VLM2Vec
1.0.0
このレポは、VLM2VEC:大規模なマルチモーダル埋め込みタスクのためのビジョン言語モデルのトレーニングのコードとデータが含まれています。この論文では、タスクのために統一されたマルチモーダル埋め込みモデルを構築することを目指しました。
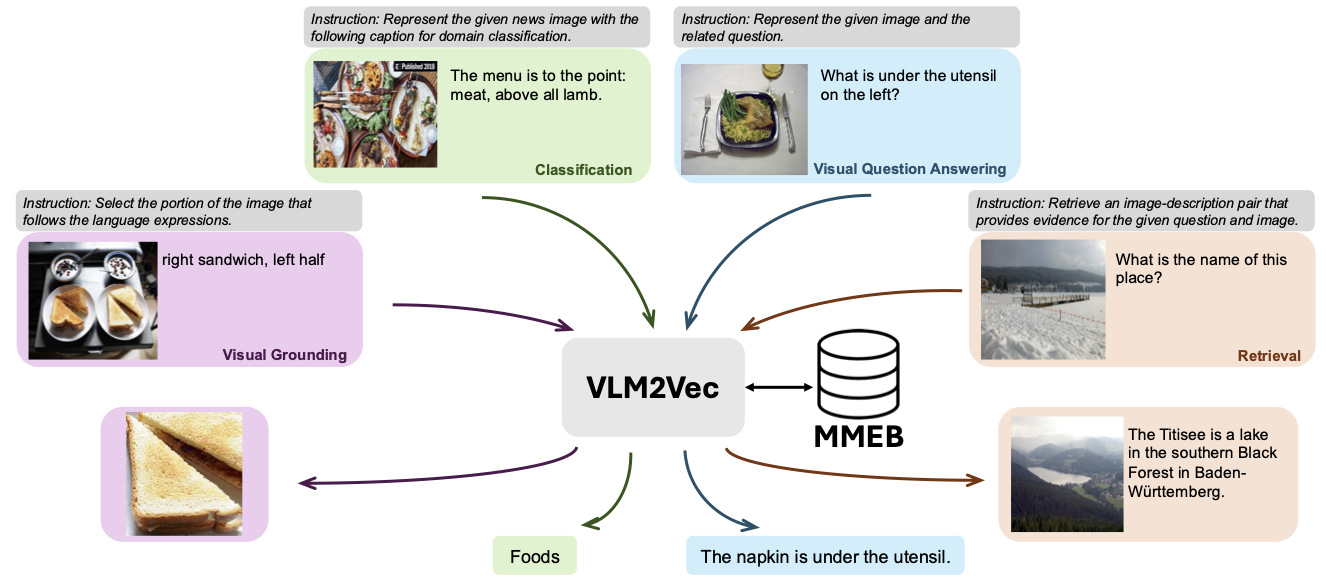
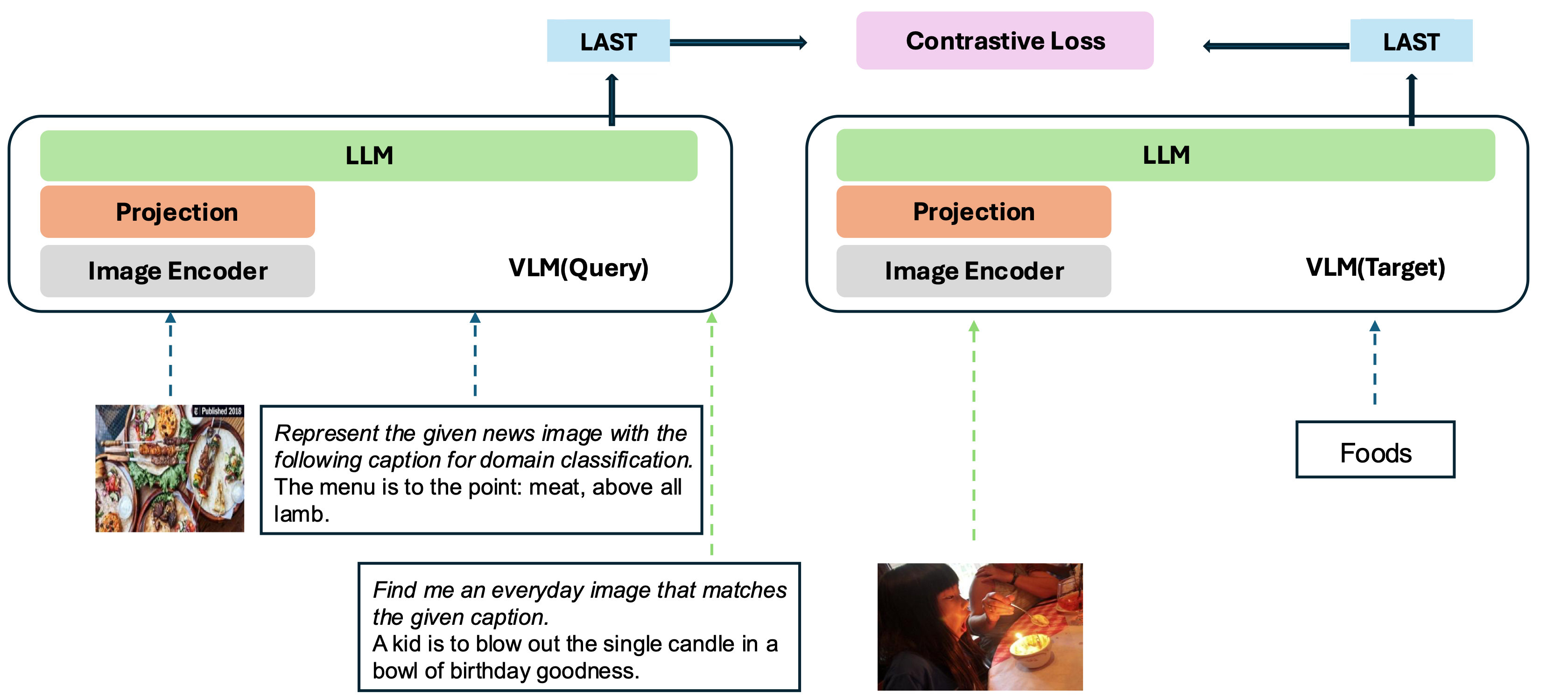
私たちのモデルは、既存のよく訓練されたVLMを埋め込みモデルに変換することに基づいています。基本的なアイデアは、マルチモーダル入力の表現として、シーケンスの最後に最後のトークンを取ることです。当社のVLM2VECフレームワークは、SOTAオープンソースVLMと互換性があります。さまざまなモダリティの組み合わせ、タスク、および命令を抑える多様なトレーニングデータを活用することにより、堅牢なユニバーサルマルチモーダル埋め込みモデルを生成します。
私たちのモデルは、MMEBトレイン(20のタスク)でトレーニングされており、MMEB-Eval(20のINDタスクと16のOODタスク)で評価されています。
私たちのモデルは、既存のベースラインを大きなマージンで上回ることができます。 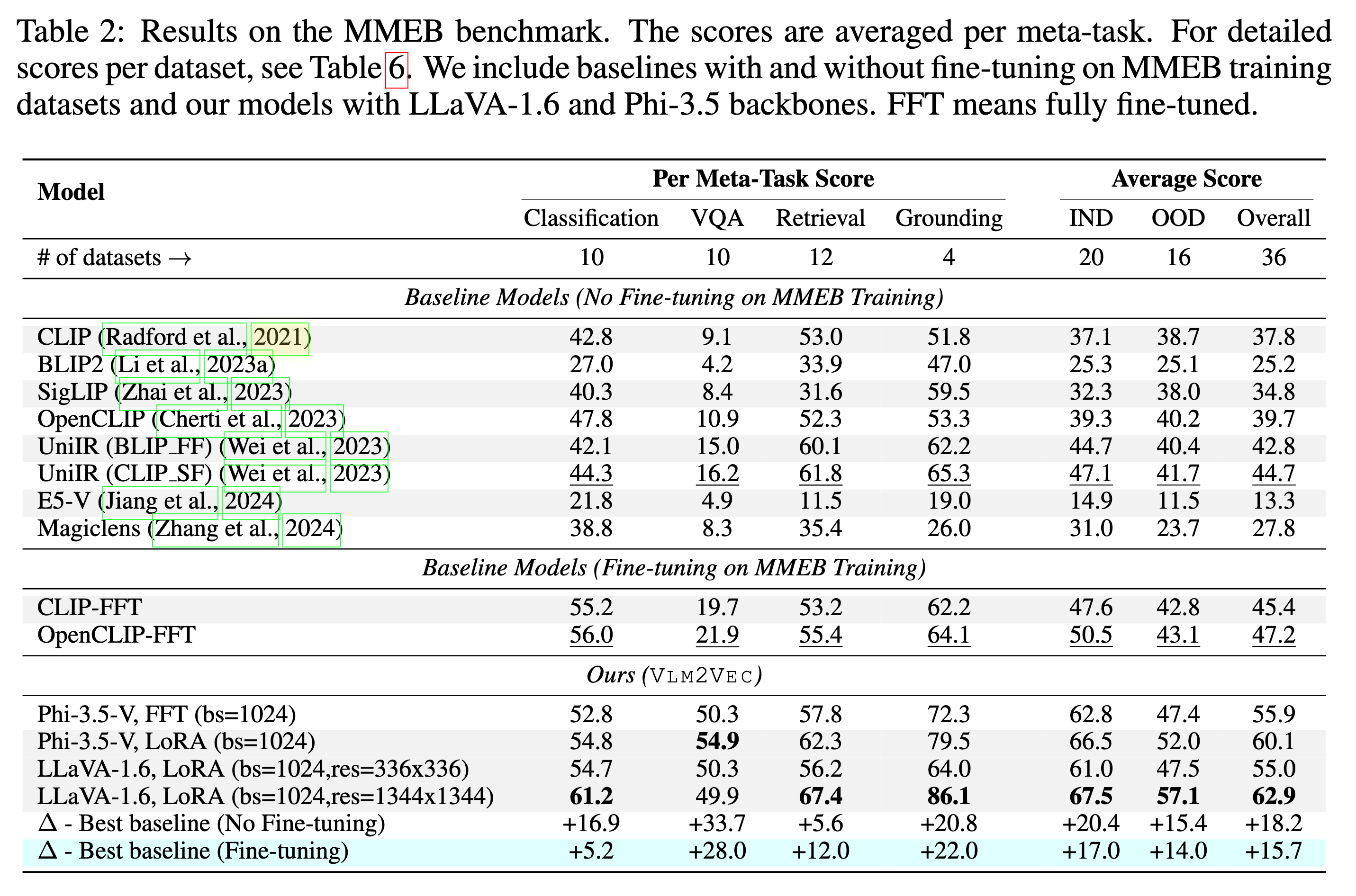
scripts/ディレクトリにあるデモンストレーションと評価コードを含むいくつかのサンプルを提供しました。
Huggingfaceから画像ファイルzipをダウンロードします
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
小さなメモリを持つGPUの場合、GradCacheを使用してメモリの使用量を削減します。つまり、 --gc_q_chunk_sizeおよび--gc_p_chunk_sizeに小さな値を設定します。
--lora --lora_r 16を使用して、ロラチューニングを有効にします。
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 Huggingfaceから画像ファイルzipをダウンロードします
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


