VLM2Vec
1.0.0
Repo ini berisi kode dan data untuk VLM2VEC: melatih model bahasa penglihatan untuk tugas penyematan multimoda besar-besaran. Dalam makalah ini, kami bertujuan untuk membangun model embedding multimoda terpadu untuk setiap tugas.
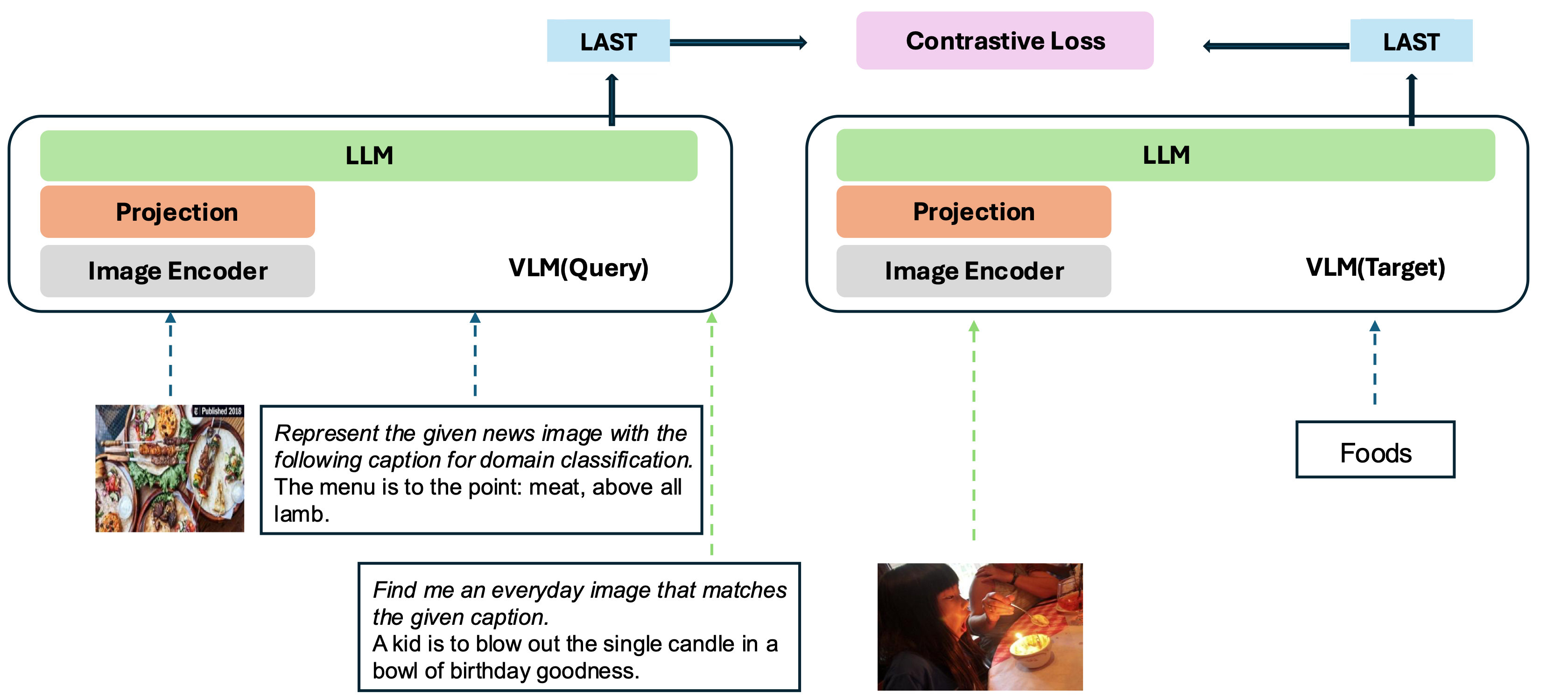
Model kami didasarkan pada mengubah VLM yang terlatih dengan baik menjadi model embedding. Ide dasarnya adalah mengambil token terakhir di akhir urutan sebagai representasi dari input multimodal. Kerangka kerja VLM2VEC kami kompatibel dengan VLMs sumber terbuka SOTA. Dengan memanfaatkan data pelatihan yang beragam - mencakup berbagai kombinasi modalitas, tugas, dan instruksi - ini menghasilkan model embedding multimodal universal yang kuat.
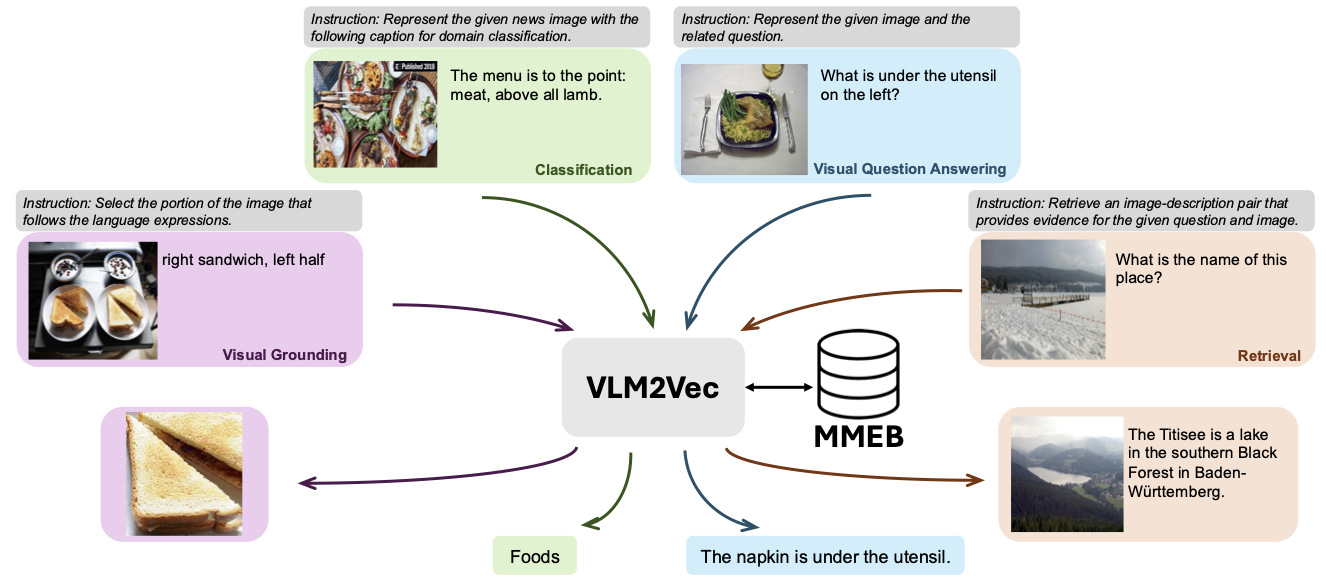
Model kami sedang dilatih pada MMEB-Train (20 tugas) dan dievaluasi pada MMEB-eval (20 tugas ind dan 16 tugas OOD).
Model kami dapat mengungguli garis dasar yang ada dengan margin besar. 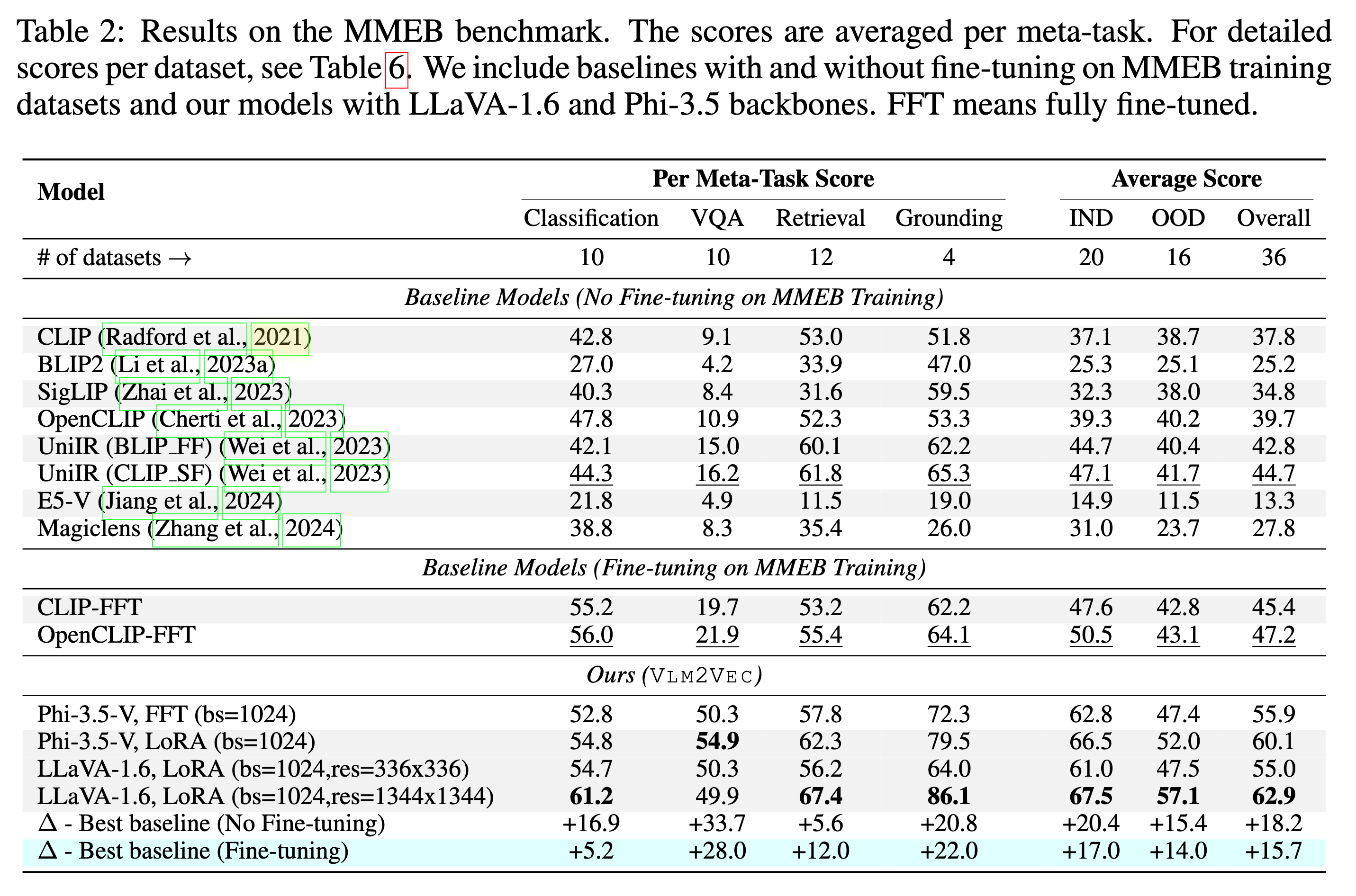
Kami telah menyediakan beberapa sampel, termasuk kode demonstrasi dan evaluasi, yang terletak di scripts/ direktori.
Unduh gambar file gambar dari huggingface
git lfs install
git clone https://huggingface.co/datasets/TIGER-Lab/MMEB-train
cd MMEB-train
python unzip_file.py
cd ../
Untuk GPU dengan memori kecil, gunakan GradCache untuk mengurangi penggunaan memori, yaitu menetapkan nilai kecil ke --gc_q_chunk_size dan --gc_p_chunk_size .
Gunakan --lora --lora_r 16 untuk mengaktifkan tuning lora.
torchrun --nproc_per_node=2 --master_port=22447 --max_restarts=0 train.py
--model_name microsoft/Phi-3.5-vision-instruct --bf16 --pooling last
--dataset_name TIGER-Lab/MMEB-train
--subset_name ImageNet_1K N24News HatefulMemes InfographicsVQA ChartQA Visual7W VisDial CIRR NIGHTS WebQA MSCOCO
--num_sample_per_subset 50000
--image_dir MMEB-train
--max_len 256 --num_crops 4 --output_dir $OUTPUT_DIR --logging_steps 1
--lr_scheduler_type linear --learning_rate 2e-5 --max_steps 2000
--warmup_steps 200 --save_steps 1000 --normalize True
--temperature 0.02 --per_device_train_batch_size 8
--grad_cache True --gc_q_chunk_size 2 --gc_p_chunk_size 2 Unduh gambar file gambar dari huggingface
wget https://huggingface.co/datasets/TIGER-Lab/MMEB-eval/resolve/main/images.zip
unzip images.zip -d eval_images/python eval.py --model_name TIGER-Lab/VLM2Vec-Full
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/python eval.py --lora --model_name microsoft/Phi-3.5-vision-instruct --checkpoint_path TIGER-Lab/VLM2Vec-LoRA
--encode_output_path outputs/
--num_crops 4 --max_len 256
--pooling last --normalize True
--dataset_name TIGER-Lab/MMEB-eval
--subset_name N24News CIFAR-100 HatefulMemes VOC2007 SUN397 ImageNet-A ImageNet-R ObjectNet Country211
--dataset_split test --per_device_eval_batch_size 16
--image_dir eval_images/ @article{jiang2024vlm2vec,
title={VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks},
author={Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu},
journal={arXiv preprint arXiv:2410.05160},
year={2024}
}


