VLM2Vec
1.0.0
Este repositorio contiene el código y los datos para VLM2VEC: entrenamiento de modelos en idioma de visión para tareas de incrustación multimodal masivas. En este artículo, nuestro objetivo fue construir un modelo de incrustación multimodal unificado para cualquier tarea.
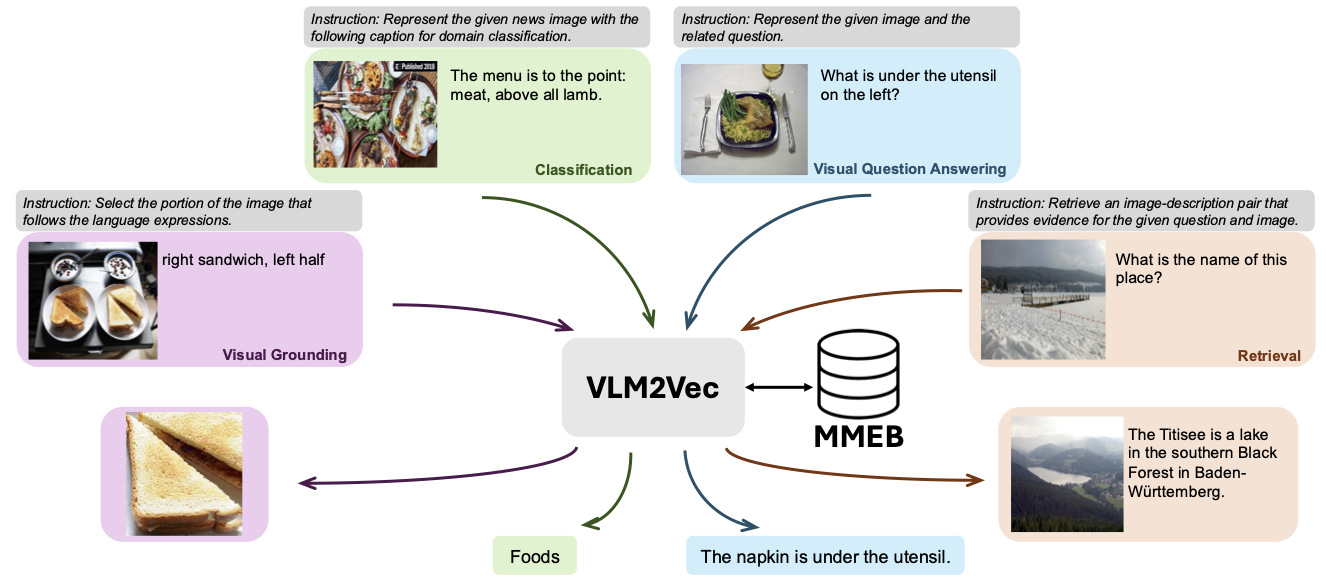
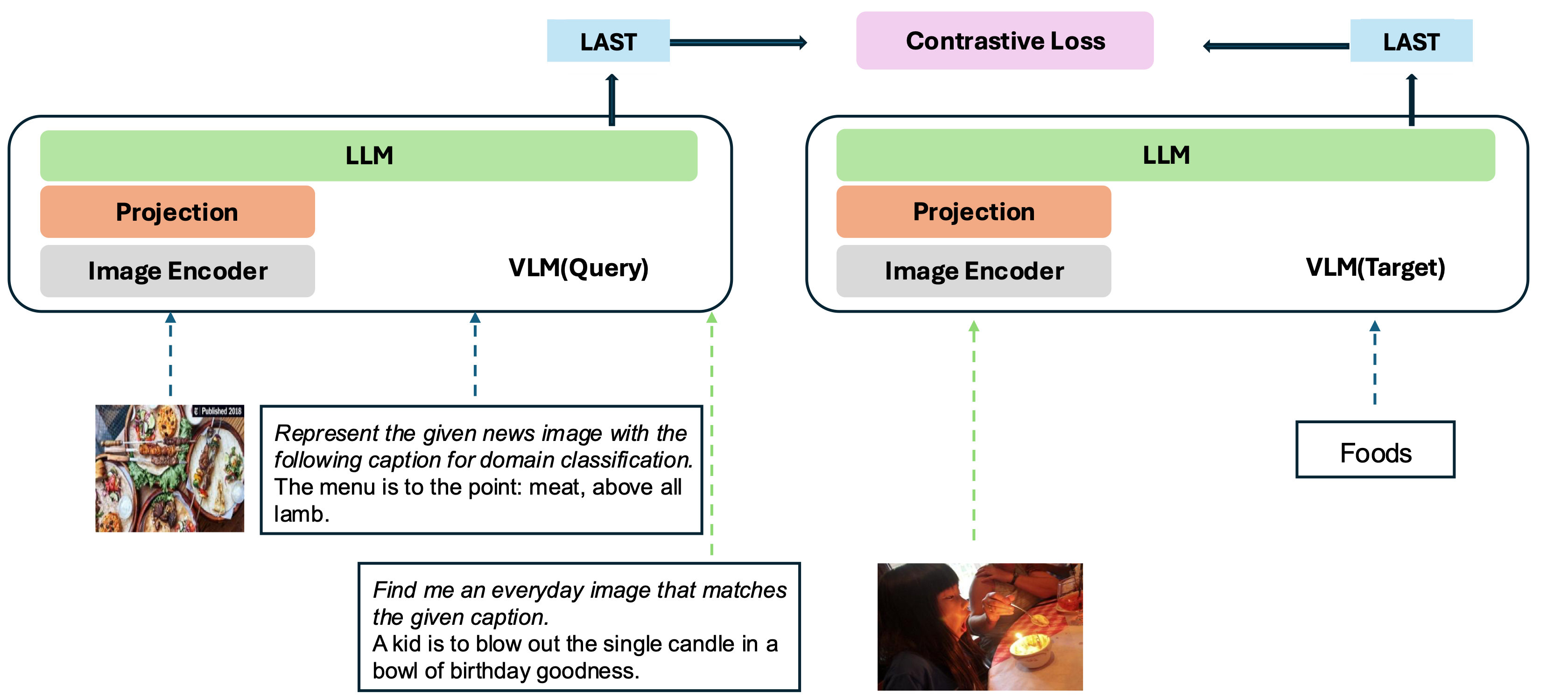
Nuestro modelo se basa en convertir un VLM bien entrenado existente en un modelo de incrustación. La idea básica es tomar el último token al final de la secuencia como la representación de las entradas multimodales. Nuestro marco VLM2VEC es compatible con cualquier VLMS de código abierto SOTA. Al aprovechar diversos datos de capacitación, abarcar una variedad de combinaciones de modalidad, tareas e instrucciones, genera un modelo de incrustación multimodal universal robusto.
Nuestro modelo está siendo entrenado en MMEB-Train (20 tareas) y se evalúa en MMEB-EVAL (20 tareas de IND y 16 tareas OOD).
Nuestro modelo puede superar a las líneas de base existentes por un gran margen.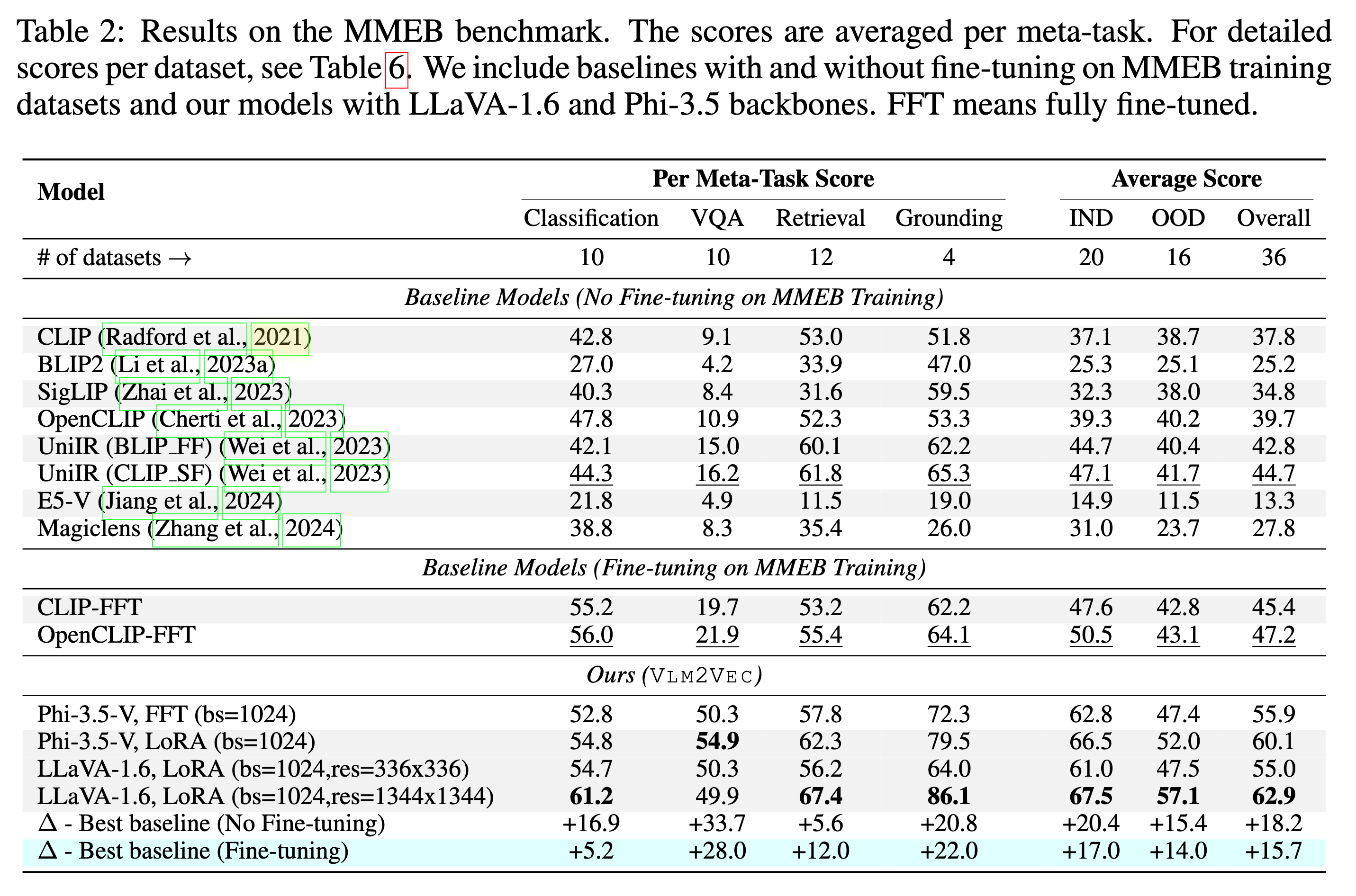
Hemos proporcionado varias muestras, incluido el código de demostración y evaluación, ubicado en los scripts/ directorio.
Descargue el archivo de imagen zip desde Huggingface
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
Para las GPU con memoria pequeña, use GradCache para reducir el uso de la memoria, es decir, configurando valores pequeños en --gc_q_chunk_size y --gc_p_chunk_size .
Use --lora --lora_r 16 para habilitar la sintonización de Lora.
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 Descargue el archivo de imagen zip desde Huggingface
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


