VLM2Vec
1.0.0
repo นี้มีรหัสและข้อมูลสำหรับ VLM2VEC: การฝึกอบรมแบบจำลองภาษาวิสัยทัศน์สำหรับงานฝังตัวหลายรูปแบบ ในบทความนี้เรามุ่งเป้าไปที่การสร้างแบบจำลองการฝังแบบรวมหลายรูปแบบสำหรับงานใด ๆ
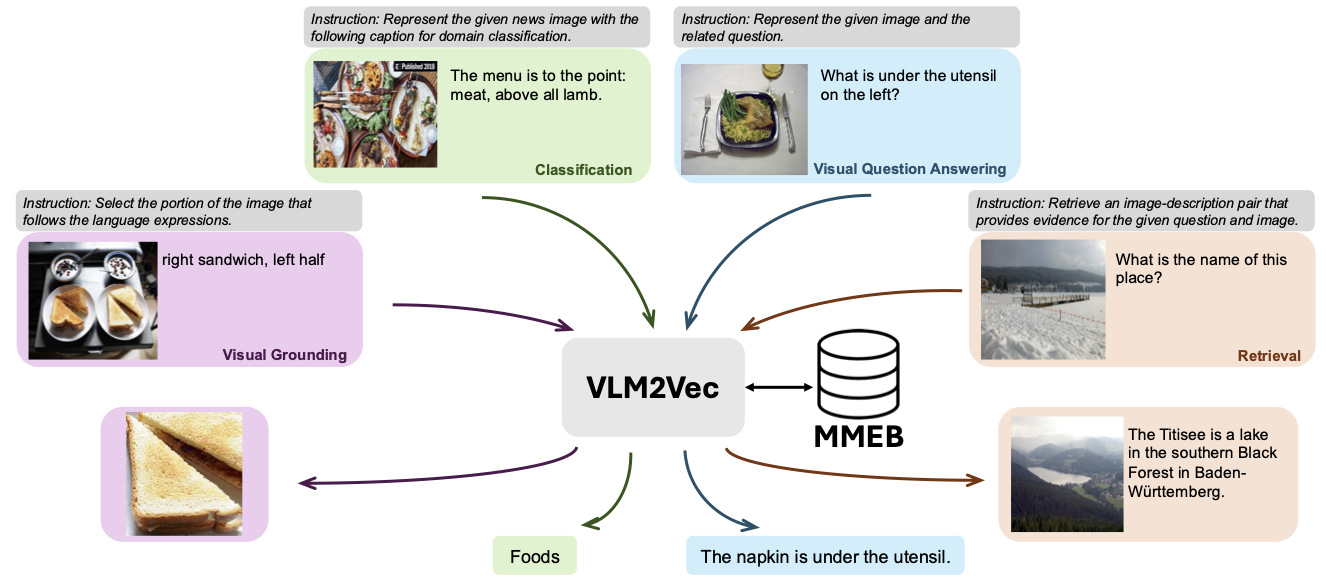
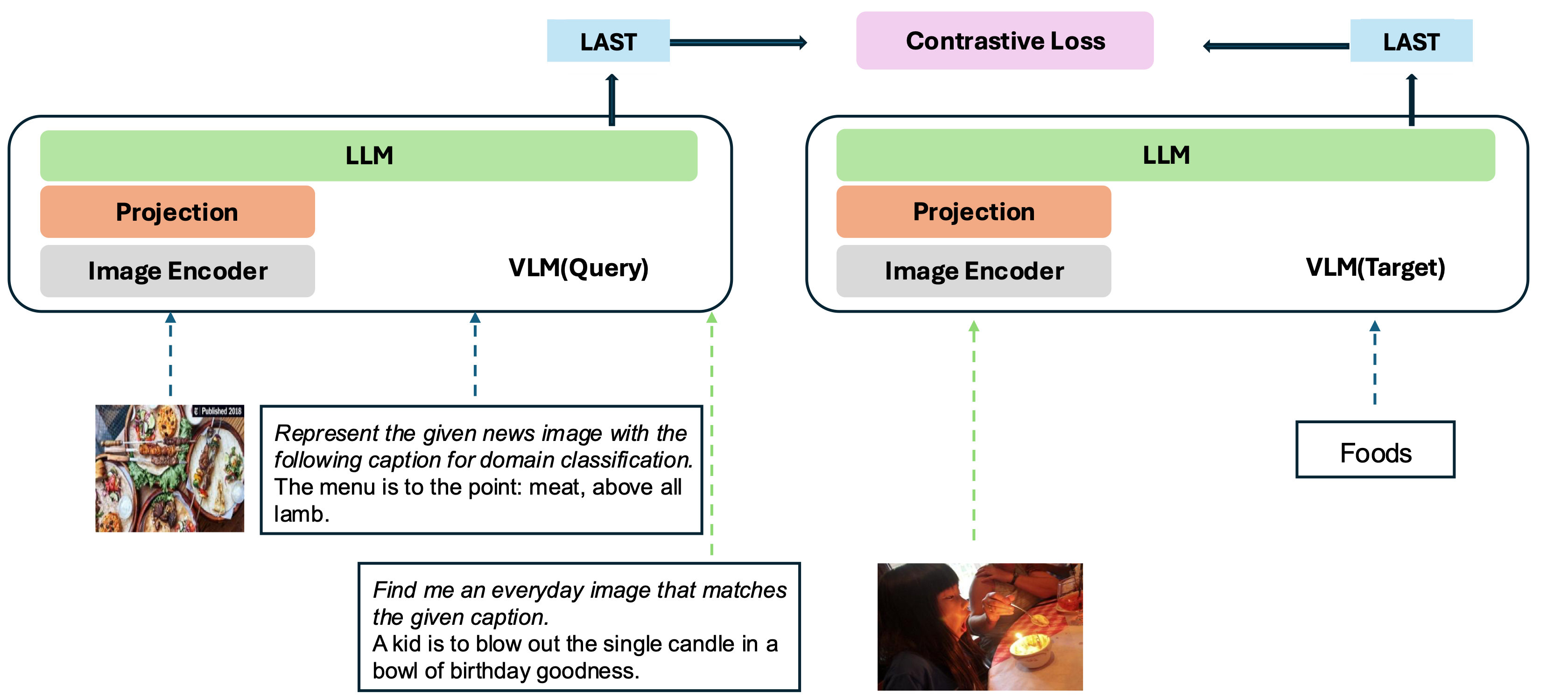
แบบจำลองของเราขึ้นอยู่กับการแปลง VLM ที่ผ่านการฝึกอบรมมาอย่างดีเป็นแบบจำลองการฝัง แนวคิดพื้นฐานคือการใช้โทเค็นสุดท้ายในตอนท้ายของลำดับเป็นตัวแทนของอินพุตหลายรูปแบบ เฟรมเวิร์ก VLM2VEC ของเราเข้ากันได้กับ VLMS โอเพ่นซอร์ส SOTA ใด ๆ ด้วยการใช้ประโยชน์จากข้อมูลการฝึกอบรมที่หลากหลาย - รวบรวมการผสมผสานที่หลากหลายของรูปแบบงานและคำแนะนำ - มันสร้างรูปแบบการฝังแบบหลายรูปแบบสากลที่แข็งแกร่ง
แบบจำลองของเราได้รับการฝึกฝนเกี่ยวกับ MMEB-Train (20 งาน) และประเมินผลใน MMEB-EVAL (20 งาน IND และ 16 งาน OOD)
โมเดลของเราสามารถทำได้ดีกว่าเส้นใยที่มีอยู่โดยมีอัตรากำไรขั้นต้นขนาดใหญ่ 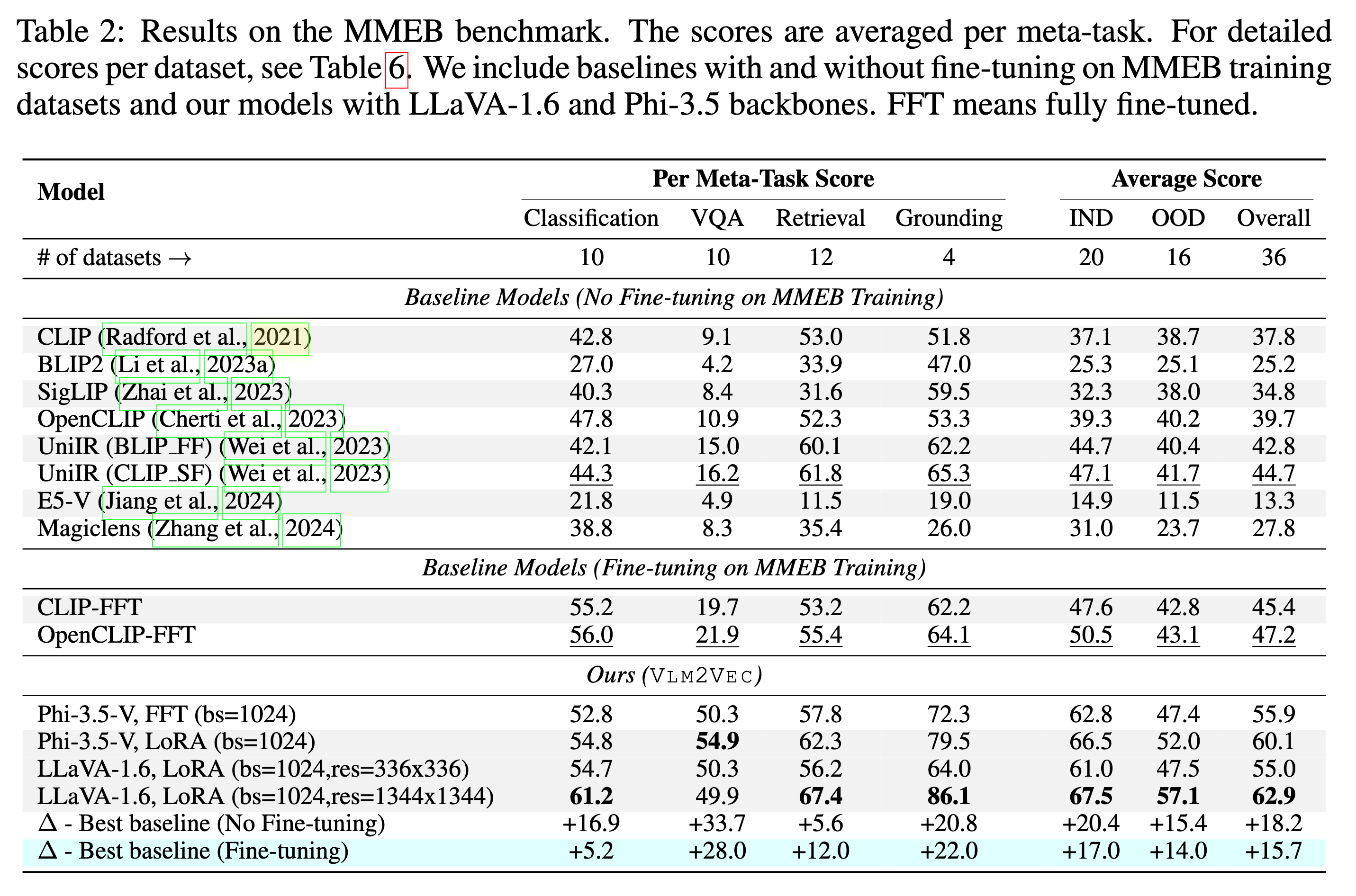
เราได้ให้ตัวอย่างหลายตัวอย่างรวมถึงการสาธิตและรหัสการประเมินผลซึ่งอยู่ใน scripts/ ไดเรกทอรี
ดาวน์โหลดซิปไฟล์รูปภาพจาก HuggingFace
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
สำหรับ GPU ที่มีหน่วยความจำขนาดเล็กให้ใช้ GradCache เพื่อลดการใช้หน่วยความจำเช่นการตั้งค่าค่าเล็ก ๆ เป็น --gc_q_chunk_size และ --gc_p_chunk_size
ใช้ --lora --lora_r 16 เพื่อเปิดใช้งานการปรับแต่ง LORA
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 ดาวน์โหลดซิปไฟล์รูปภาพจาก HuggingFace
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


