TUPE
1.0.0
Implementação para a codificação posicional de repensar o papel no pré-treinamento de idiomas.
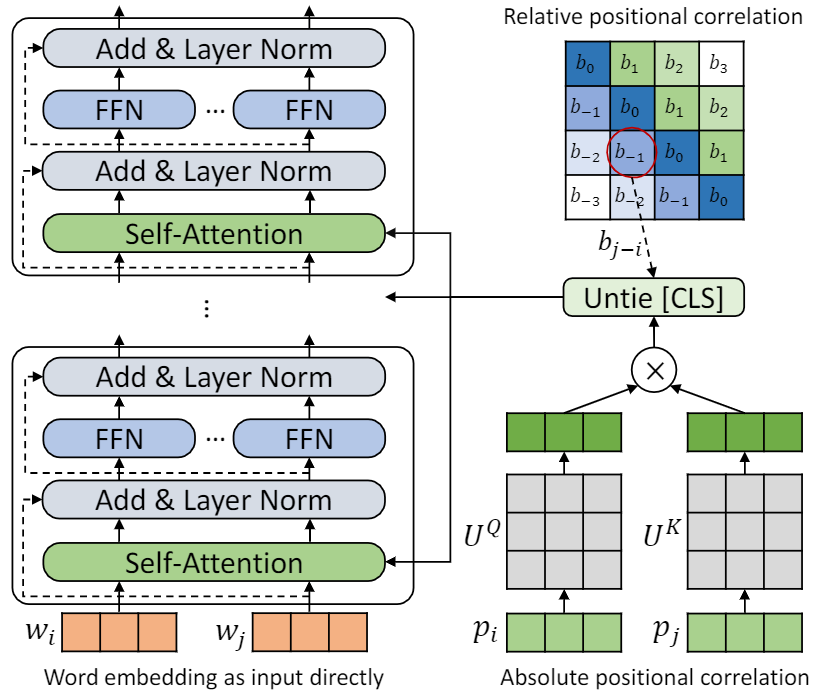
Este repositório deve demonstrar tupe (transformador com codificação posicional desamarrada). Os detalhes do algoritmo podem ser encontrados em nosso artigo. A Tupe pode superar outras linhas de base na referência de cola por uma grande margem. Em particular, ele pode atingir uma pontuação mais alta que as linhas de base, usando apenas 30% de custos computacionais pré-treinamento.
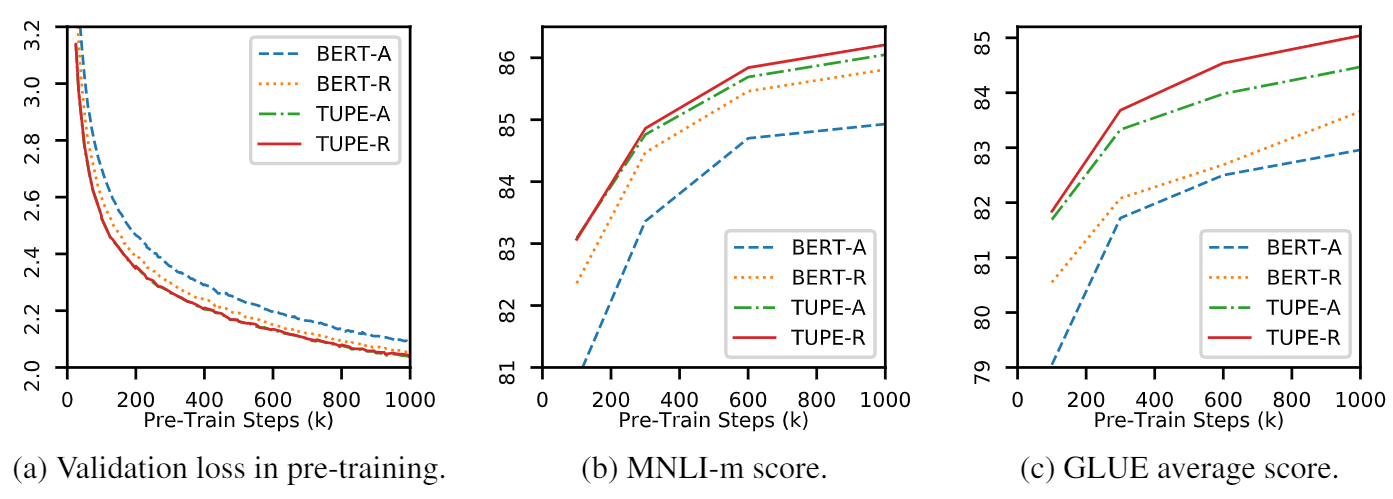
Devido a recursos computacionais limitados, usamos o modelo de pré-treinamento mais utilizado, Bert-Base, para verificação. No entanto, observe que nosso método pode ser usado para modelos maiores (e melhores) baseados em transformadores, como Roberta, Electra e Unilm, e melhorá-los. Além disso, como a modificação é simples e fácil, você pode aplicar facilmente o TUPE em seus modelos.
Nossa implementação é baseada no Fairseq, com várias alterações:
fairseq/modules/transformer_sentence_encoder.py e fairseq/modules/multihead_attention.py para codificação posicional desamarrada.max-epoch com warmup-ratio no Finetune, em vez de definir diferentes total-num-update e warmup-updates para diferentes tarefas. Mais detalhes, consulte Fairseq. Brevemente,
--cuda_ext , para treinamento de precisão mistaInstalação da fonte
Para instalar o TUPE da fonte e desenvolver localmente:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . O pré-processamento depende do MosesDecoder, você pode executar o seguinte script para puxá-lo.
cd TUPE
git submodule update --init Consulte as etapas no preprocess/pretrain/process.sh .
Consulte as etapas em preprocess/glue/process.sh .
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
A configuração acima é para 16 GPUs V100 e o tamanho do lote é 256 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ). Pode ser necessário alterar MAX_SENTENCES ou UPDATE_FREQ de acordo com o seu ambiente. Para desativar a posição relativa, você pode remover --rel-pos .
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos Para acelerar o Finetune, definimos N_EPOCH=5 para mnli, qnli e qqp e N_EPOCH=10 para outros. Para mnli, N_CLASSES=3 e uma configuração adicional --valid-subset valid,valid1 é usada para avaliar o mnli-m/-mm juntos. STS-B é uma tarefa de regressão, então definimos N_CLASSES=1 , com configurações adicionais --regression-target e METRIC=pearson . Para cola, definimos METRIC=mcc .
LR é pesquisado de {2e-5, 3e-5, 4e-5, 5e-5} , cada LR será executado por 5 sementes diferentes e usamos a mediana delas como resultado desse LR . O resultado do melhor LR será usado.
NOTA : Se o seu modelo de pré-treinamento usado --rel-pos , você deverá definir --rel-pos no Finetune, caso contrário, você deverá removê-lo.
Também lançamos o ponto de verificação do TUPE-R (com --rel-pos ), para reprodutibilidade.
Você pode citar nosso artigo por
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


