VLM2Vec
1.0.0
Este repositório contém o código e os dados do VLM2VEC: modelos de treinamento em visão de visão para tarefas de incorporação multimodais maciças. Neste artigo, pretendemos construir um modelo de incorporação multimodal unificado para quaisquer tarefas.
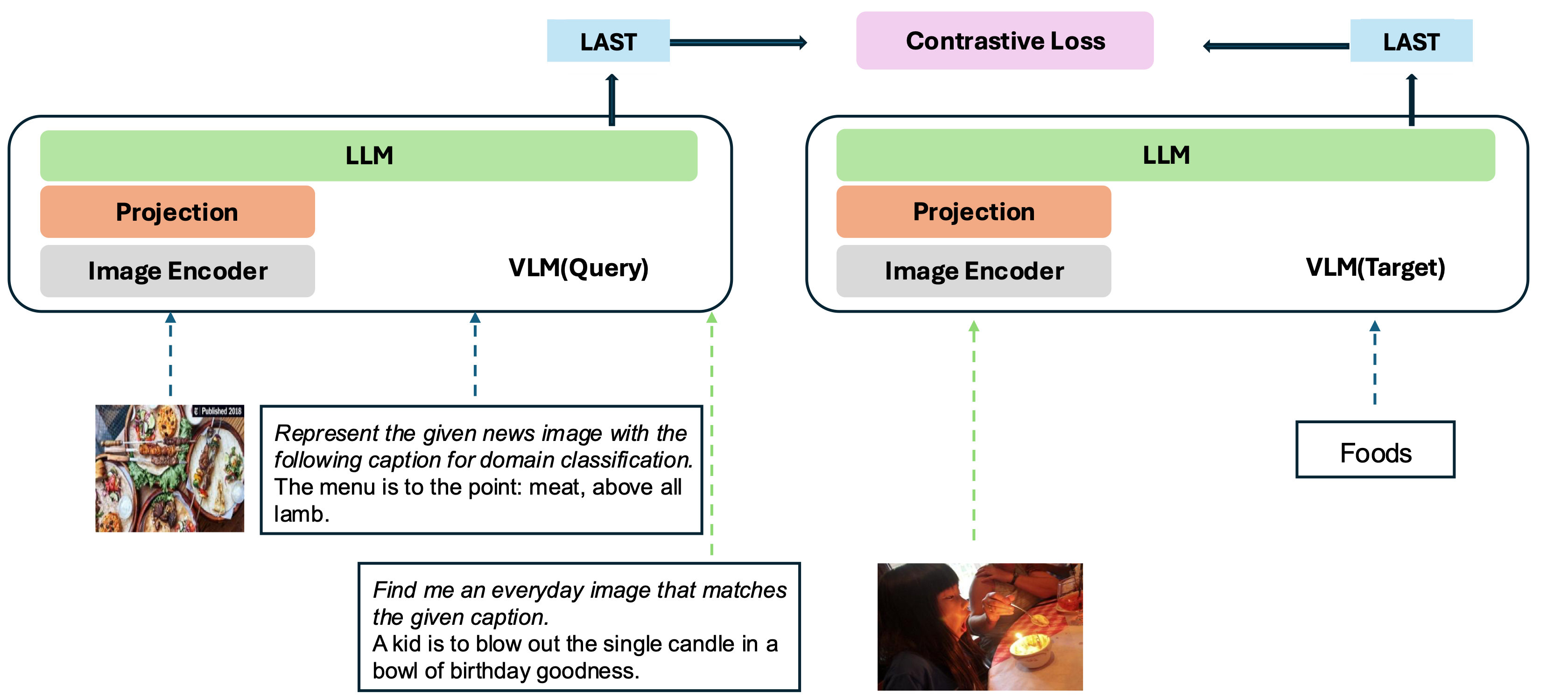
Nosso modelo é baseado na conversão de um VLM bem treinado existente em um modelo de incorporação. A idéia básica é pegar o último token no final da sequência como representação das entradas multimodais. Nossa estrutura VLM2VEC é compatível com qualquer VLMS de código aberto SOTA. Ao aproveitar diversos dados de treinamento - abrangendo uma variedade de combinações, tarefas e instruções de modalidade - gera um modelo robusto de incorporação multimodal universal.
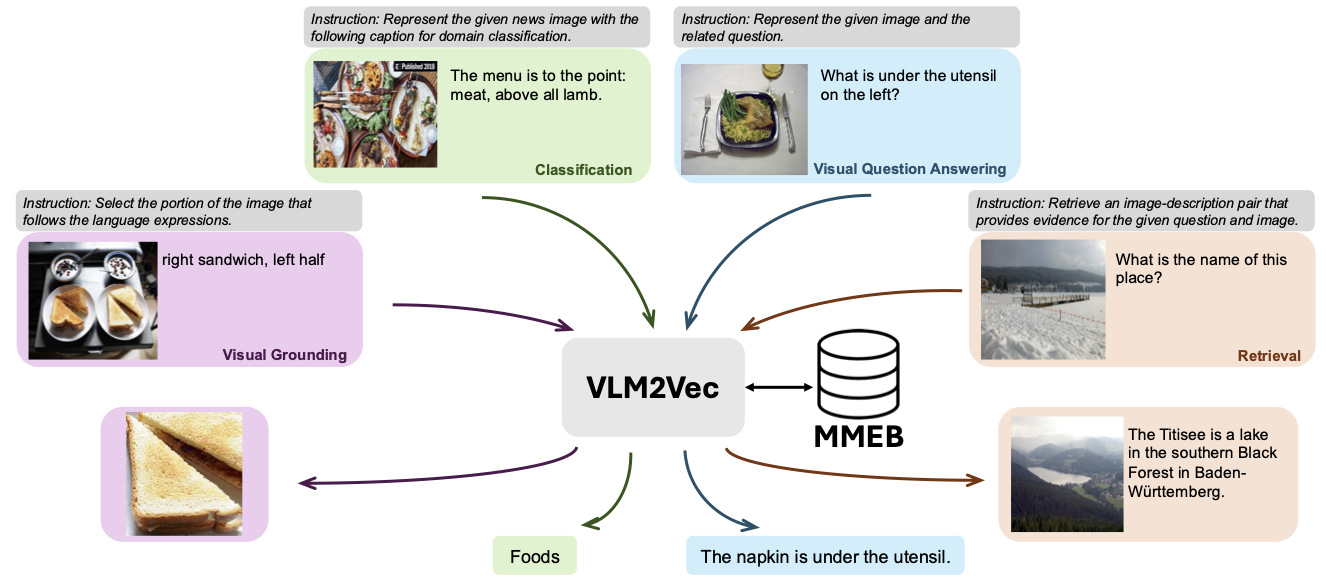
Nosso modelo está sendo treinado em MMEB-train (20 tarefas) e avaliado em MMEB-EVAL (20 tarefas de IND e 16 tarefas de OOD).
Nosso modelo pode superar as linhas de base existentes em uma enorme margem. 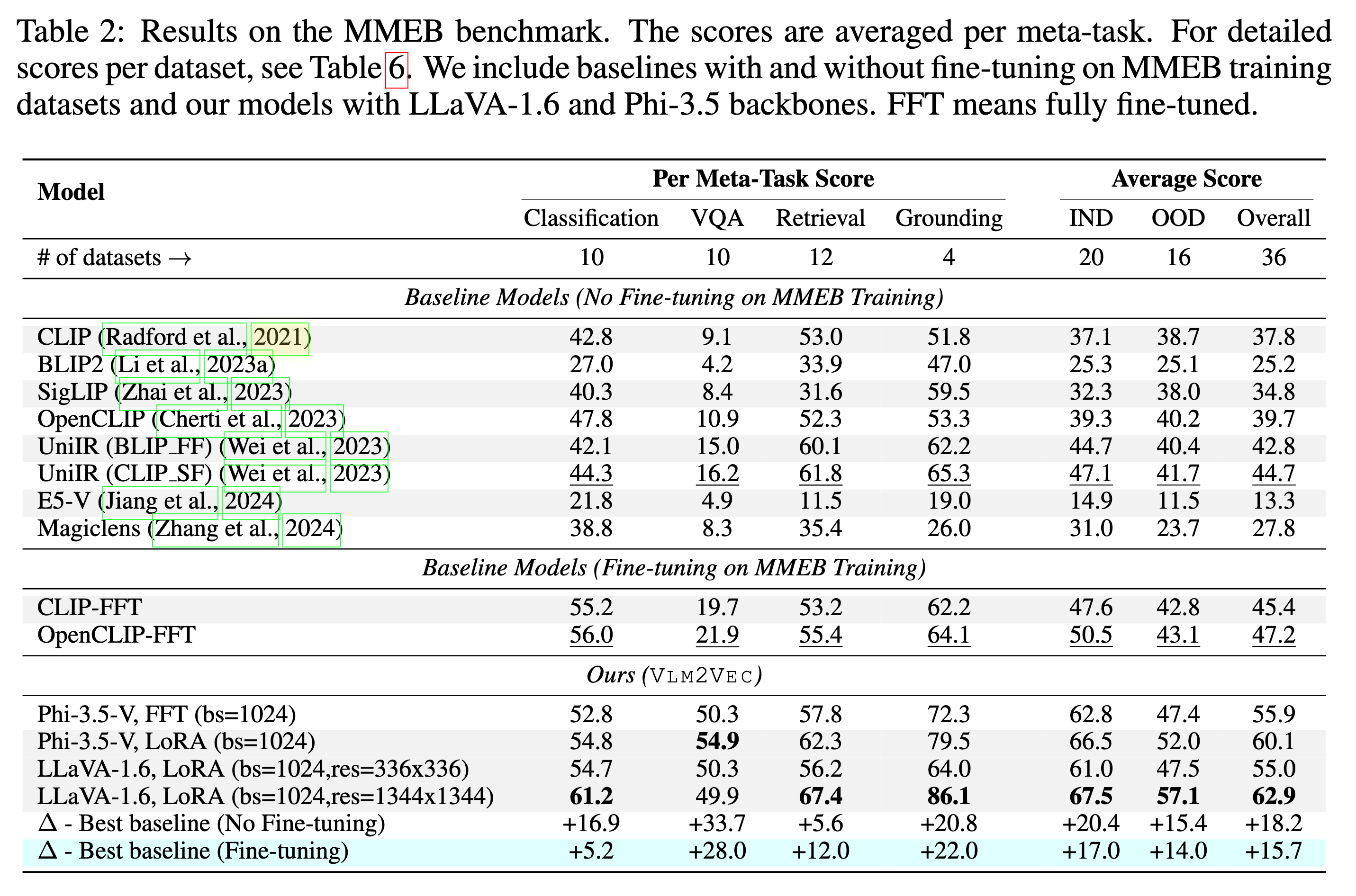
Fornecemos várias amostras, incluindo código de demonstração e avaliação, localizado nos scripts/ diretório.
Baixe o zíper do arquivo de imagem do huggingface
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
Para GPUs com memória pequena, use o gradcache para reduzir o uso da memória, ou seja, definindo pequenos valores como --gc_q_chunk_size e --gc_p_chunk_size .
Use --lora --lora_r 16 para ativar o ajuste do LORA.
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 Baixe o zíper do arquivo de imagem do huggingface
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


