regression transformer
paper-reproduction
多任务变压器将回归重新定义为条件序列建模任务。这产生了一个二分法模型,该模型将回归与财产驱动的条件产生无缝整合。

此存储库包含开发代码。阅读自然机器智能中的论文。
?在拥抱面空间上可以使用带有简单UI的Gradio演示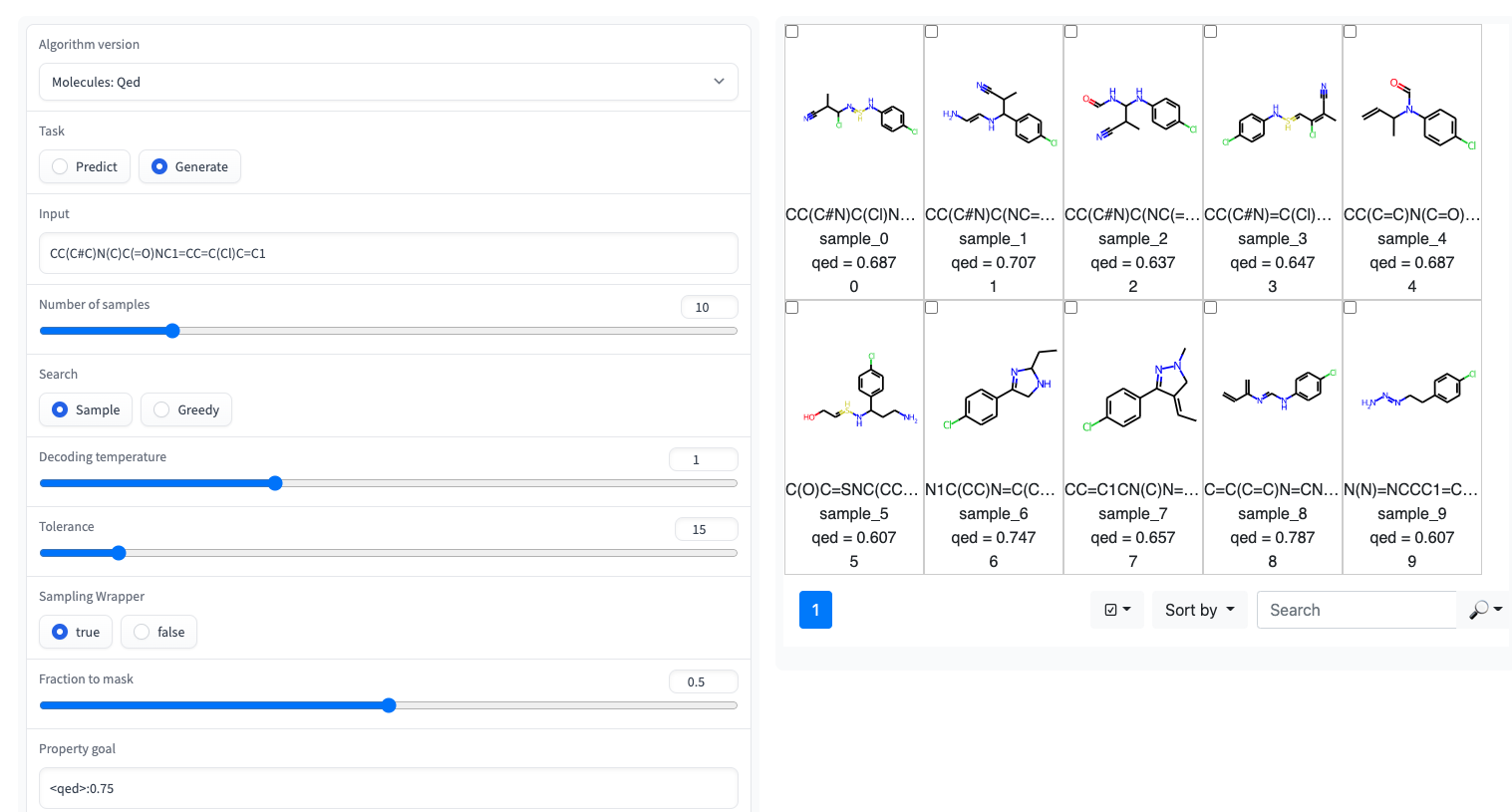
回归变压器在GT4SD库中实现。通过GT4SD,使用几个验证的回归变形物是几行代码的问题。可以在此处找到一个完整的跑步推理,对RT模型(或从头开始训练)以及将其共享并部署到GT4SD模型中心的教程。
例如,通过GT4SD,您可以在纸张中所示的某些特性上使用的RT使用,尤其是QED和ESOL(水溶性)。 RT也有几种多层变体:例如,在LOGP和合成性(又称SCSCORE)的联合训练的模型。对于蛋白质语言建模,您还将发现从磁带基准测试的肽稳定性数据集上训练的RT。总而言之,GT4SD提供了鉴定的RT模型:
qed , esol , crippen_logp )或多个( logp_and_synthesizability , cosmo_acdl , pfas )属性。除了使用笑容crippen_logp外,所有这些模型都使用自拍照。stabilityuspto (使用反应微笑)rop_catalyst和block_copolymer均在Park等人(2023; Nature Communications )中描述。 rop_catalyst使用常规自拍照,但block_copolymer模型使用了一种新型聚合物语言,称为CMDL,在Park等人(2023; Nature Communications )中也描述了。GT4SD也提供了一个带有玩具用途酶的jupyter笔记本,该笔记本也提供了适应分子的溶解度。如果您使用GT4SD,则可以产生这样的分子:
from gt4sd . algorithms . conditional_generation . regression_transformer import (
RegressionTransformer , RegressionTransformerMolecules
)
buturon = "CC(C#C)N(C)C(=O)NC1=CC=C(Cl)C=C1"
target_esol = - 3.53
config = RegressionTransformerMolecules (
algorithm_version = "solubility" ,
search = "sample" ,
temperature = 2 ,
tolerance = 5 ,
sampling_wrapper = {
'property_goal' : { '<esol>' : target_esol },
'fraction_to_mask' : 0.2
}
)
esol_generator = RegressionTransformer ( configuration = config , target = buturon )
generations = list ( esol_generator . sample ( 8 ))探索Buturon周围局部化学空间的溶解度。改变属性底漆后,您可能会得到这样的东西: 
这主要旨在复制或扩展纸张的结果。
conda env create -f conda.yml
conda activate terminator
pip install -e .用于训练模型的处理数据可通过框获得。
您可以下载数据并通过指向培训和测试数据来启动培训:
python scripts/run_language_modeling.py --output_dir rt_example
--config_name configs/rt_small.json --tokenizer_name ./vocabs/smallmolecules.txt
--do_train --do_eval --learning_rate 1e-4 --num_train_epochs 5 --save_total_limit 2
--save_steps 500 --per_gpu_train_batch_size 16 --evaluate_during_training --eval_steps 5
--eval_data_file ./examples/qed_property_example.txt --train_data_file ./examples/qed_property_example.txt
--line_by_line --block_size 510 --seed 42 --logging_steps 100 --eval_accumulation_steps 2
--training_config_path training_configs/qed_alternated_cc.jsontraining_config_path参数指向指定培训制度的文件。这是可选的,如果没有给出该参数,我们默认为均等的香草PLM训练,以同等的概率掩盖各地(仅用于初始预处理)。有关精致的示例,请参阅training_configs文件夹。
另请注意, vocabs夹包含用于小分子,蛋白质和化学反应训练的词汇文件。
可以在Configs文件夹中找到示例性的模型配置(头部,图层等)。
要评估经过训练的模型,例如,在QED任务上,运行以下内容:
python scripts/eval_language_modeling.py --output_dir path_to_model
--eval_file ./examples/qed_property_example.txt --eval_accumulation_steps 2 --param_path configs/qed_eval.json预审计的模型可通过GT4SD模型中心可用。总共有9个型号也可以通过拥抱面空间使用。作为出版物一部分的模型也可以通过上面提到的盒子文件夹获得。
要以RT兼容格式为QED任务生成自定义数据,请运行脚本/generate_example_data.py,并指向第一列中带有笑容的.smi文件。
python scripts/generate_example_data.py examples/example.smi examples/qed_property_example.txt对于用户定义的属性,请调整文件或打开问题。
如果您需要为数据集创建一个新的词汇,则可以使用脚本/create_vocabulary.py。它也将自动在词汇文件的顶部添加一些特殊令牌。
python scripts/create_vocabulary.py examples/qed_property_example.txt examples/vocab.txt此时,包含词汇文件的文件夹可用于加载与任何ExpressionBertTokenizer兼容的令牌:
> >> from terminator . tokenization import ExpressionBertTokenizer
> >> tokenizer = ExpressionBertTokenizer . from_pretrained ( 'examples' )
> >> text = '<qed>0.3936|CBr'
> >> tokens = tokenizer . tokenize ( text )
> >> print ( tokens )
[ '<qed>' , '_0_0_' , '_._' , '_3_-1_' , '_9_-2_' , '_3_-3_' , '_6_-4_' , '|' , 'C' , 'Br' ]
> >> token_indexes = tokenizer . convert_tokens_to_ids ( tokenizer . tokenize ( text ))
> >> print ( token_indexes )
[ 16 , 17 , 18 , 28 , 45 , 34 , 35 , 19 , 15 , 63 ]
> >> tokenizer . build_inputs_with_special_tokens ( token_indexes )
[ 12 , 16 , 17 , 18 , 28 , 45 , 34 , 35 , 19 , 15 , 63 , 13 ]如果您使用回归变压器,请引用:
@article { born2023regression ,
title = { Regression Transformer enables concurrent sequence regression and generation for molecular language modelling } ,
author = { Born, Jannis and Manica, Matteo } ,
journal = { Nature Machine Intelligence } ,
volume = { 5 } ,
number = { 4 } ,
pages = { 432--444 } ,
year = { 2023 } ,
publisher = { Nature Publishing Group UK London }
}

