VLM2Vec
1.0.0
Этот репо содержит код и данные для VLM2VEC: обучение моделей на языке зрения для массовых задач мультимодального встраивания. В этой статье мы нацелились на создание унифицированной мультимодальной модели встраивания для любых задач.
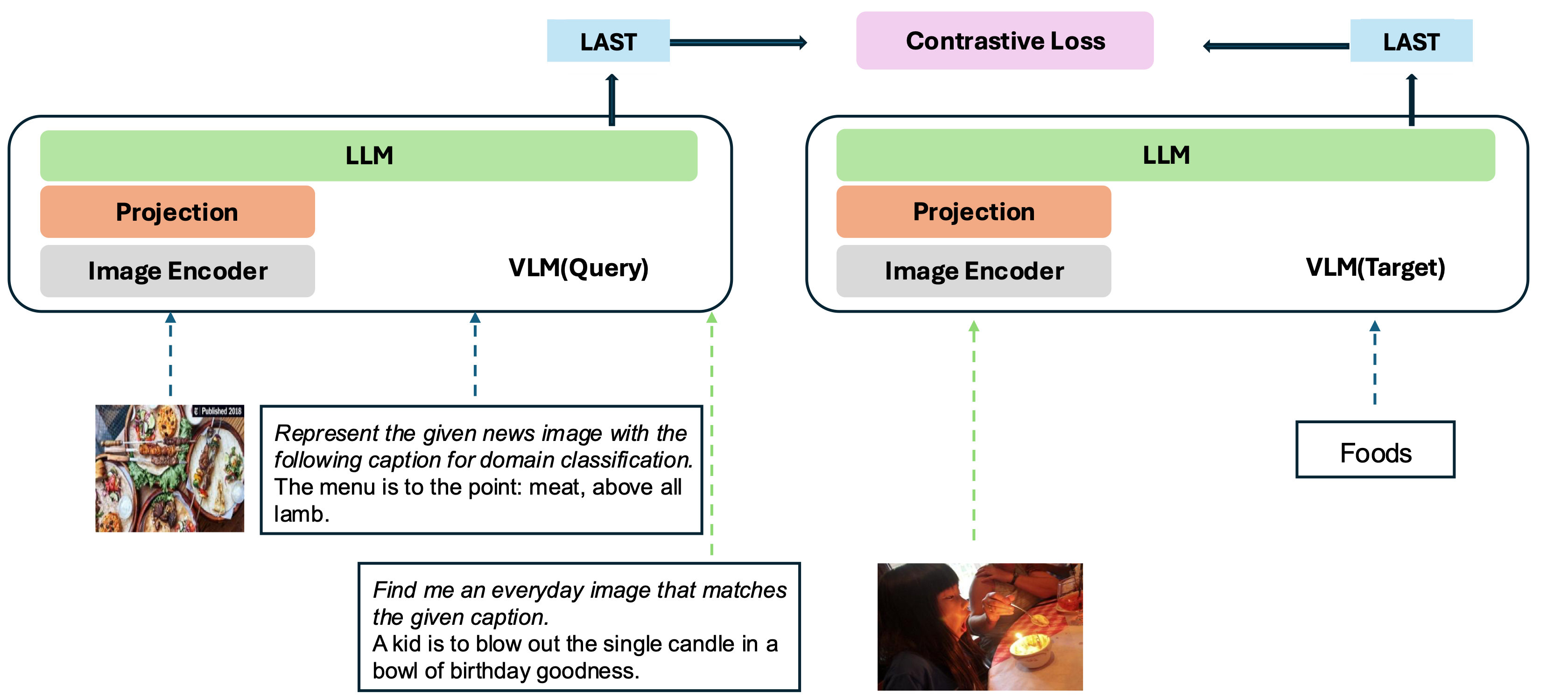
Наша модель основана на преобразовании существующего хорошо обученного VLM в модель встраивания. Основная идея состоит в том, чтобы взять последний токен в конце последовательности в качестве представления мультимодальных входов. Наша структура VLM2VEC совместима с любыми VLMS SOTA с открытым исходным кодом. Используя различные данные обучения, разжигая различные комбинации модальности, задачи и инструкции, он генерирует надежную универсальную мультимодальную модель встраивания.
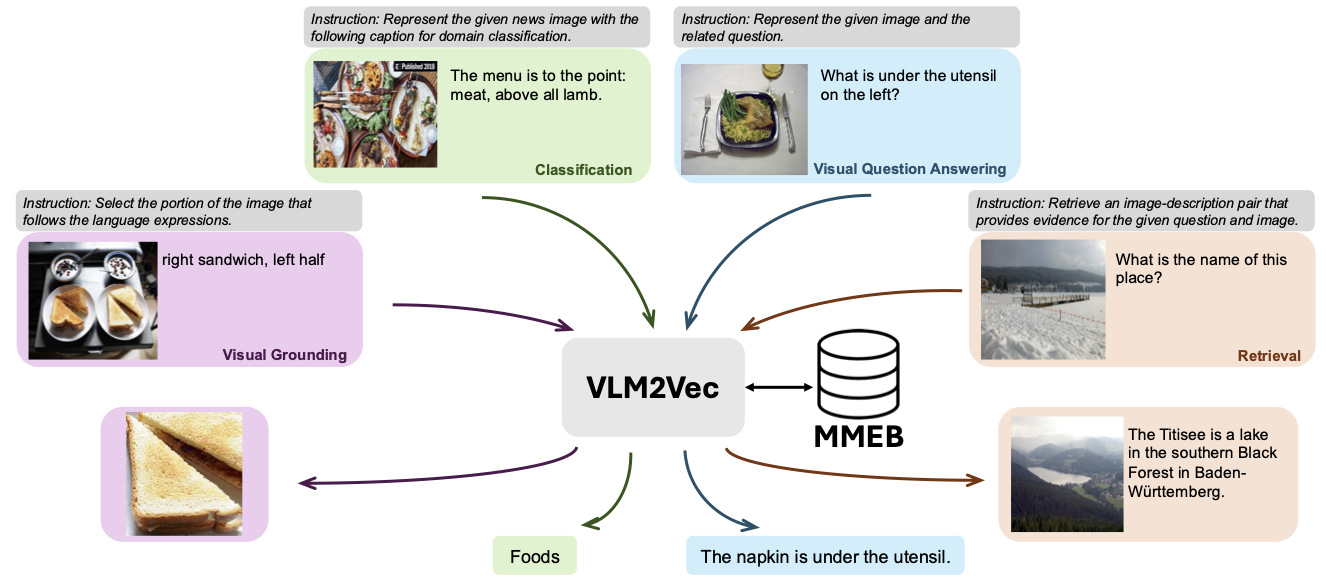
Наша модель обучается на MMEB-Train (20 задач) и оценивается на MMEB-eval (20 задач IND и 16 задач OOD).
Наша модель может превзойти существующие базовые показатели с огромным отрывом. 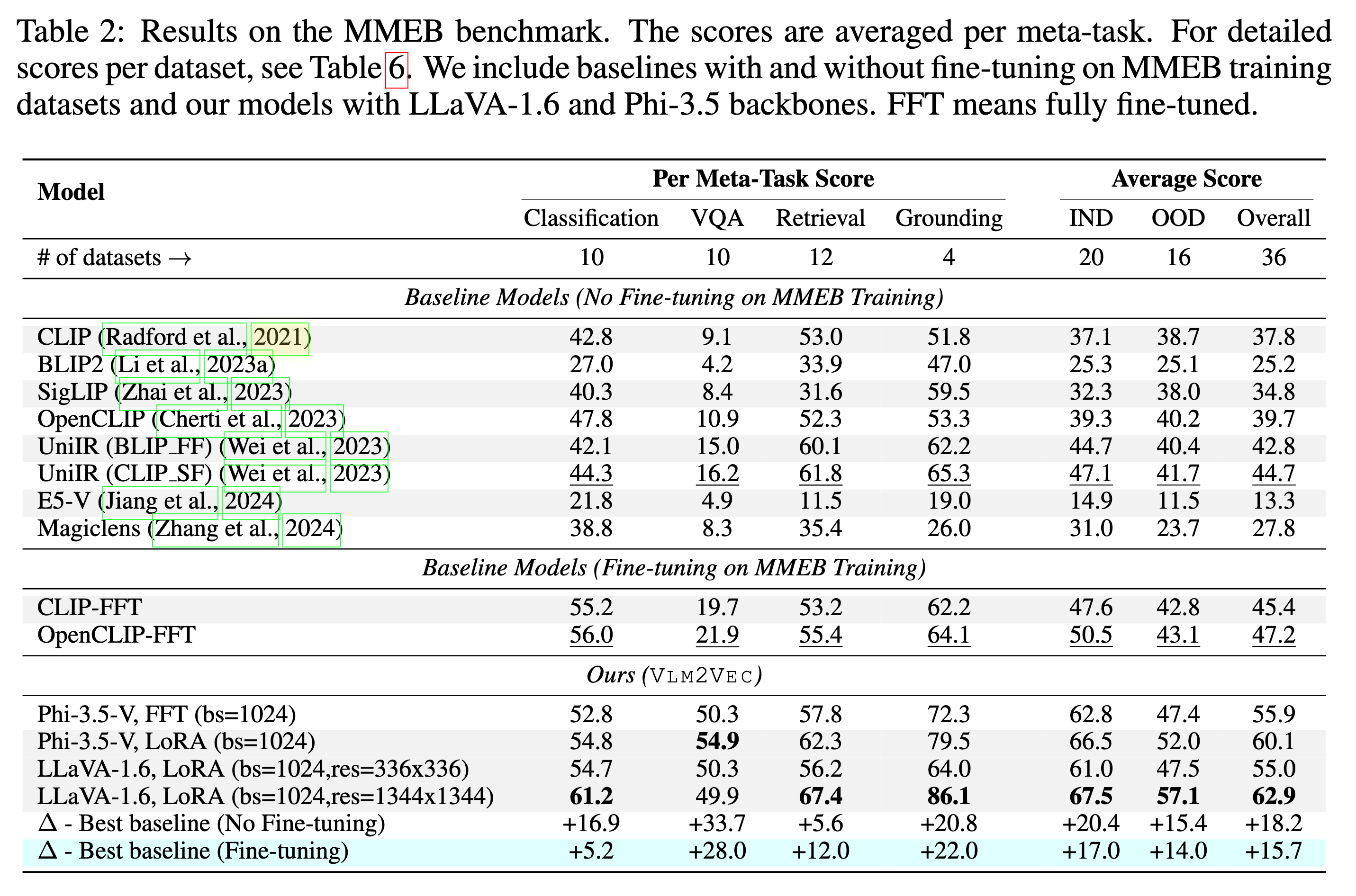
Мы предоставили несколько образцов, включая демонстрационный и код оценки, расположенные в scripts/ каталоге.
Загрузите файл изображения Zip от uggingface
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
Для графических процессоров с небольшой памятью используйте GradCache, чтобы уменьшить использование памяти, то есть настройка небольших значений для --gc_q_chunk_size и --gc_p_chunk_size .
Используйте --lora --lora_r 16 чтобы включить настройку Lora.
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 Загрузите файл изображения Zip от uggingface
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


