TUPE
1.0.0
Реализация для бумаги переосмысливает позиционное кодирование в языковом предварительном тренировке.
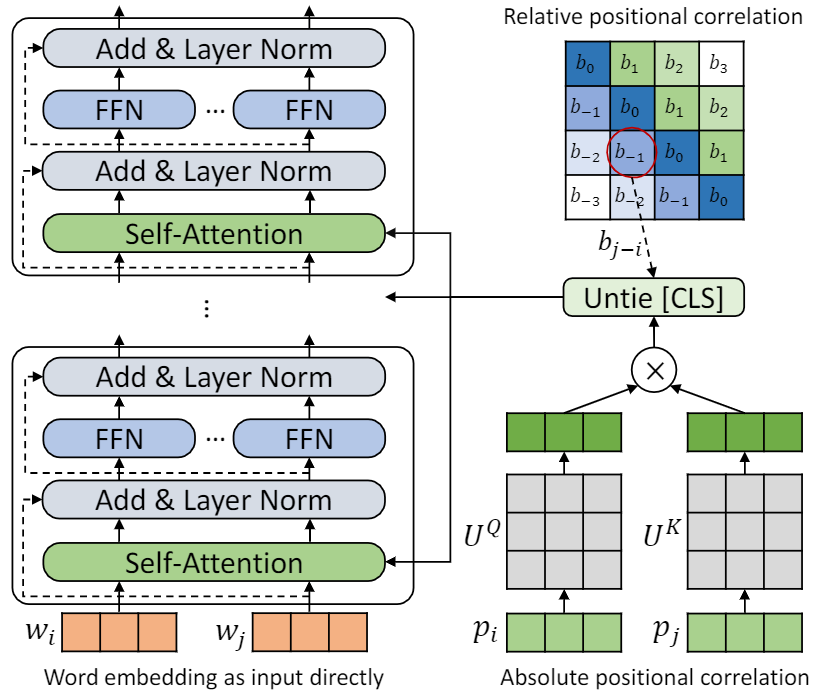
Это репо является демонстрацией TUPE (трансформатор с Untied Popicening Encoding). Детали алгоритма можно найти в нашей статье. Tupe может превзойти другие базовые показатели на клейке с большим отрывом. В частности, он может достичь более высокого балла, чем базовые линии, используя только 30% предварительных вычислительных затрат.
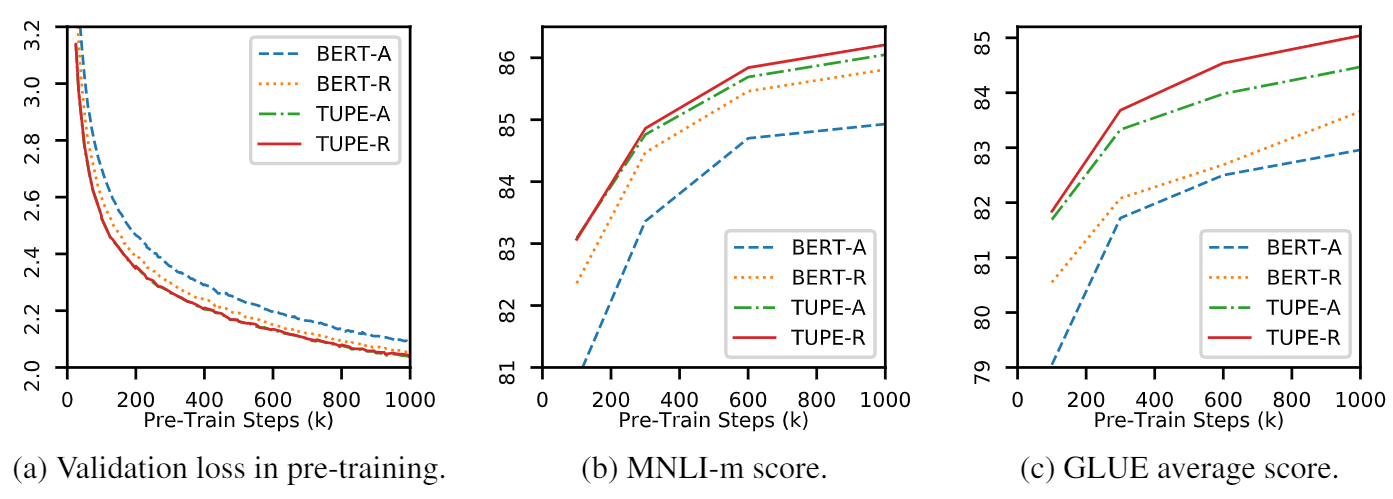
Из-за ограниченных вычислительных ресурсов мы используем наиболее широко используемую модель предварительного обучения, BERT-BASE, для проверки. Тем не менее, обратите внимание, что наш метод может быть использован для более крупных (и лучших) моделей на основе трансформаторов, таких как Roberta, Electra и Unilm, и для их улучшения. Кроме того, поскольку модификация проста и простой, вы можете легко применить Tupe в своих моделях.
Наша реализация основана на Fairseq, с несколькими изменениями:
fairseq/modules/transformer_sentence_encoder.py и fairseq/modules/multihead_attention.py для Untied Plociation Encoding.max-epoch с помощью warmup-ratio в Finetune, вместо того, чтобы устанавливать различные total-num-update и warmup-updates для различных задач. Подробнее см. Fairseq. Вкратце,
--cuda_ext для смешанной точной обученияУстановка из источника
Чтобы установить TUPE из источника и развиваться локально:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . Предварительная обработка полагается на Mosesdecoder, вы можете запустить следующий сценарий, чтобы потянуть его.
cd TUPE
git submodule update --init Обратитесь к шагам в preprocess/pretrain/process.sh .
Обратитесь к шагам в preprocess/glue/process.sh .
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
Приведенная выше настройка предназначена для 16 v100 графических процессоров, а размер партии составляет 256 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ). Вам может потребоваться изменить MAX_SENTENCES или UPDATE_FREQ в соответствии с вашей средой. Чтобы отключить относительное положение, вы можете удалить --rel-pos .
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos Чтобы ускорить Finetune, мы устанавливаем N_EPOCH=5 для MNLI, QNLI и QQP и N_EPOCH=10 для других. Для mnli, N_CLASSES=3 и дополнительная настройка --valid-subset valid,valid1 используется для оценки Mnli-M/-м вместе. STS-B-это задача регрессии, поэтому мы устанавливаем N_CLASSES=1 , с дополнительными настройками --regression-target и METRIC=pearson . Для колы мы установили METRIC=mcc .
LR обыскивается из {2e-5, 3e-5, 4e-5, 5e-5} , каждый LR будет управлять 5 различными семенами, и мы используем их медиана в результате этого LR . Результат лучшего LR будет использоваться.
ПРИМЕЧАНИЕ . Если используется ваша предварительная модель --rel-pos , вам следует установить --rel-pos в Conetune, в противном случае вы должны удалить ее.
Мы также отпускаем контрольную точку TUPE-R (с --rel-pos ), для воспроизводимости.
Вы можете цитировать нашу бумагу
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


