VLM2Vec
1.0.0
该仓库包含VLM2VEC的代码和数据:大规模多模式嵌入任务的训练视觉语言模型。在本文中,我们旨在为任何任务构建统一的多模式嵌入模型。
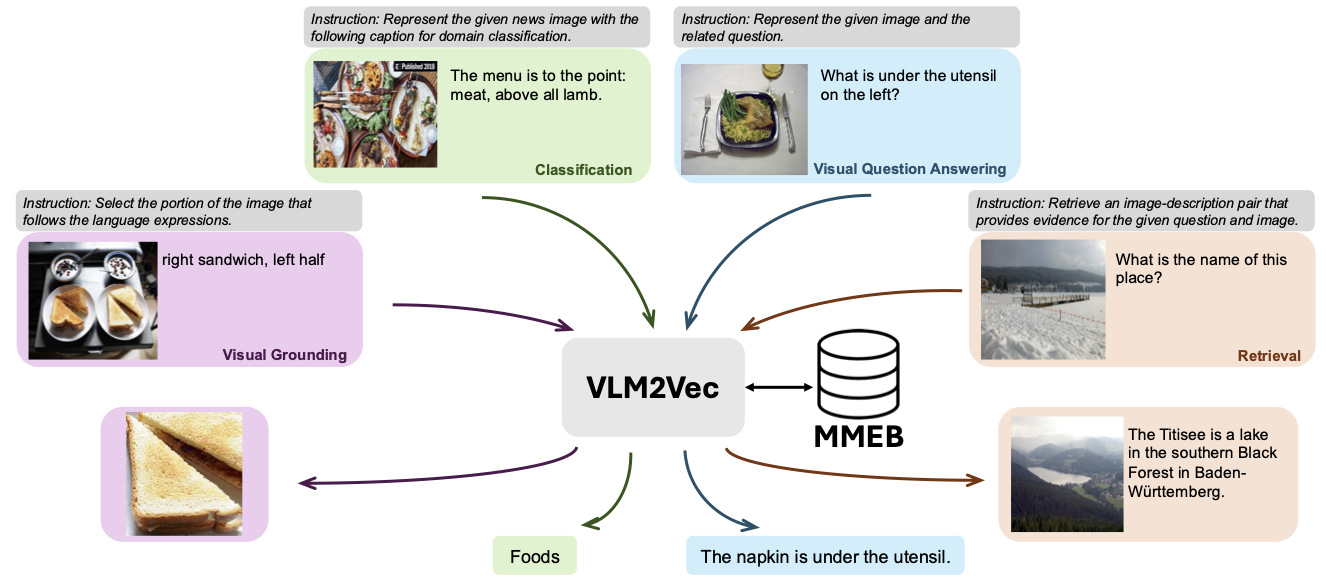
我们的模型基于将现有训练有素的VLM转换为嵌入模型。基本思想是在序列的末尾将最后一个令牌作为多模式输入的表示。我们的VLM2VEC框架与任何SOTA开源VLM都兼容。通过利用各种训练数据(包括各种方式组合,任务和说明),它产生了强大的通用多模式嵌入模型。
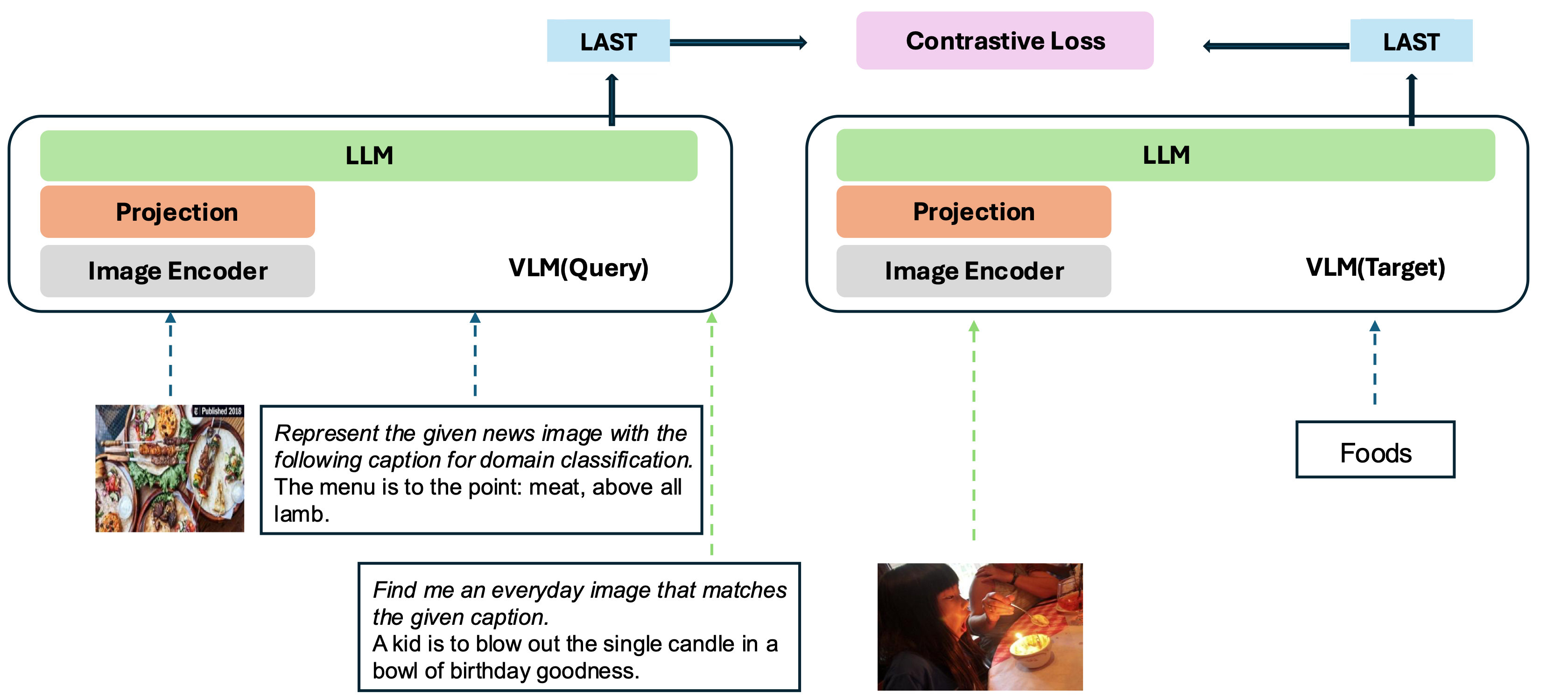
我们的模型正在MMEB-Train(20个任务)进行培训,并对MMEB-Eval进行评估(20个IND任务和16个OOD任务)。
我们的模型可以大大优于现有基准。 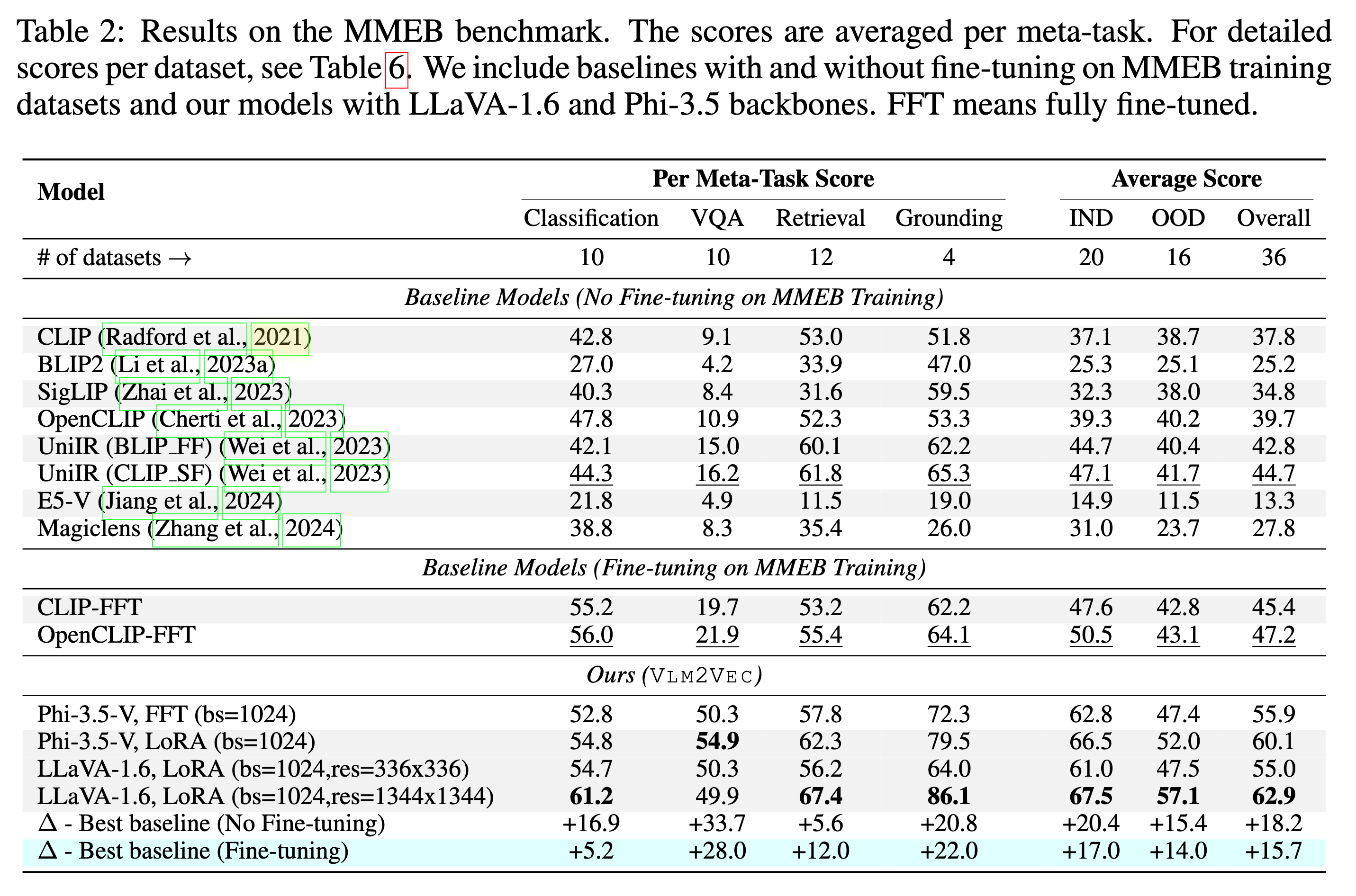
我们提供了几个示例,包括scripts/目录中的演示和评估代码。
从huggingface下载图像文件zip
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
对于具有较小内存的GPU,请使用GradCache减少内存使用情况,即将小值设置为--gc_q_chunk_size和--gc_p_chunk_size 。
使用--lora --lora_r 16启用Lora调音。
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 从huggingface下载图像文件zip
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


