VLM2Vec
1.0.0
Ce dépôt contient le code et les données pour VLM2VEC: formation de modèles de langue de vision pour des tâches d'incorporation multimodales massives. Dans cet article, nous visions à construire un modèle d'incorporation multimodal unifié pour toutes les tâches.
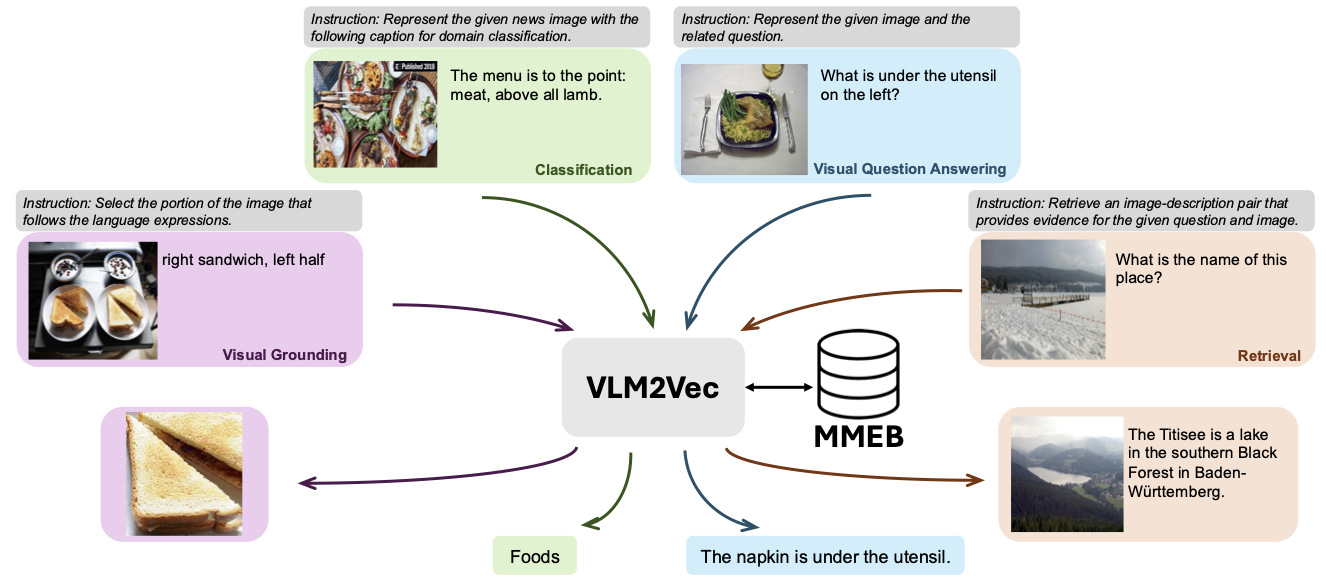
Notre modèle est basé sur la conversion d'un VLM bien entraîné existant en un modèle d'incorporation. L'idée de base est de prendre le dernier jeton à la fin de la séquence comme représentation des entrées multimodales. Notre cadre VLM2VEC est compatible avec tout VLMS open-source SOTA. En tirant parti de diverses données d'entraînement - engageant une variété de combinaisons, tâches et instructions de modalité - cela génère un modèle d'incorporation multimodal universel robuste.
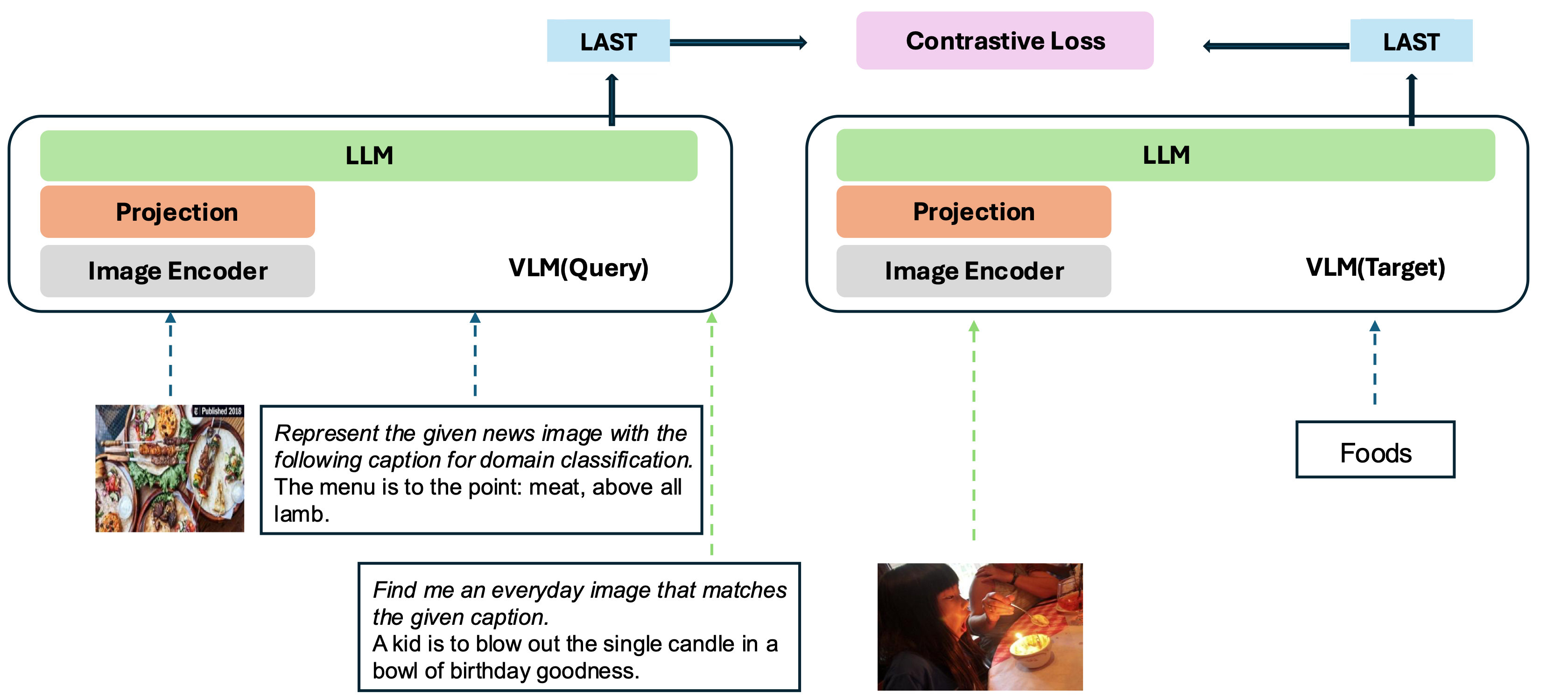
Notre modèle est formé sur MMEB-TRAIN (20 tâches) et évalué sur MMEB-EVAL (20 tâches IND et 16 tâches OOD).
Notre modèle peut surpasser les lignes de base existantes par une énorme marge. 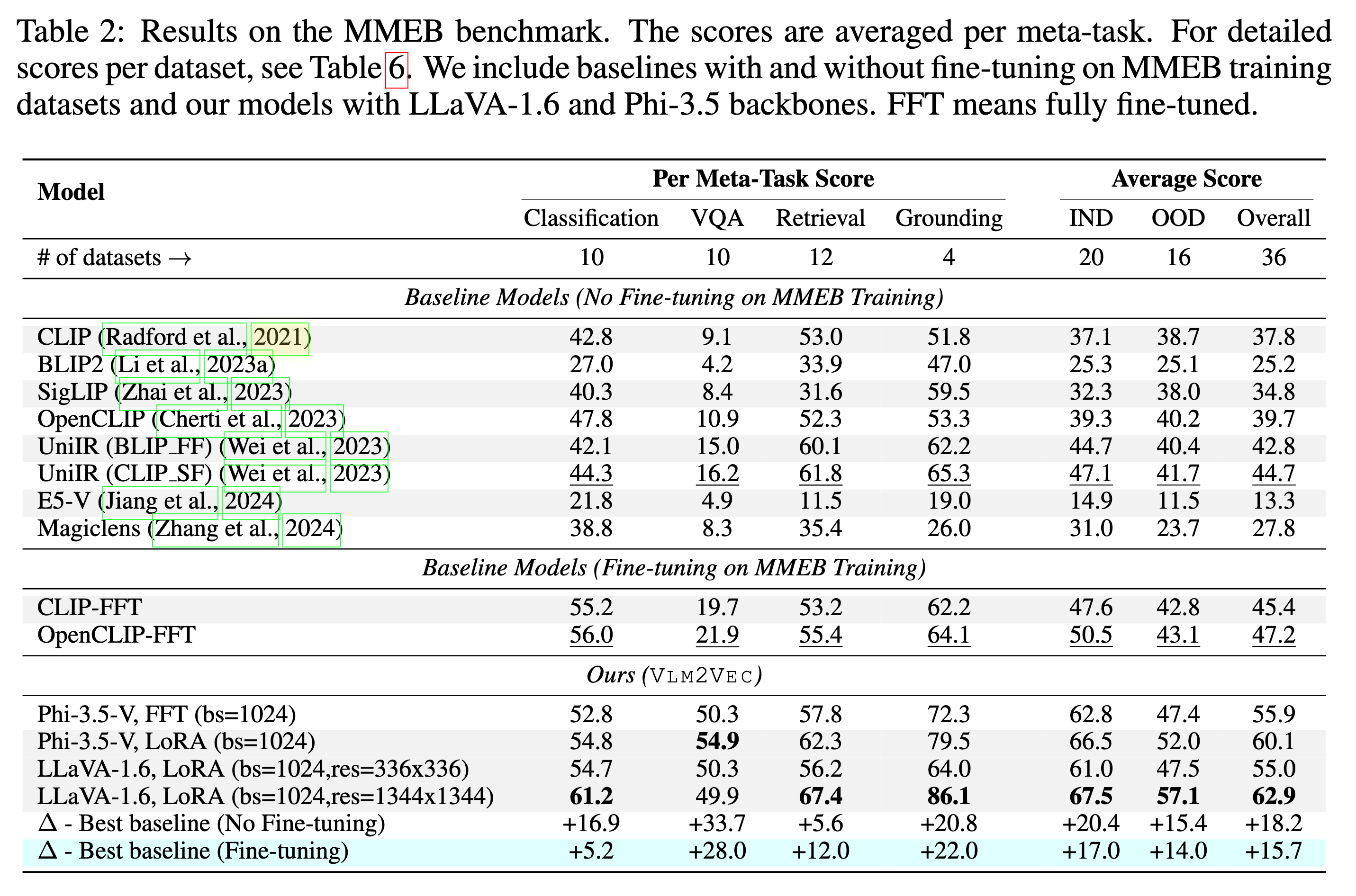
Nous avons fourni plusieurs échantillons, y compris le code de démonstration et d'évaluation, situé dans les scripts/ répertoire.
Téléchargez le fichier image zip depuis HuggingFace
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
Pour les GPU avec une petite mémoire, utilisez GradCache pour réduire l'utilisation de la mémoire, c'est-à-dire en définissant de petites valeurs sur --gc_q_chunk_size et --gc_p_chunk_size .
Utilisez --lora --lora_r 16 pour activer Lora Tuning.
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 Téléchargez le fichier image zip depuis HuggingFace
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


