TUPE
1.0.0
Implementierung für das Papier überdenken Positionscodierung in der Sprache vor dem Training.
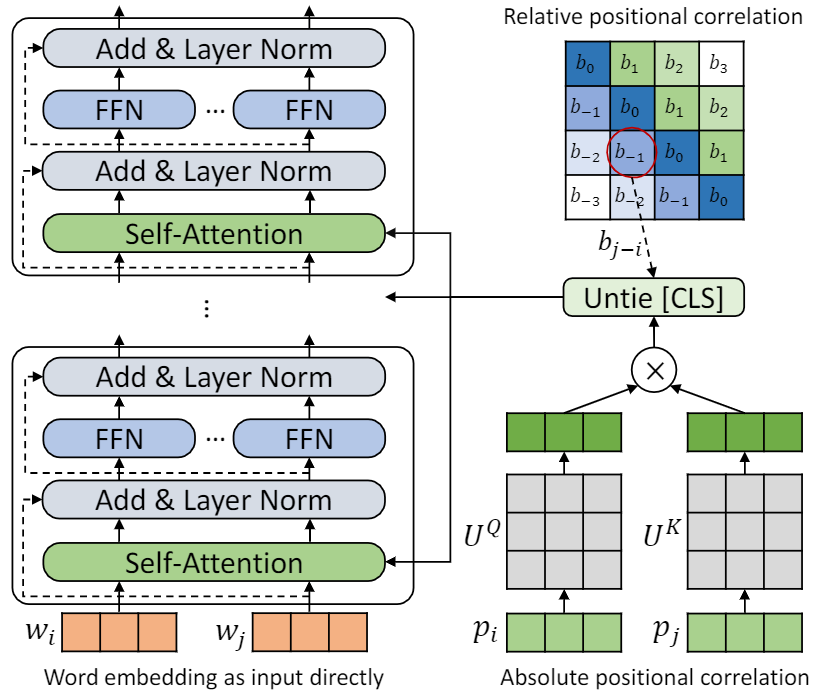
Dieses Repo soll TUPE (Transformator mit ungebrannter Positionscodierung) demonstrieren. Die Algorithmusdetails finden sich in unserem Artikel. Tupe kann andere Baselines am Klebstoff -Benchmark mit einem großen Vorsprung übertreffen. Insbesondere kann es eine höhere Punktzahl erzielen als Basislinien, während nur 30% der Rechenkosten vor dem Training verwendet werden.
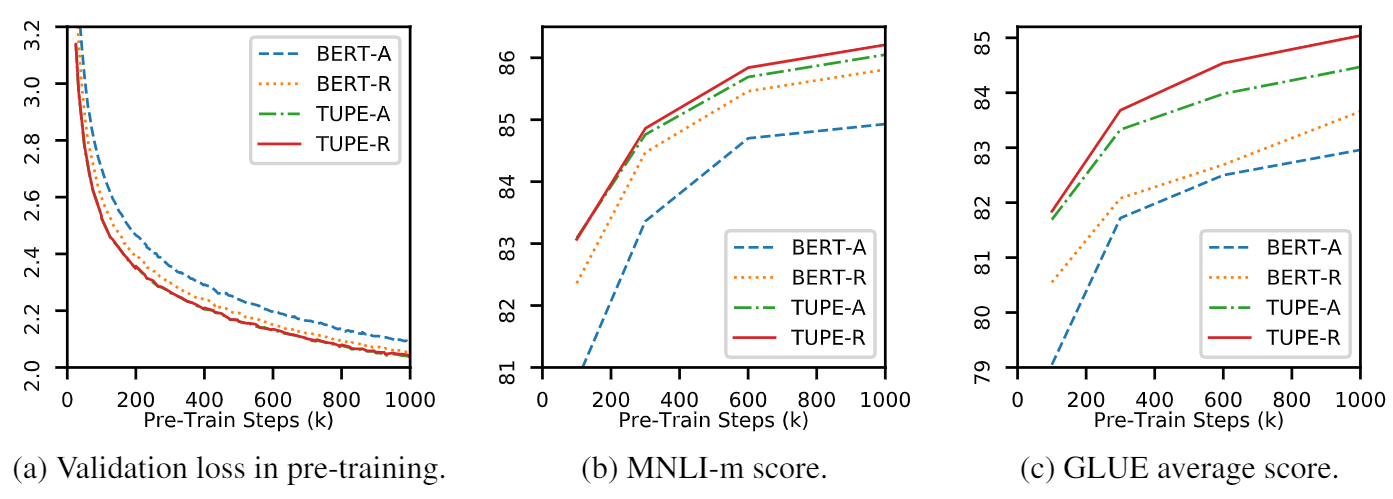
Aufgrund begrenzter Rechenressourcen verwenden wir das am häufigsten verwendete Vor-Training-Modell Bert-Base zur Überprüfung. Bitte beachten Sie jedoch, dass unsere Methode für größere (und bessere) Transformator-basierte Modelle wie Roberta, Electra und Unilm verwendet werden könnte und diese weiter verbessern. Da die Modifikation einfach und einfach ist, können Sie Tupe problemlos in Ihren Modellen anwenden.
Unsere Implementierung basiert auf Fairseq mit mehreren Änderungen:
fairseq/modules/transformer_sentence_encoder.py und fairseq/modules/multihead_attention.py für die ungezwungene Positioncodierung.max-epoch mit warmup-ratio in Finetune, anstatt unterschiedliche total-num-update und warmup-updates für verschiedene Aufgaben zu setzen. Weitere Details finden Sie in Fairseq. Knapp,
--cuda_ext für gemischte PräzisionstrainingInstallieren von Quelle
So installieren Sie Tupe aus der Quelle und entwickeln Sie sich lokal:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . Die Vorverarbeitung basiert auf Mosesdecoder. Sie können das folgende Skript ausführen, um es zu ziehen.
cd TUPE
git submodule update --init Siehe die Schritte in preprocess/pretrain/process.sh .
Siehe die Schritte in preprocess/glue/process.sh .
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
Die obige Einstellung ist für 16 V100 -GPUs und die Stapelgröße 256 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ). Möglicherweise müssen Sie MAX_SENTENCES oder UPDATE_FREQ entsprechend Ihrer Umgebung ändern. Um die relative Position zu deaktivieren, können Sie --rel-pos entfernen.
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos Um das Finetune zu beschleunigen, setzen wir N_EPOCH=5 für MNLI, QNLI und QQP und N_EPOCH=10 für andere. Für MNLI, N_CLASSES=3 und eine zusätzliche Einstellung --valid-subset valid,valid1 zur gemeinsamen Bewertung von MNLI-M/-mm verwendet. STS-B ist eine Regressionsaufgabe, daher setzen wir N_CLASSES=1 mit zusätzlichen Einstellungen --regression-target und METRIC=pearson . Für Cola setzen wir METRIC=mcc .
LR wird aus {2e-5, 3e-5, 4e-5, 5e-5} durchsucht. Jeder LR wird von 5 verschiedenen Samen betrieben, und wir verwenden den Median als Ergebnis dieser LR . Das Ergebnis des besten LR wird verwendet.
HINWEIS : Wenn Ihr Vorab-Modell verwendet wird --rel-pos , sollten Sie --rel-pos in der Finetune, einstellen, sonst sollten Sie es entfernen.
Wir geben auch den Checkpoint von TUPE-R (mit --rel-pos ) zur Reproduzierbarkeit frei.
Sie können unser Papier zitieren
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


