TUPE
1.0.0
Mise en œuvre de l'article repensant le codage positionnel dans la pré-formation du langage.
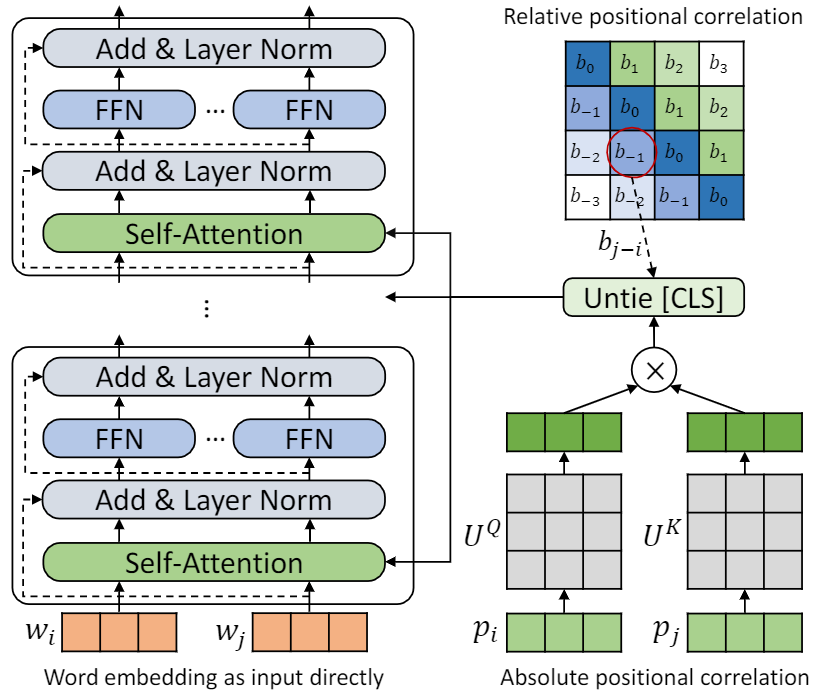
Ce repo est de démontrer le tupe (transformateur avec un codage positionnel délié). Les détails de l'algorithme ont pu être trouvés dans notre article. Le tube peut surpasser les autres lignes de base sur la référence de colle par une grande marge. En particulier, il peut atteindre un score plus élevé que les lignes de base tout en n'utilisant que 30% de coûts de calcul pré-entraînement.
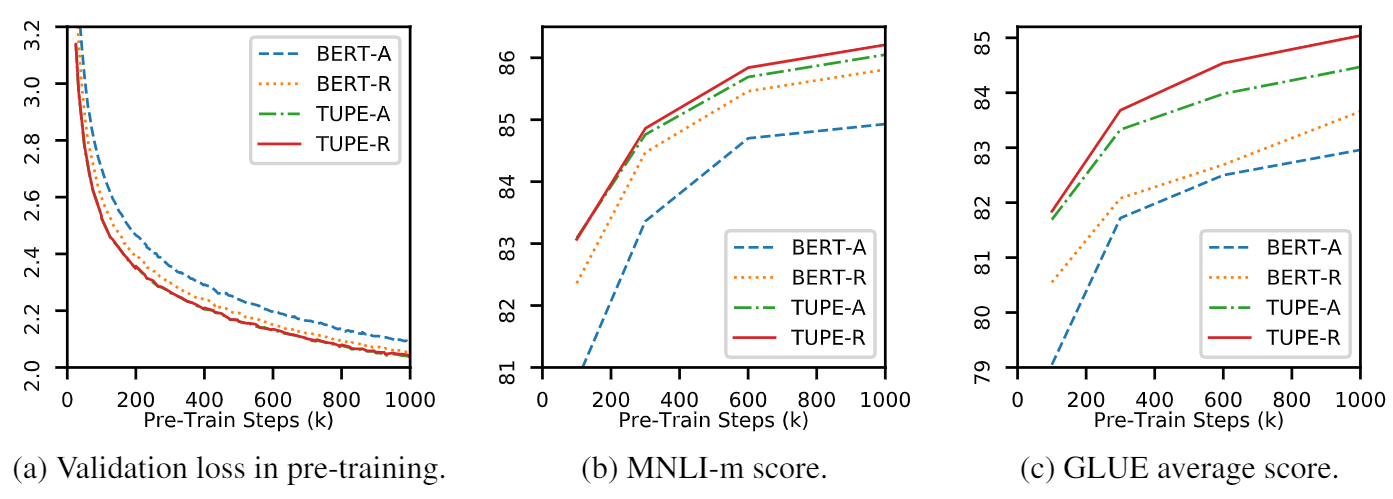
En raison des ressources de calcul limitées, nous utilisons le modèle de pré-formation pré-entraînement le plus largement utilisé, Bert-Base, pour la vérification. Cependant, veuillez noter que notre méthode pourrait être utilisée pour des modèles basés sur des transformateurs plus grands (et meilleurs), comme Roberta, Electra et Unilm, et les améliorer davantage. En outre, comme la modification est simple et facile, vous pouvez facilement appliquer du Tupe dans vos modèles.
Notre implémentation est basée sur Fairseq, avec plusieurs changements:
fairseq/modules/transformer_sentence_encoder.py et fairseq/modules/multihead_attention.py pour le codage positionnel desserré.max-epoch avec warmup-ratio à Finetune, au lieu de définir différentes total-num-update et warmup-updates pour différentes tâches. Plus de détails Voir Fairseq. Brièvement,
--cuda_ext , pour une formation de précision mixteInstallation à partir de la source
Pour installer Tupe à partir de la source et développer localement:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . Le prétraitement repose sur Mosesdecoder, vous pouvez exécuter le script suivant pour le retirer.
cd TUPE
git submodule update --init Reportez-vous aux étapes du preprocess/pretrain/process.sh .
Reportez-vous aux étapes du preprocess/glue/process.sh .
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
Le paramètre ci-dessus est pour 16 GPU V100, et la taille du lot est de 256 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ). Vous devrez peut-être modifier MAX_SENTENCES ou UPDATE_FREQ en fonction de votre environnement. Pour désactiver la position relative, vous pouvez supprimer --rel-pos .
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos Pour accélérer FineTune, nous définissons N_EPOCH=5 pour Mnli, Qnli et QQP et N_EPOCH=10 pour d'autres. Pour MNLI, N_CLASSES=3 et un paramètre supplémentaire --valid-subset valid,valid1 est utilisé pour évaluer MNLI-M / -MM ensemble. STS-B est une tâche de régression, nous définissons donc N_CLASSES=1 , avec des paramètres supplémentaires --regression-target et METRIC=pearson . Pour COLA, nous définissons METRIC=mcc .
LR est recherché à partir de {2e-5, 3e-5, 4e-5, 5e-5} , chaque LR sera exécutée par 5 graines différentes, et nous en utilisons la médiane à la suite de ce LR . Le résultat du meilleur LR sera utilisé.
Remarque : Si votre modèle de pré-formation utilisé --rel-pos , vous devez définir --rel-pos dans le Finetune, sinon vous devriez le supprimer.
Nous libérons également le point de contrôle de Tupe-R (avec --rel-pos ), pour la reproductibilité.
Vous pouvez citer notre papier par
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


