는 그러한 Steers LM-Steers의 이름을 지정하고 모든 크기의 LM으로 존재합니다. 각 스타일의 조향을 위해 원래 LMS 크기의 0.2%에 해당하는 학습 매개 변수가 필요합니다.
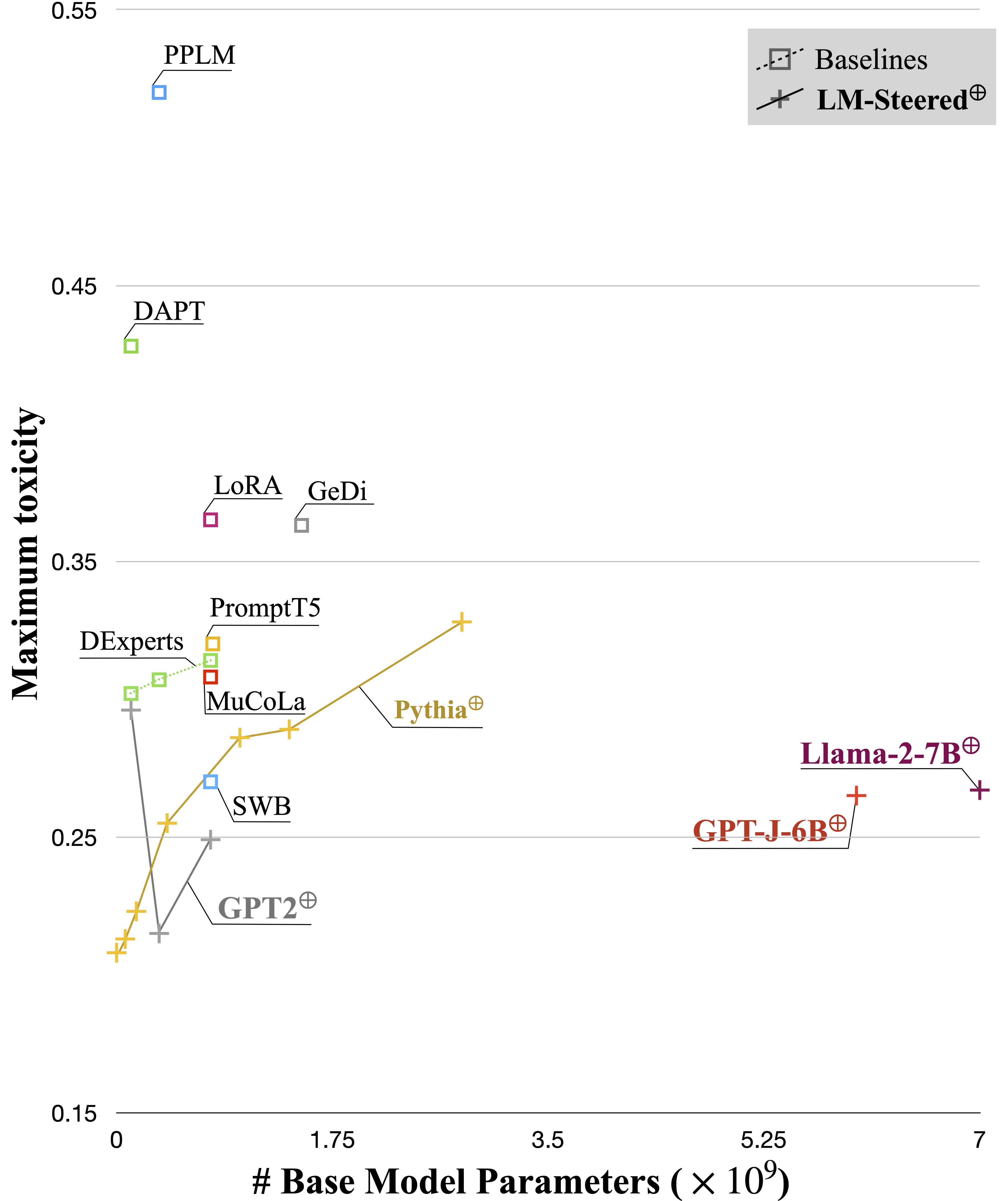
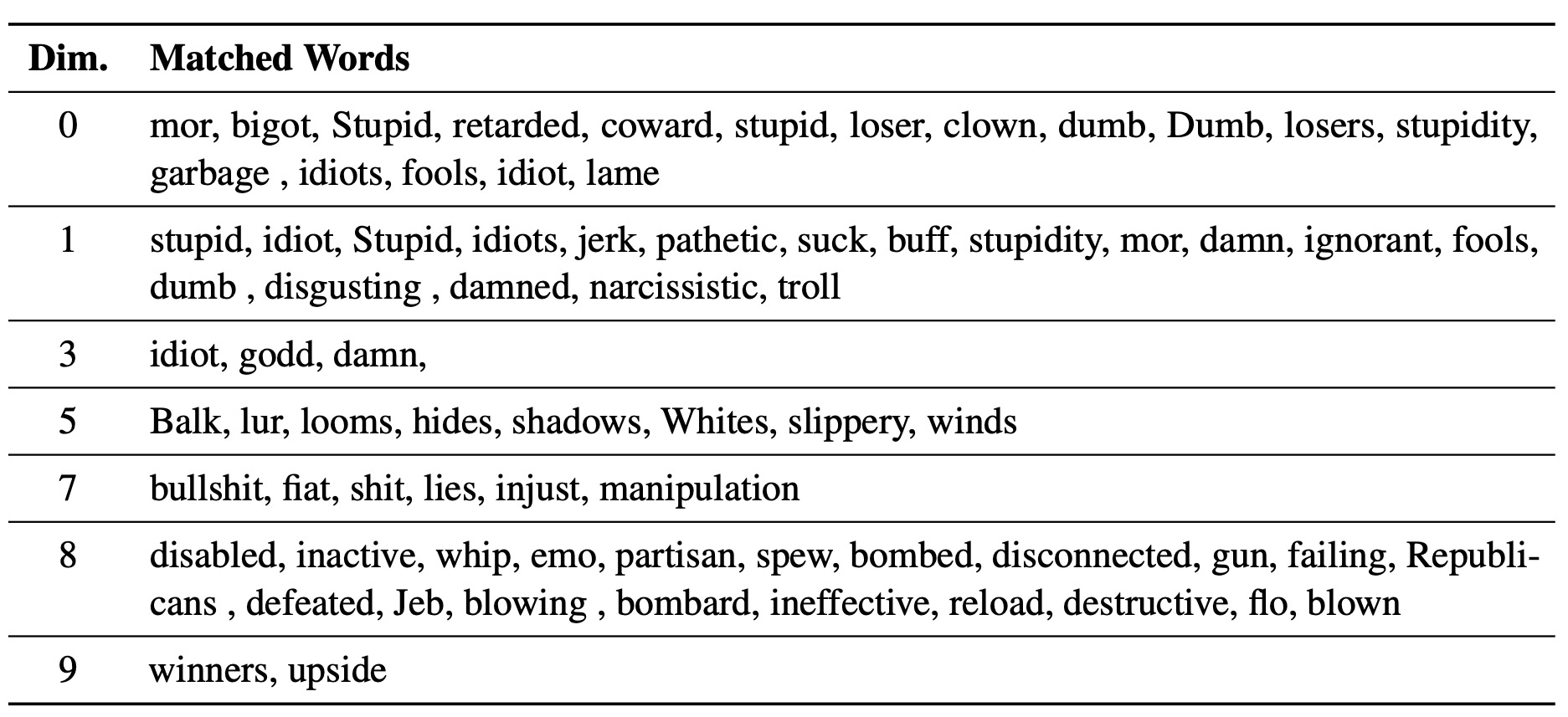

배운 LM 스테이터는 텍스트 스타일의 렌즈 역할을합니다. 언어 모델 세대와 관련 될 때 단어 임베드가 해석 될 수 있으며 스타일 차이를 가장 많이 나타내는 텍스트 스팬을 강조 할 수 있음을 보여줍니다.
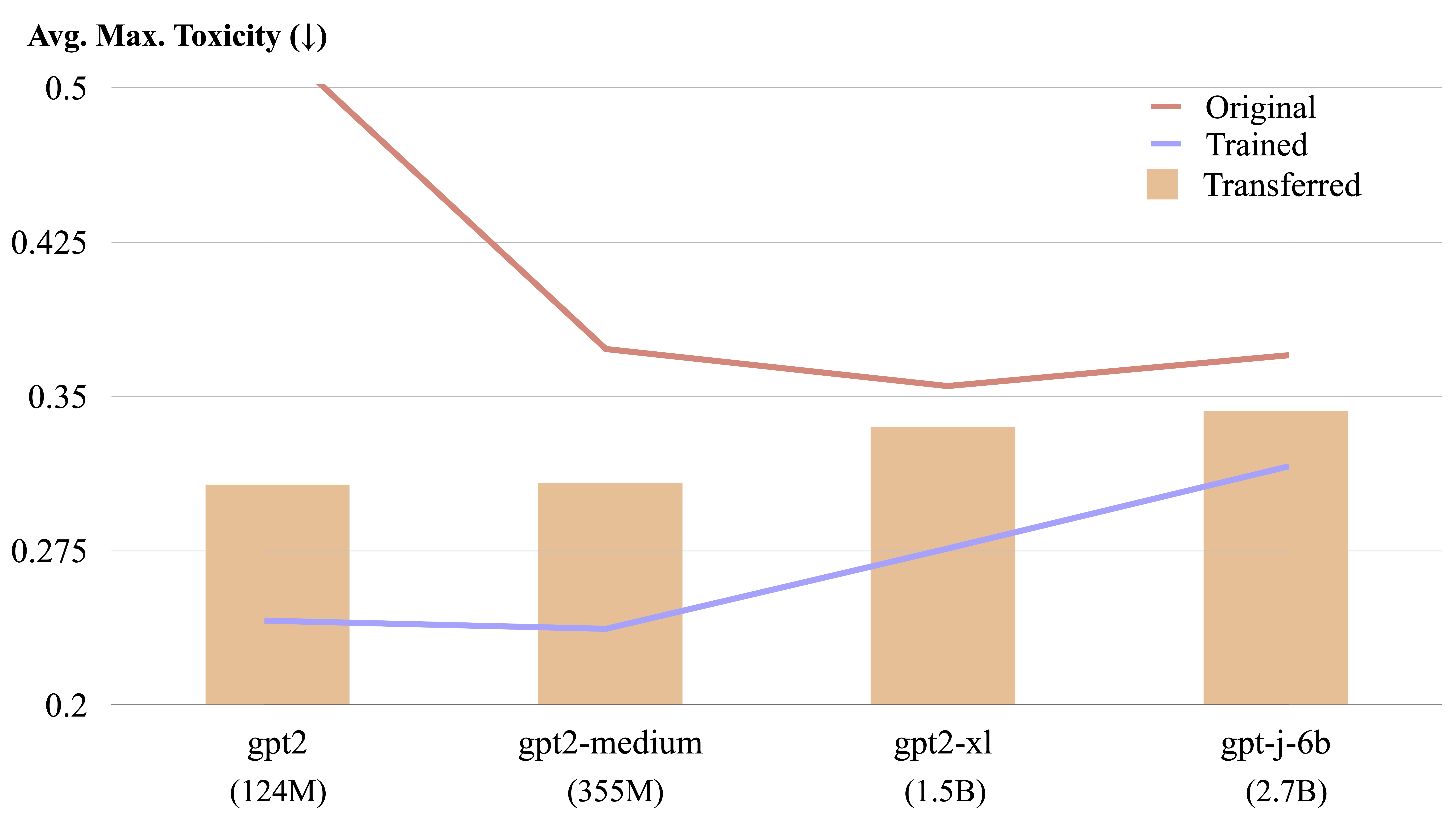
LM 단계는 명시 적 형태 계산에 의해 다른 언어 모델간에 양도 할 수 있습니다.
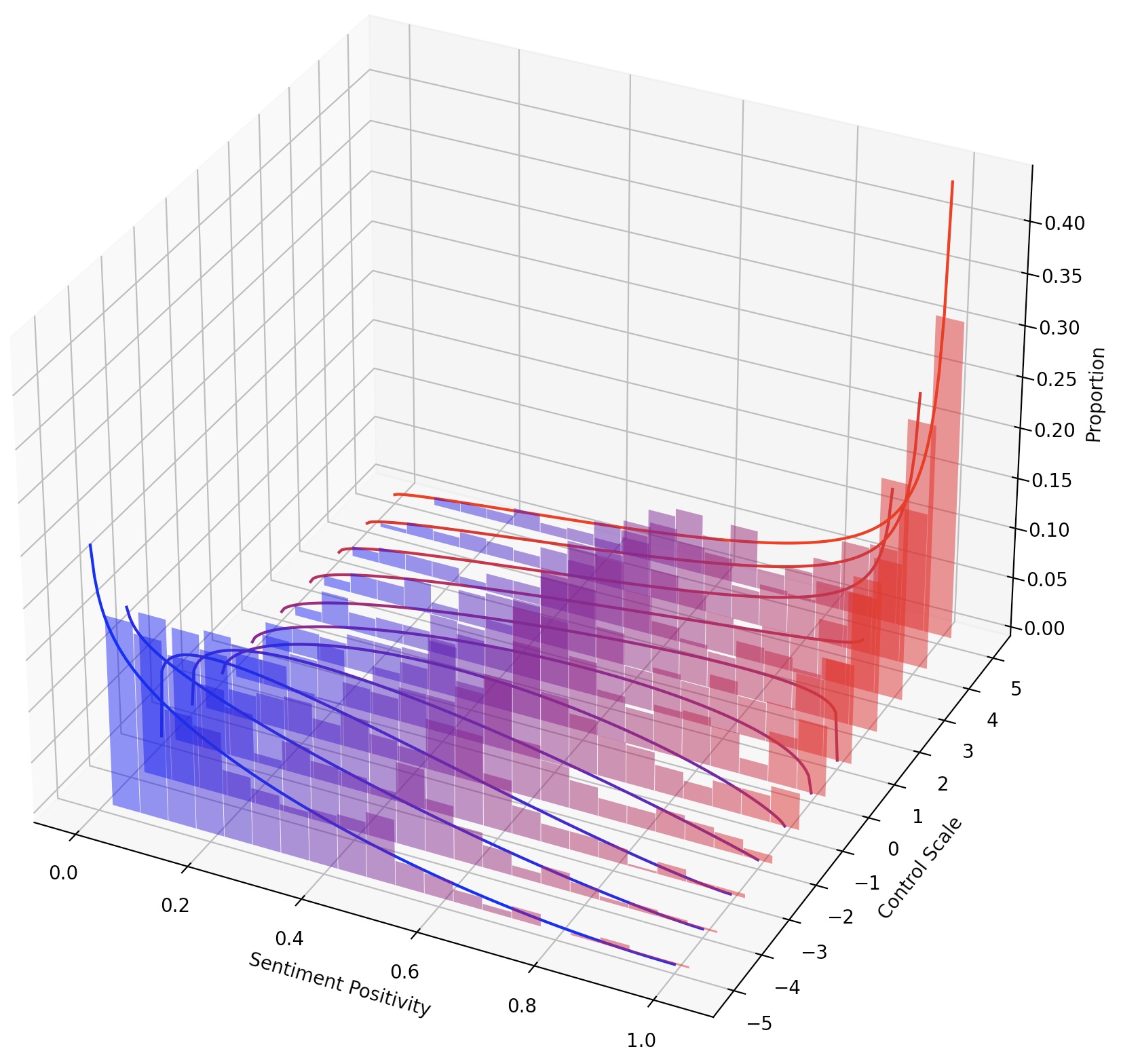
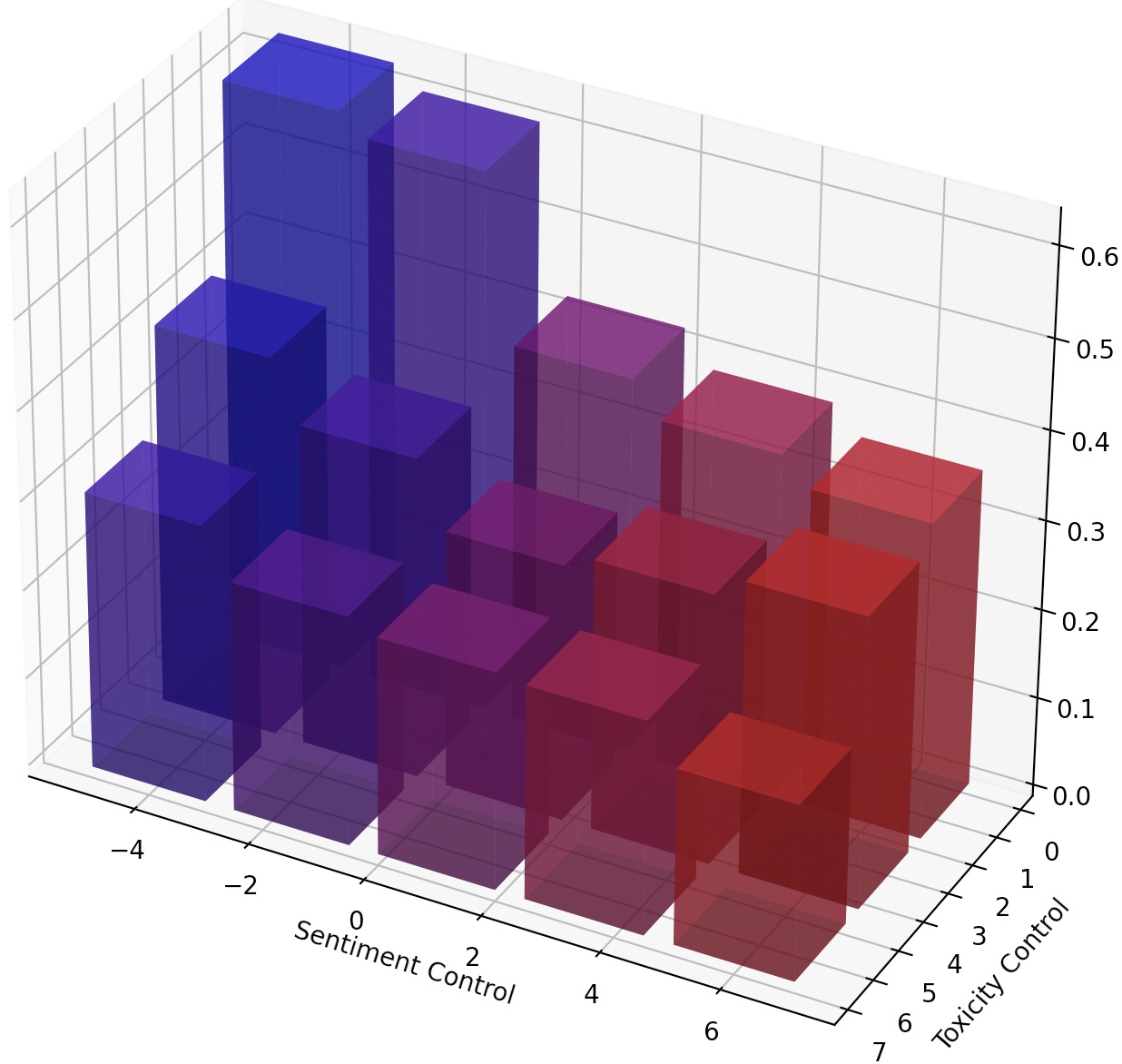
또한 LM 스테이터를 스케일링하여 LM을 지속적으로 조정하거나 변환을 추가하여 여러 LM 스테이저를 구성 할 수 있습니다.
kaggle
torch
transformers
datasets
numpy
pandas
googleapiclient
Mucola의 설정에 따라 Kaggle 독성 주석 분류 문제에서 교육 데이터를 다운로드합니다. 우리는 Mucola의 코드 저장소 ( data/prompts 에 배치)의 프롬프트를 사용하며, 여기에는 감정 제어 및 독성 제거를위한 프롬프트가 포함되어 있습니다.
교육 데이터 획득 명령 (Kaggle 계정을 설정하고 Kaggle API 키를 구성해야 함) :
# training data
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
rm jigsaw-unintended-bias-in-toxicity-classification.zip
# processing
bash data/toxicity/toxicity_preprocess.sh
data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
GPT2-LARGE를 기본 모델로 사용하여 해독을 위해 LM 스테이터를 훈련시킵니다.
TRIAL=detoxification-gpt2-large
mkdir -p logs/$TRIAL
PYTHONPATH=. python experiments/training/train.py
--dataset_name toxicity
--data_dir data/toxicity/jigsaw-unintended-bias-in-toxicity-classification
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/nontoxic_prompts-10k.jsonl
--output_file logs/$TRIAL/predictions.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values 5 1
예측 파일은 logs/$TRIAL/predictions.jsonl 로 저장됩니다. 다음 명령을 사용하여 예측을 평가할 수 있습니다. Google Cloud의 Perspective API를 평가하려면 export GOOGLE_API_KEY=xxxxxxx 환경 변수를 설정해야합니다. 그렇지 않으면 평가 스크립트에서 "독성"메트릭을 제거 할 수 있습니다.
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions.jsonl
--metrics toxicity,ppl-big,dist-n
--output_file result_stats.txt
echo "Detoxification results:"
cat logs/$TRIAL/result_stats.txt
평가 스크립트는 평가 결과를 logs/$TRIAL/result_stats.txt 로 출력합니다.
이 작업에서 생성 된 텍스트의 감정을 긍정적 또는 부정적인 방향으로 제어해야합니다. 긍정적 인 감정을 향한 능력을 평가할 때, 모델은 중립적 및 부정적인 프롬프트 모두에 촉발된다. 부정적인 감정을 향한 능력을 평가할 때, 모델은 중립적 및 양성 프롬프트 모두에 촉발된다. 따라서 총 4 가지 평가 설정이 있습니다. 여기는 부정적인 감정 통제를위한 LM 스테이에게 훈련하고 긍정적 인 프롬프트에 대해 평가하는 예를 보여줍니다.
우리의 코드는 훈련 된 모델을 스코어링하고 재사용하므로 모델을 한 번 훈련시키고 재 훈련없이 다른 설정에서 여러 번 평가할 수 있습니다.
TRIAL=sentiment-gpt2-large
mkdir -p logs/$TRIAL
source=positive
control=-5
PYTHONPATH=. python experiments/training/train.py
--dataset_name sentiment-sst5
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --dummy_steer 1 --rank 1000
--batch_size 32 --max_length 256
--n_steps 1000 --lr 1e-2 --regularization 1e-6 --epsilon 1e-3
PYTHONPATH=. python experiments/training/generate.py
--eval_file data/prompts/sentiment_prompts-10k/${source}_prompts.jsonl
--output_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--ckpt_name logs/$TRIAL/checkpoint.pt
--model gpt2-large --cuda
--adaptor_class multiply --num_steers 2 --rank 1000
--max_length 256 --verbose --steer_values ${control} 1 --top_p 0.9
python experiments/evaluation/evaluate.py
--generations_file logs/$TRIAL/predictions-${source}_${control}.jsonl
--metrics sentiment,ppl-big,dist-n
--output_file result_stats_${source}_${control}.txt
echo "Sentiment control results:"
cat logs/$TRIAL/result_stats_${source}_${control}.txt
우리는 스크립트 experiments/pca_analysis.py 사용하여 해독 작업과 가장 관련이있는 단어 임베딩 크기를 해석합니다. 스크립트를 실행하려면 관점 API에 대한 훈련 된 LM 스테어 체크 포인트 및 GOOGLE_API_KEY 환경 변수로가는 경로를 지정해야합니다.
훈련 된 LM Steer Checkpoint의 경로로 $PATH_TO_CHECKPOINT 지정하십시오.
PYTHONPATH=. python experiments/pca_analysis.py
$PATH_TO_CHECKPOINT
훈련 된 LM 스테이터를 한 모델에서 다른 모델로 옮길 수 있습니다. 훈련 된 LM Steer Checkpoint의 경로로 $CHECKPOINT1 지정하고 $CHECKPOINT2 대상 모델 체크 포인트의 경로로 지정하십시오. 다음은 GPT2-LARGE에서 GPT2-MEDIUM으로 LM 스테이에게 전송하는 예입니다.
PYTHONPATH=. python experiments/steer_transfer.py
--ckpt_name $CHECKPOINT1
--n_steps 5000 --lr 0.01 --top_k 10000
--model_name gpt2-medium
--transfer_from gpt2-large
--output_file $CHECKPOINT2
텍스트 스타일을보다 세밀하게 제어하기 위해 여러 LM- 스티어를 구성하거나 LM을 지속적으로 조종 할 수 있습니다. 연속 스티어링의 경우, 다른 스티어링 효과에 대해 --steer_values 3 1 , --steer_values 0 1 , 또는 --steer_values -1 1 과 같은 교육 스크립트에서 steer_values 매개 변수를 단순히 방해 할 수 있습니다.
여러 LM-Steers를 작성하려면 LM-Steers의 행렬을 추가하고 합을 최종 LM 스테이터로 사용할 수 있습니다. 또는 LM-Steers lm_steer/models/steer.py 연결하고 연결된 텐서 ( self.projector1 및 self.projector2 속성의 더 긴 행렬 목록입니다.
이 저장소가 도움이되면 우리의 논문을 인용하는 것을 고려하십시오.
@article{han2023lm,
title={Lm-switch: Lightweight language model conditioning in word embedding space},
author={Han, Chi and Xu, Jialiang and Li, Manling and Fung, Yi and Sun, Chenkai and Jiang, Nan and Abdelzaher, Tarek and Ji, Heng},
journal={arXiv preprint arXiv:2305.12798},
year={2023}
}


