TUPE
1.0.0
Implementasi untuk pemikiran ulang kertas pengkodean posisi dalam pra-pelatihan bahasa.
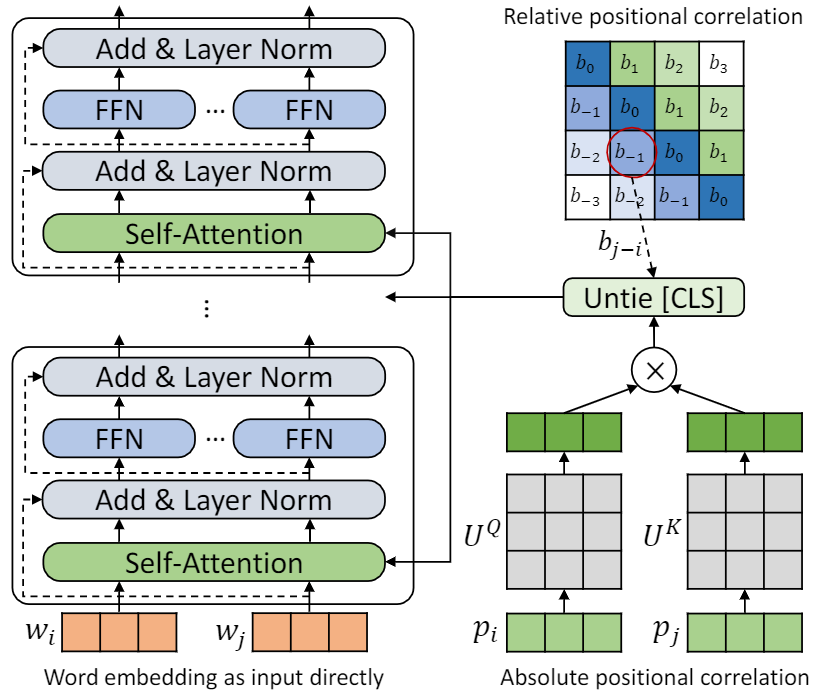
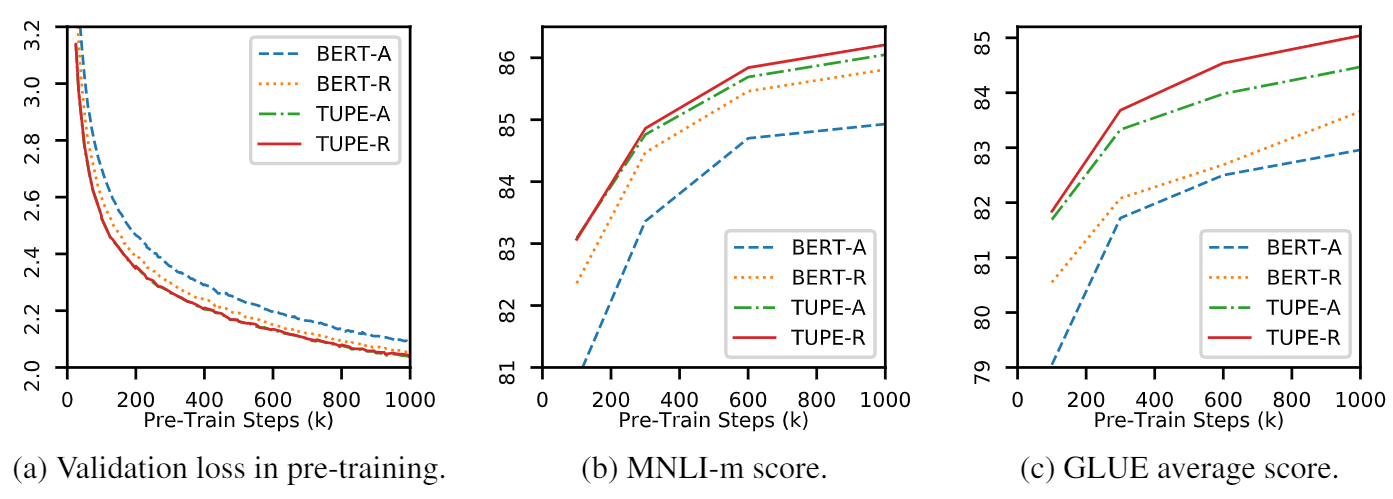
Repo ini adalah untuk menunjukkan tupe (transformator dengan pengkodean posisi yang tidak diikat). Detail algoritma dapat ditemukan di koran kami. Tupe dapat mengungguli baseline lain pada tolok ukur lem dengan margin besar. Secara khusus, ia dapat mencapai skor yang lebih tinggi daripada baseline sementara hanya menggunakan 30% biaya komputasi pra-pelatihan.
Karena sumber daya komputasi yang terbatas, kami menggunakan model pra-pelatihan yang paling banyak digunakan, BERT-BASE, untuk verifikasi. Namun, harap dicatat bahwa metode kami dapat digunakan untuk model berbasis transformator yang lebih besar (dan lebih baik), seperti Roberta, Electra dan Unilm, dan selanjutnya memperbaikinya. Selain itu, karena modifikasi sederhana dan mudah, Anda dapat dengan mudah menerapkan Tupe pada model Anda.
Implementasi kami didasarkan pada Fairseq, dengan beberapa perubahan:
fairseq/modules/transformer_sentence_encoder.py dan fairseq/modules/multihead_attention.py untuk pengkodean posisi yang tidak diikat.max-epoch dengan warmup-ratio di Finetune, alih-alih mengatur total-num-update dan warmup-updates untuk tugas yang berbeda. Rincian lebih lanjut lihat Fairseq. Secara singkat,
--cuda_ext , untuk pelatihan presisi campuranMenginstal dari sumber
Untuk menginstal Tupe dari sumber dan kembangkan secara lokal:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . Pra-pemrosesan bergantung pada MosesDecoder, Anda dapat menjalankan skrip berikut untuk menariknya.
cd TUPE
git submodule update --init Lihat langkah -langkah dalam preprocess/pretrain/process.sh .
Lihat langkah -langkah dalam preprocess/glue/process.sh .
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
Pengaturan di atas adalah untuk 16 V100 GPU, dan ukuran batch adalah 256 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ). Anda mungkin perlu mengubah MAX_SENTENCES atau UPDATE_FREQ sesuai dengan lingkungan Anda. Untuk menonaktifkan posisi relatif, Anda dapat menghapus --rel-pos .
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos Untuk mempercepat finetune, kami mengatur N_EPOCH=5 untuk mnli, qnli dan qqp, dan N_EPOCH=10 untuk orang lain. Untuk mnli, N_CLASSES=3 dan pengaturan tambahan --valid-subset valid,valid1 digunakan untuk mengevaluasi mnli-m/-mm bersama-sama. STS-B adalah tugas regresi, jadi kami mengatur N_CLASSES=1 , dengan pengaturan tambahan --regression-target dan METRIC=pearson . Untuk cola, kami mengatur METRIC=mcc .
LR dicari dari {2e-5, 3e-5, 4e-5, 5e-5} , masing-masing LR akan dijalankan oleh 5 biji yang berbeda, dan kami menggunakan median mereka sebagai hasil dari LR itu. Hasil LR terbaik akan digunakan.
CATATAN : Jika model pretraining Anda digunakan --rel-pos , Anda harus mengatur --rel-pos di finetune, jika tidak Anda harus menghapusnya.
Kami juga merilis pos pemeriksaan Tupe-R (dengan --rel-pos ), untuk reproduktifitas.
Anda dapat mengutip kertas kami
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


