VLM2Vec
1.0.0
يحتوي هذا الريبو على الكود والبيانات لـ VLM2VEC: تدريب نماذج لغة الرؤية لمهام التضمين المتعددة الوسائط الضخمة. في هذه الورقة ، كنا نهدف إلى بناء نموذج موحد متعدد الوسائط لأي مهام.
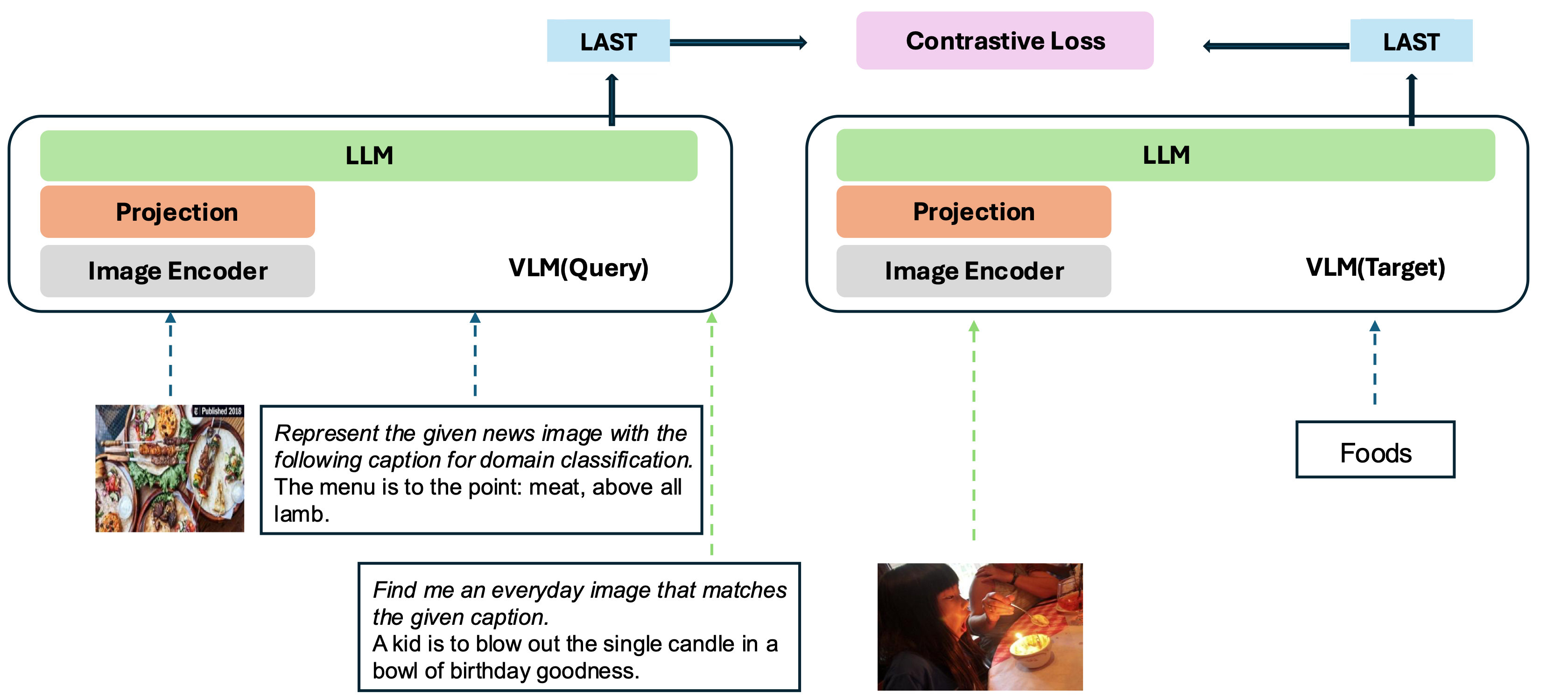
يعتمد نموذجنا على تحويل VLM موجود تدريباً جيداً إلى نموذج التضمين. الفكرة الأساسية هي أخذ الرمز المميز الأخير في نهاية التسلسل كتمثيل للمدخلات متعددة الوسائط. إطار عمل VLM2VEC الخاص بنا متوافق مع أي VLMS مفتوح المصدر SOTA. من خلال الاستفادة من بيانات التدريب المتنوعة - تكوين مجموعة متنوعة من مجموعات الوسائط والمهام والتعليمات - فإنه يولد نموذجًا قويًا متعدد الوسائط.
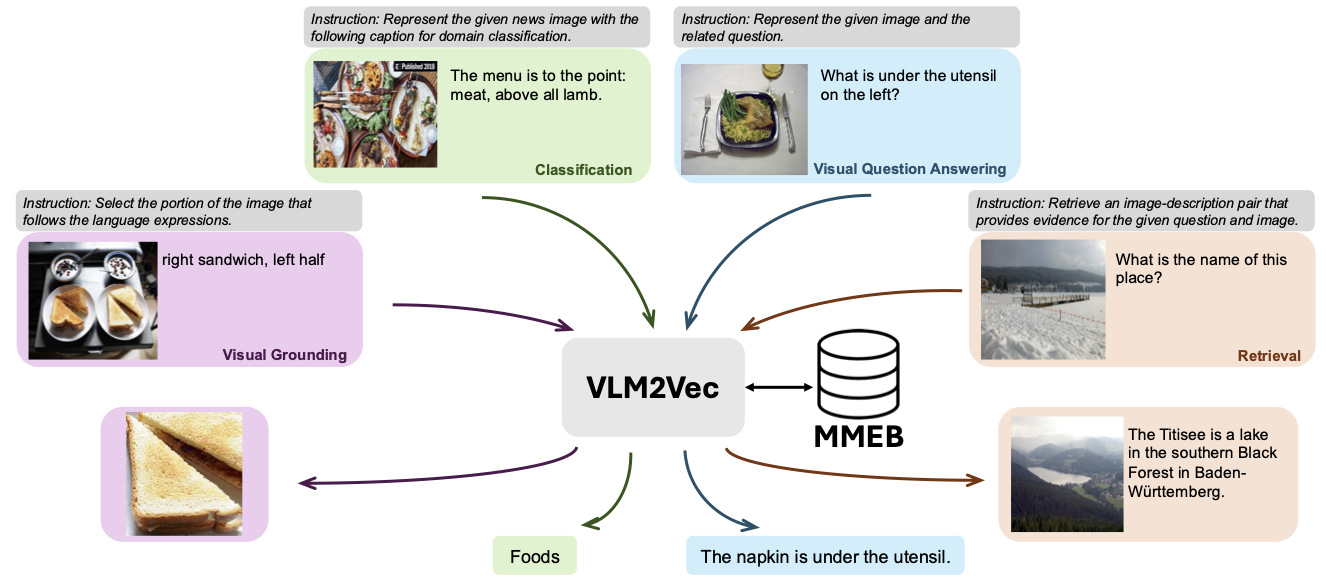
يتم تدريب نموذجنا على MMEB-Train (20 مهمة) ويتم تقييمه على MMEB-eval (20 مهمة IND و 16 مهمة ood).
يمكن أن يتفوق نموذجنا على خطوط الأساس الحالية بهامش ضخم. 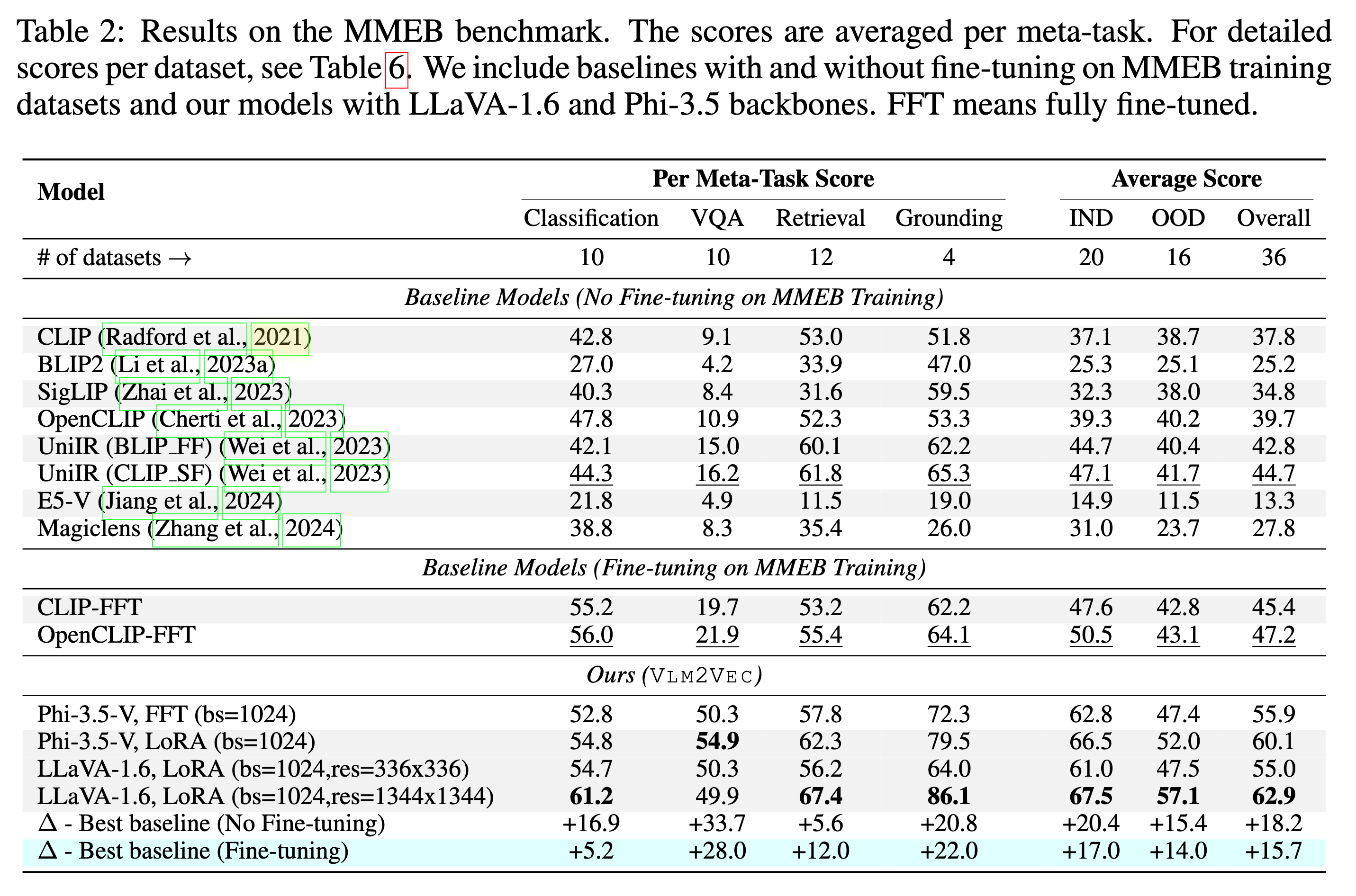
لقد قدمنا العديد من العينات ، بما في ذلك رمز التقييم والتقييم ، الموجود في scripts/ الدليل.
قم بتنزيل zip ملف الصورة من Huggingface
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
بالنسبة إلى وحدات معالجة الرسومات مع ذاكرة صغيرة ، استخدم GradCache لتقليل استخدام الذاكرة ، أي تعيين القيم الصغيرة إلى --gc_q_chunk_size و --gc_p_chunk_size .
استخدم --lora --lora_r 16 لتمكين ضبط Lora.
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 قم بتنزيل zip ملف الصورة من Huggingface
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


