TUPE
1.0.0
在语言预训练中重新思考文章的位置编码的实施。
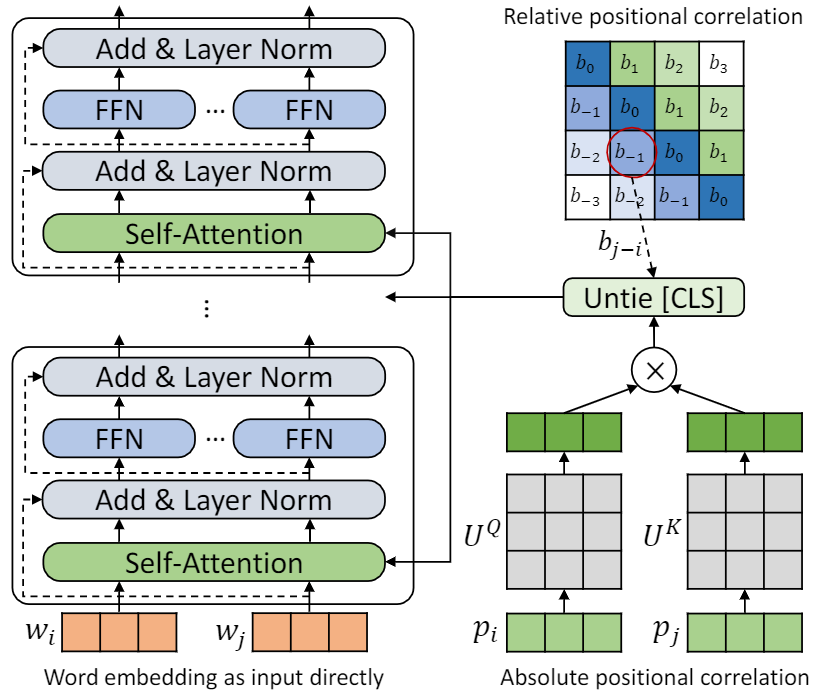
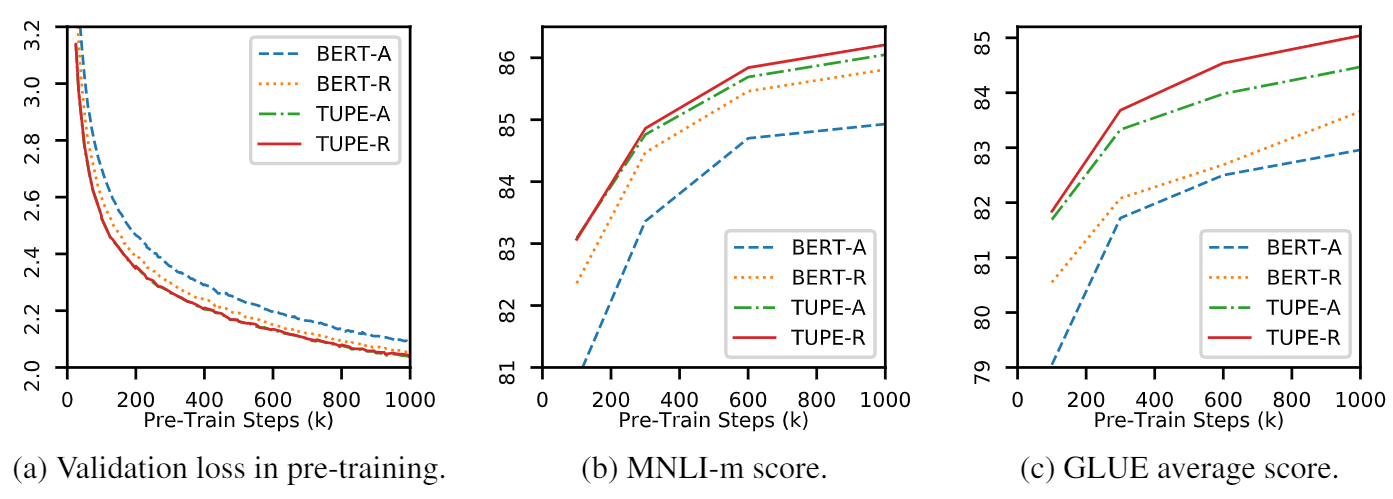
此存储库是要演示TUPE(带有未接触位置编码的变压器)。算法细节可以在我们的论文中找到。 Tupe可以通过较大的边距在胶水基准上胜过其他基准。特别是,它可以比基线获得更高的分数,而仅使用30%的培训预计算成本。
由于计算资源有限,我们使用最广泛使用的预训练模型BERT-BASE进行验证。但是,请注意,我们的方法可用于较大(和更好的)基于变压器的模型,例如Roberta,Electra和Unilm,并进一步改善它们。此外,由于修改非常简单易用,因此您可以轻松地在模型中应用Tupe。
我们的实施是基于Fairseq的,有几个更改:
fairseq/modules/transformer_sentence_encoder.py和fairseq/modules/multihead_attention.py用于未接触的位置编码。warmup-ratio其他一些小改动以支持max-epoch ,而不是为不同的任务设置不同的total-num-update和warmup-updates 。 更多详细信息请参阅Fairseq。简要地,
--cuda_ext安装选项,用于混合精确培训从源安装
要从源安装Tupe并在本地开发:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . 预处理依赖于MosesDecoder,您可以运行以下脚本将其拉动。
cd TUPE
git submodule update --init请参阅preprocess/pretrain/process.sh的步骤。
请参阅preprocess/glue/process.sh的步骤。
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
以上设置为16 V100 GPU,批次大小为256( n_gpu * MAX_SENTENCES * UPDATE_FREQ )。您可能需要根据环境更改MAX_SENTENCES或UPDATE_FREQ 。为了禁用相对位置,您可以删除--rel-pos 。
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos为了加快Finetune的速度,我们将MNLI,QNLI和QQP的N_EPOCH=5设置为5,而N_EPOCH=10对于其他。对于MNLI, N_CLASSES=3和其他设置--valid-subset valid,valid1用于评估mnli-m/-mm。 STS-B是一个回归任务,因此我们将N_CLASSES=1设置,并具有其他设置--regression-target and METRIC=pearson 。对于可乐,我们设置了METRIC=mcc 。
从{2e-5, 3e-5, 4e-5, 5e-5}搜索LR ,每个LR将由5种不同的种子运行,并且由于LR ,我们使用它们的中位数。最佳LR的结果将使用。
注意:如果您使用的预处理模型--rel-pos ,则应在Finetune中设置--rel-pos ,否则您应该将其删除。
我们还发布了Tupe-R(带有--rel-pos )的检查点,以供重复可重复。
您可以引用我们的论文
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


