regression transformer
paper-reproduction
조건부 시퀀스 모델링 작업으로 회귀를 재구성하는 멀티 태스킹 변압기. 이는 회귀를 재산 중심 조건부 생성과 완벽하게 통합하는 이분법적인 언어 모델을 생성합니다.

이 repo에는 개발 코드가 포함되어 있습니다. Nature Machine Intelligence 의 논문을 읽으십시오.
? Huggingface 공간에서 간단한 UI가있는 Gradio Demo를 사용할 수 있습니다. 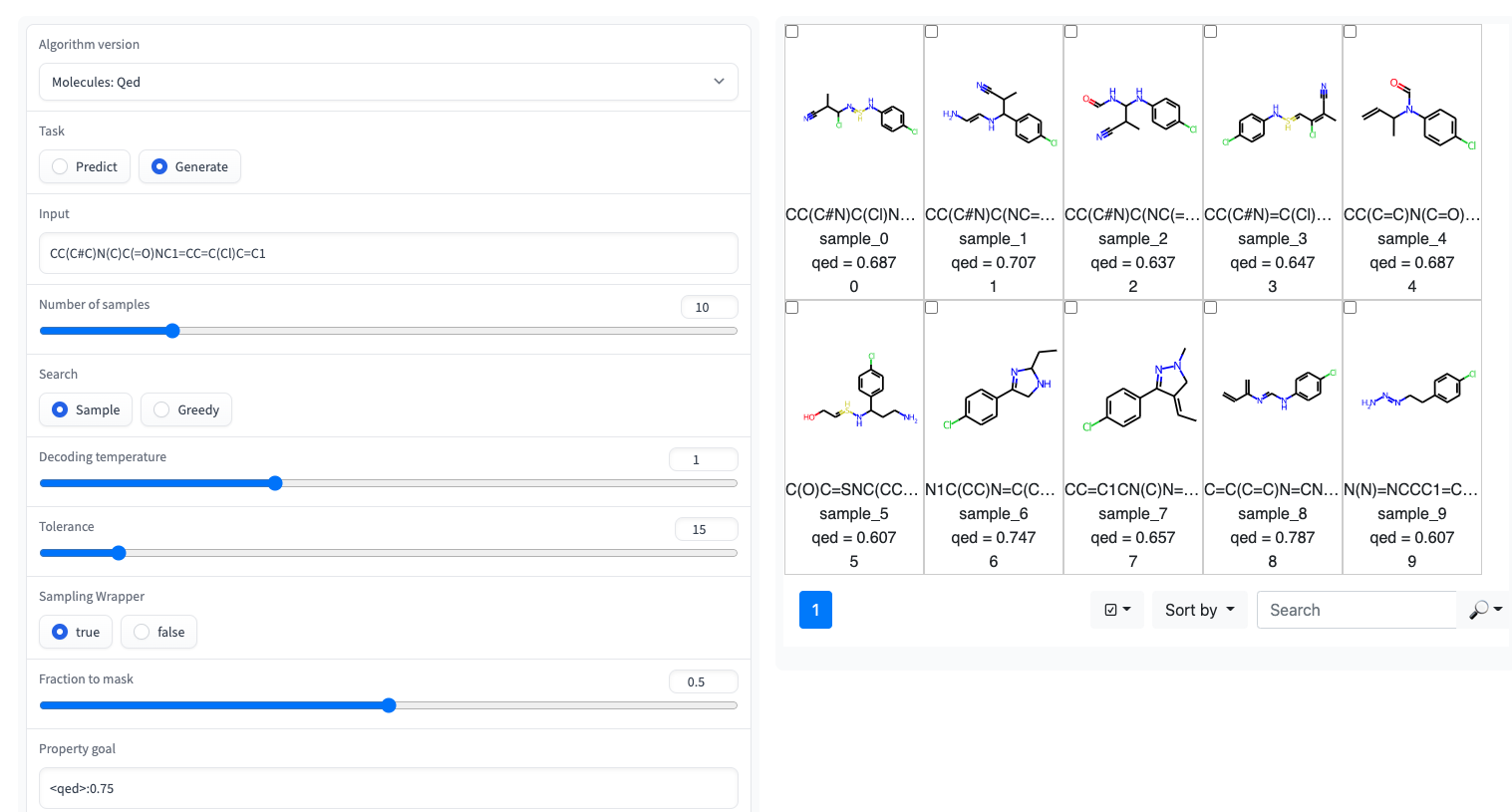
회귀 변압기는 GT4SD 라이브러리에서 구현됩니다. GT4SD를 통해 몇 개의 사전 전환 회귀 변환기를 사용하는 것은 몇 줄의 코드의 문제입니다. 추론 실행, RT 모델을 미세 조정 (또는 처음부터 훈련) 및 GT4SD 모델 허브에 공유하고 배포하는 전체 튜토리얼은 여기에서 찾을 수 있습니다.
예를 들어, GT4SD를 통해 논문에 표시된 것처럼 일부 특성, 특히 QED 및 ESOL (물 용해도)이있는 소분자에 사전 배치 된 RT를 사용할 수 있습니다. 또한 RT의 다중 프로퍼 변이체가 있으며, 예를 들어, 로그인 및 합성 성 (일명 SCSCORE)에서 공동으로 훈련 된 모델입니다. 단백질 언어 모델링의 경우 테이프 벤치 마크에서 펩티드 안정성 데이터 세트에 대한 RT를 찾을 수 있습니다. 요약하면, GT4SD는 다음에 사전에 RT 모델을 제공합니다.
qed , esol , crippen_logp ) 또는 다중 ( logp_and_synthesizability , cosmo_acdl , pfas ) 특성. 이러한 모든 모델은 Smiles를 사용하는 crippen_logp 제외하고 셀카를 사용합니다.stabilityuspto (반응 스마일 사용)rop_catalyst 및 block_copolymer 모두 Park et al. (2023; Nature Communications )에 설명되어 있습니다. rop_catalyst 기존의 셀카를 사용하지만 block_copolymer 모델은 Park et al. (2023; Nature Communications )에 설명 된 CMDL이라는 새로운 중합체 언어를 사용합니다.용해도를 향한 분자를 적응시키는 장난감 usecase가 장착 된 Jupyter 노트북도 GT4SD로도 제공됩니다. GT4SD를 사용하는 경우 다음과 같은 분자를 생성 할 수 있습니다.
from gt4sd . algorithms . conditional_generation . regression_transformer import (
RegressionTransformer , RegressionTransformerMolecules
)
buturon = "CC(C#C)N(C)C(=O)NC1=CC=C(Cl)C=C1"
target_esol = - 3.53
config = RegressionTransformerMolecules (
algorithm_version = "solubility" ,
search = "sample" ,
temperature = 2 ,
tolerance = 5 ,
sampling_wrapper = {
'property_goal' : { '<esol>' : target_esol },
'fraction_to_mask' : 0.2
}
)
esol_generator = RegressionTransformer ( configuration = config , target = buturon )
generations = list ( esol_generator . sample ( 8 )) 버터론 주변의 지역 화학 공간의 용해도를 탐색하십시오. 속성 프라이머를 변경하면 다음과 같은 것을 얻을 수 있습니다. 
이것은 주로 논문의 결과를 재현하거나 확장하기위한 것입니다.
conda env create -f conda.yml
conda activate terminator
pip install -e .모델을 훈련시키는 데 사용되는 처리 된 데이터는 상자를 통해 사용할 수 있습니다.
데이터를 다운로드하고 데이터를 훈련시키고 테스트하여 교육을 시작할 수 있습니다.
python scripts/run_language_modeling.py --output_dir rt_example
--config_name configs/rt_small.json --tokenizer_name ./vocabs/smallmolecules.txt
--do_train --do_eval --learning_rate 1e-4 --num_train_epochs 5 --save_total_limit 2
--save_steps 500 --per_gpu_train_batch_size 16 --evaluate_during_training --eval_steps 5
--eval_data_file ./examples/qed_property_example.txt --train_data_file ./examples/qed_property_example.txt
--line_by_line --block_size 510 --seed 42 --logging_steps 100 --eval_accumulation_steps 2
--training_config_path training_configs/qed_alternated_cc.jsontraining_config_path 인수는 훈련 체제를 지정하는 파일을 가리 킵니다. 이것은 선택 사항입니다. 인수가 주어지지 않으면 우리는 기본적으로 바닐라 PLM 훈련을 기본값으로하여 모든 곳을 동일한 확률로 마스킹합니다 (초기 전 사전 조정에만 권장됨). 정제 된 예는 training_configs 폴더를 참조하십시오.
또한 vocabs 폴더에는 소분자, 단백질 및 화학 반응에 대한 교육을위한 어휘 파일이 포함되어 있습니다.
예시 모델 구성 (헤드 수, 레이어 수 등)은 구성 폴더에서 찾을 수 있습니다.
QED 작업에서 교육을받은 모델을 평가하려면 다음을 실행하십시오.
python scripts/eval_language_modeling.py --output_dir path_to_model
--eval_file ./examples/qed_property_example.txt --eval_accumulation_steps 2 --param_path configs/qed_eval.json사전 배치 된 모델은 GT4SD 모델 허브를 통해 사용할 수 있습니다. Huggingface 공간을 통해 사용할 수있는 총 9 개의 모델이 있습니다. 출판물의 일부인 모델은 위에서 언급 한 상자 폴더를 통해도 제공됩니다.
RT 호환 형식으로 QED 작업에 대한 사용자 정의 데이터를 생성하려면 스크립트/Generate_Example_Data.py를 실행하고 첫 번째 열에 미소가있는 .smi 파일을 가리 킵니다.
python scripts/generate_example_data.py examples/example.smi examples/qed_property_example.txt사용자 정의 속성의 경우 파일을 조정하거나 문제를여십시오.
데이터 세트에 대한 새로운 어휘를 작성 해야하는 경우 스크립트/create_vocabulary.py를 사용할 수 있습니다. 또한 어휘 파일 상단에 특수 토큰을 자동으로 추가합니다.
python scripts/create_vocabulary.py examples/qed_property_example.txt examples/vocab.txt 이 시점에서 어휘 파일을 포함하는 폴더는 모든 ExpressionBertTokenizer 와 호환되는 토큰 화제를로드하는 데 사용될 수 있습니다.
> >> from terminator . tokenization import ExpressionBertTokenizer
> >> tokenizer = ExpressionBertTokenizer . from_pretrained ( 'examples' )
> >> text = '<qed>0.3936|CBr'
> >> tokens = tokenizer . tokenize ( text )
> >> print ( tokens )
[ '<qed>' , '_0_0_' , '_._' , '_3_-1_' , '_9_-2_' , '_3_-3_' , '_6_-4_' , '|' , 'C' , 'Br' ]
> >> token_indexes = tokenizer . convert_tokens_to_ids ( tokenizer . tokenize ( text ))
> >> print ( token_indexes )
[ 16 , 17 , 18 , 28 , 45 , 34 , 35 , 19 , 15 , 63 ]
> >> tokenizer . build_inputs_with_special_tokens ( token_indexes )
[ 12 , 16 , 17 , 18 , 28 , 45 , 34 , 35 , 19 , 15 , 63 , 13 ]회귀 변압기를 사용하는 경우 다음을 인용하십시오.
@article { born2023regression ,
title = { Regression Transformer enables concurrent sequence regression and generation for molecular language modelling } ,
author = { Born, Jannis and Manica, Matteo } ,
journal = { Nature Machine Intelligence } ,
volume = { 5 } ,
number = { 4 } ,
pages = { 432--444 } ,
year = { 2023 } ,
publisher = { Nature Publishing Group UK London }
}

