TUPE
1.0.0
언어 사전 훈련에서 위치 인코딩을 다시 생각하는 용지 구현.
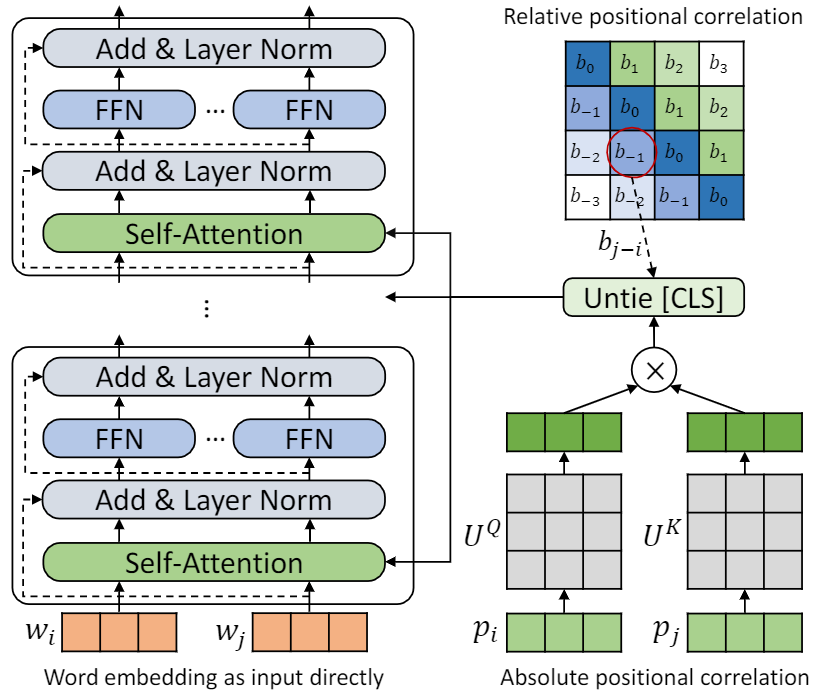
이 repo는 Tupe를 보여주기위한 것입니다. 알고리즘 세부 사항은 본 논문에서 찾을 수 있습니다. Tupe는 접착제 벤치 마크의 다른 기준선보다 큰 마진을 능가 할 수 있습니다. 특히, 사전 훈련 계산 비용 만 사용하면서 기준선보다 높은 점수를 얻을 수 있습니다.
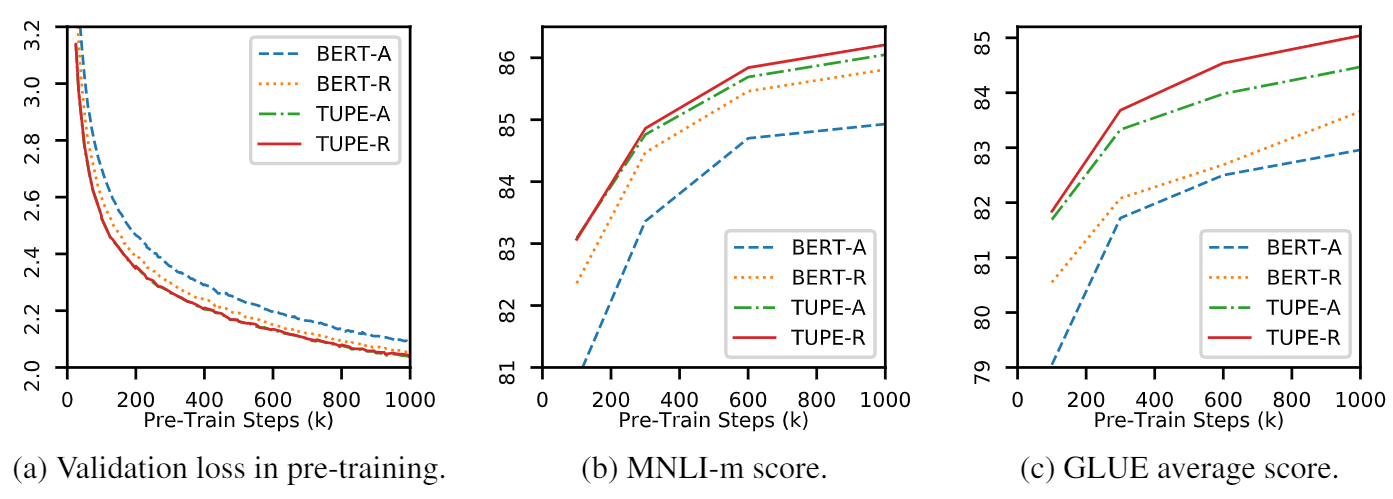
제한된 계산 자원으로 인해 가장 널리 사용되는 사전 훈련 모델 인 Bert-Base를 검증합니다. 그러나 우리의 방법은 Roberta, Electra 및 Unilm과 같은 더 큰 (그리고 더 나은) 변압기 기반 모델에 사용될 수 있으며 더 개선 할 수 있습니다. 게다가, 수정은 간단하고 쉽기 때문에 모델에서 Tupe를 쉽게 적용 할 수 있습니다.
우리의 구현은 FairSeQ를 기반으로하며 몇 가지 변경 사항이 있습니다.
fairseq/modules/transformer_sentence_encoder.py 및 fairseq/modules/multihead_attention.py 업데이트.total-num-update 및 warmup-updates 설정하는 대신 Finetune에서 warmup-ratio 사용하여 max-epoch 지원하기위한 다른 사소한 변경 사항. 자세한 내용은 FairSeQ를 참조하십시오. 간단히,
--cuda_ext 설치 옵션이 포함 된 NVIDIA의 APEX 라이브러리소스에서 설치
소스에서 Tupe를 설치하고 로컬로 개발하려면 :
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . 사전 처리는 Mosesdecoder에 의존하여 다음 스크립트를 실행하여 가져올 수 있습니다.
cd TUPE
git submodule update --init preprocess/pretrain/process.sh 의 단계를 참조하십시오.
preprocess/glue/process.sh 의 단계를 참조하십시오.
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
위의 설정은 16 V100 GPUS 용이며 배치 크기는 256입니다 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ). 환경에 따라 MAX_SENTENCES 또는 UPDATE_FREQ 변경해야 할 수도 있습니다. 상대 위치를 비활성화하려면 --rel-pos 제거 할 수 있습니다.
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos Finetune 속도를 높이기 위해 MNLI, QNLI 및 QQP의 경우 N_EPOCH=5 , 다른 경우 N_EPOCH=10 설정합니다. Mnli의 경우 N_CLASSES=3 및 추가 설정 --valid-subset valid,valid1 MNLI-M/-MM을 함께 평가하는 데 사용됩니다. STS-B METRIC=pearson 회귀 작업이므로 N_CLASSES=1 --regression-target 로 설정합니다. Cola의 경우 METRIC=mcc 설정합니다.
LR {2e-5, 3e-5, 4e-5, 5e-5} 에서 검색되며 각 LR 5 개의 다른 시드로 실행되며 해당 LR 의 결과로 중앙값을 사용합니다. 최고의 LR 의 결과가 사용됩니다.
참고 : 프리 트레인 모델을 사용한 경우 --rel-pos 사용하는 경우 --rel-pos Finetune에서 설정해야합니다. 그렇지 않으면 제거해야합니다.
또한 재현성을 위해 Tupe-R ( --rel-pos )의 체크 포인트를 해제합니다.
당신은 우리 논문을 인용 할 수 있습니다
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


