VLM2Vec
1.0.0
Dieses Repo enthält den Code und die Daten für VLM2VEC: Trainingsvisionsprachenmodelle für massive multimodale Einbettungsaufgaben. In diesem Artikel zielten wir darauf ab, ein einheitliches multimodales Einbettungsmodell für alle Aufgaben aufzubauen.
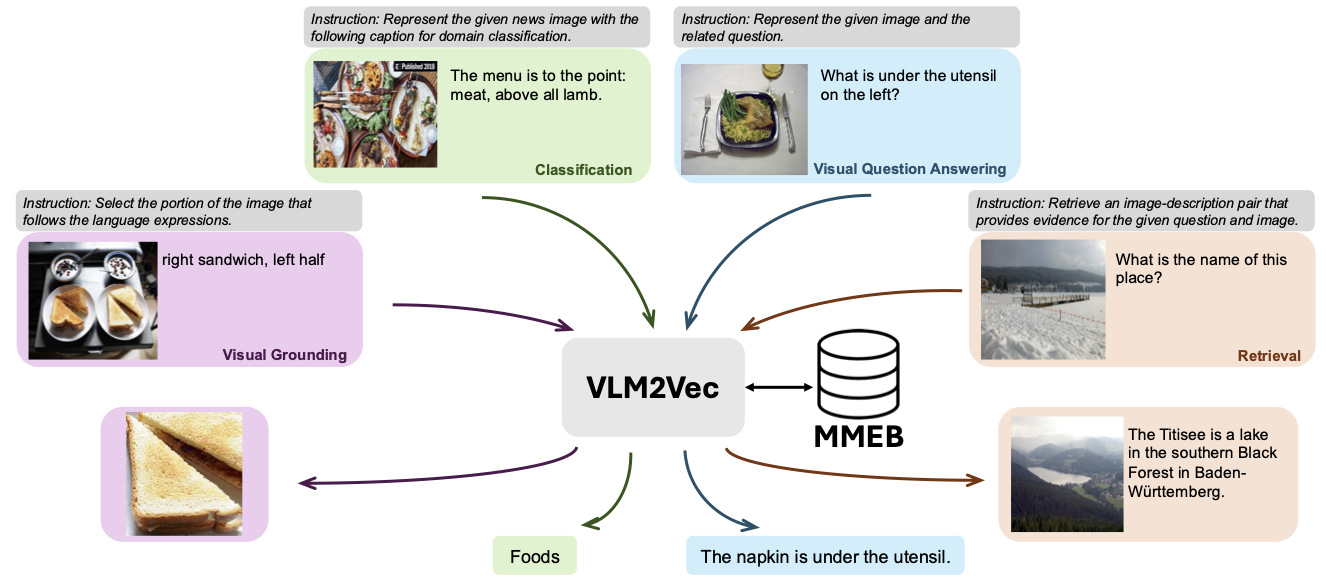
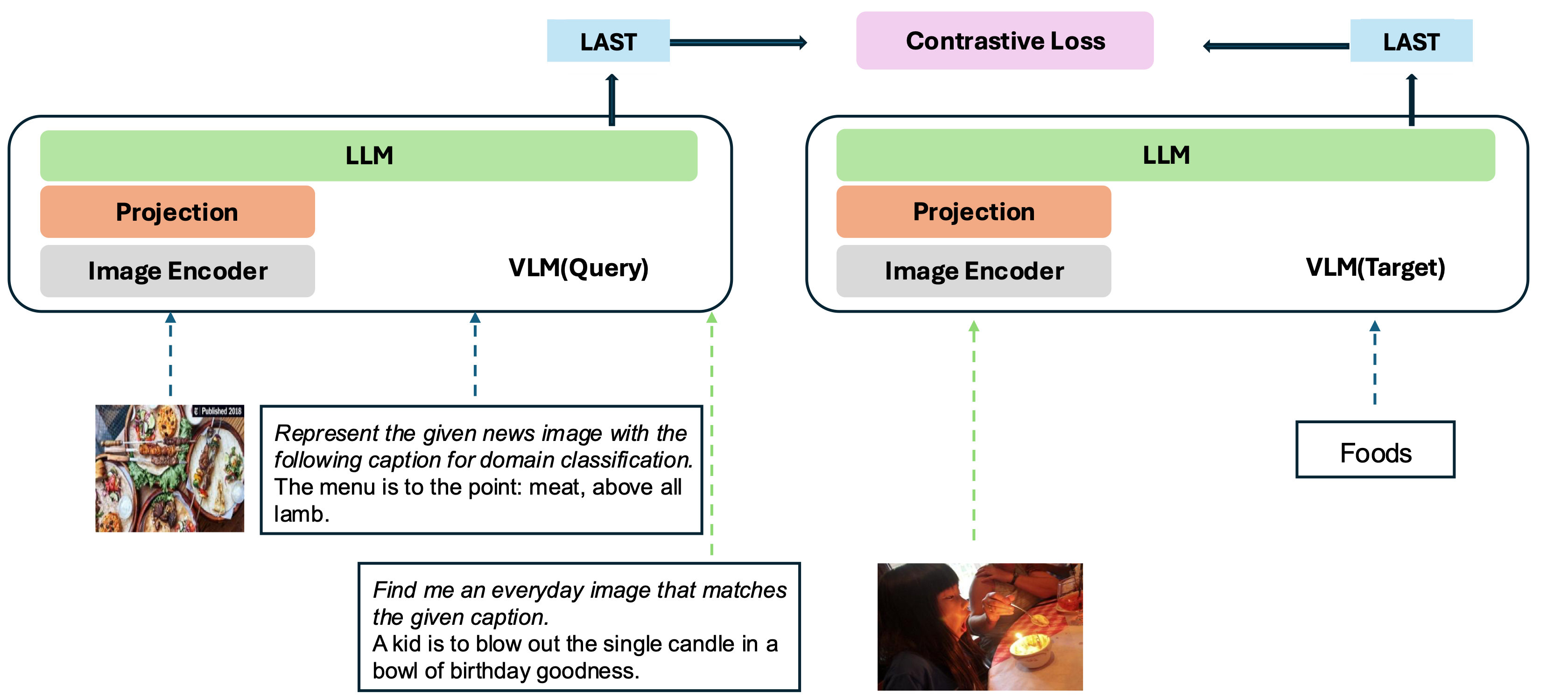
Unser Modell basiert auf der Umwandlung eines vorhandenen gut ausgebildeten VLM in ein Einbettungsmodell. Die Grundidee besteht darin, das letzte Token am Ende der Sequenz als Darstellung der multimodalen Eingänge zu nehmen. Unser VLM2VEC-Framework ist mit allen SOTA Open-Source-VLMs kompatibel. Durch die Nutzung verschiedener Trainingsdaten - die eine Vielzahl von Modalitätskombinationen, Aufgaben und Anweisungen enthält, erzeugt es ein robustes universelles multimodales Einbettungsmodell.
Unser Modell wird auf MMEB-Train ausgebildet (20 Aufgaben) und auf MMEB-Eval (20 IND-Aufgaben und 16 OOD-Aufgaben) bewertet.
Unser Modell kann die vorhandenen Baselines mit großem Rand übertreffen. 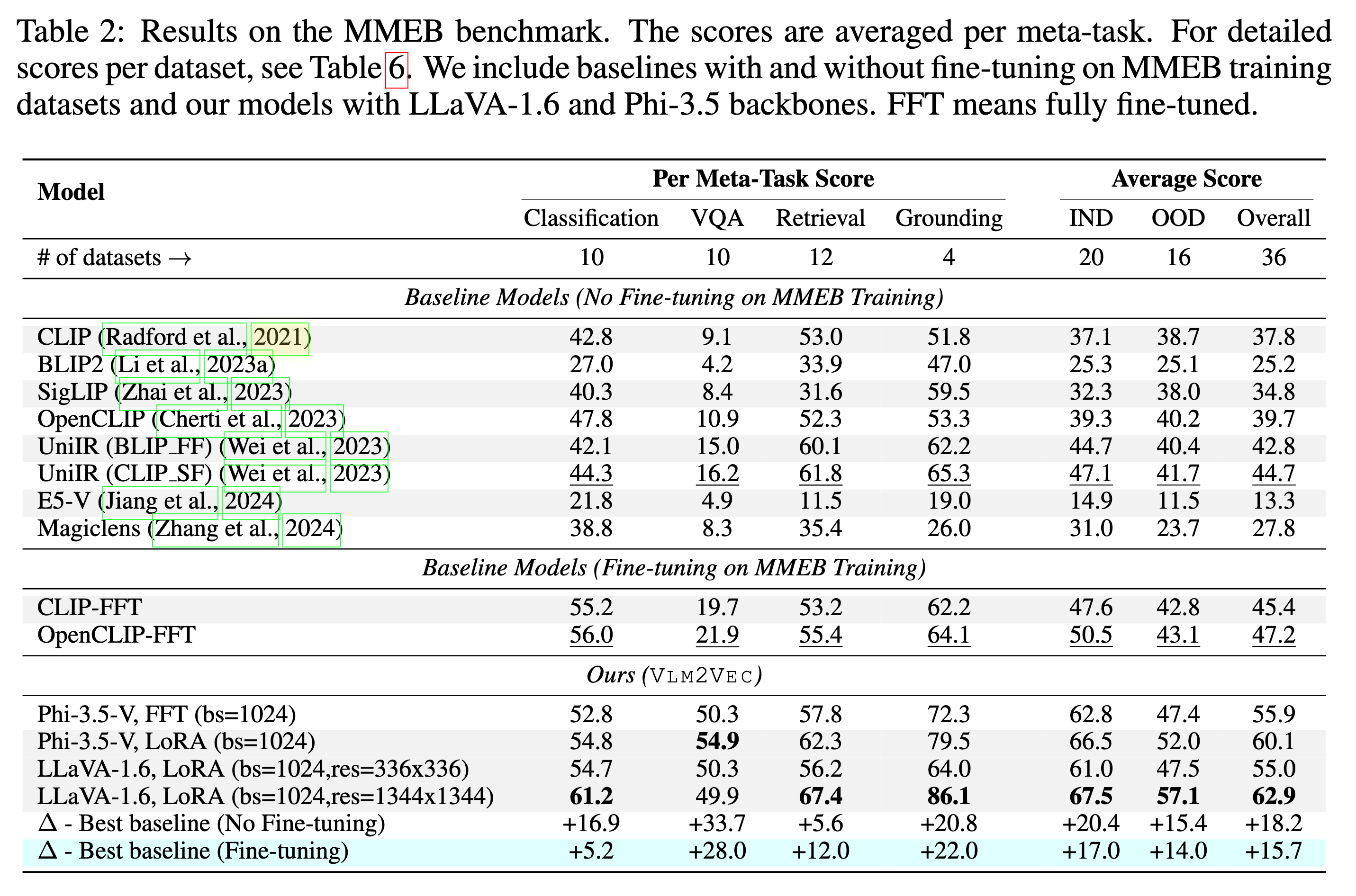
Wir haben mehrere Stichproben bereitgestellt, darunter Demonstrations- und Bewertungscode, die sich in den scripts/ Verzeichnissen befinden.
Laden Sie den Reißverschluss der Bilddatei von Suggingface herunter
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
Verwenden Sie für GPUs mit kleinem Speicher GradCache, um --gc_p_chunk_size --gc_q_chunk_size zu reduzieren.
Verwenden Sie --lora --lora_r 16 um die Lora -Abstimmung zu ermöglichen.
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 Laden Sie den Reißverschluss der Bilddatei von Suggingface herunter
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


