TUPE
1.0.0
Implementación para el documento repensando la codificación posicional en la pre-entrenamiento del lenguaje.
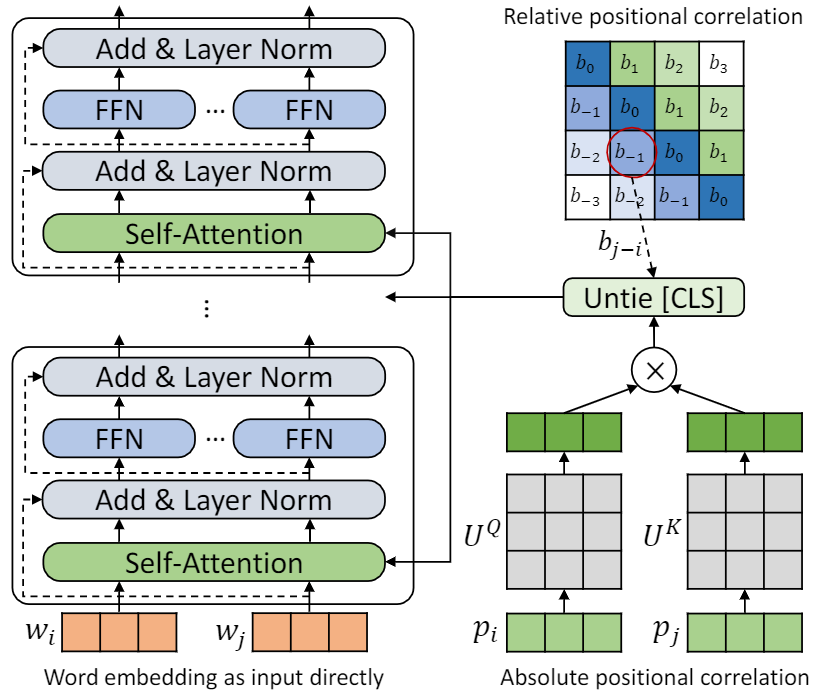
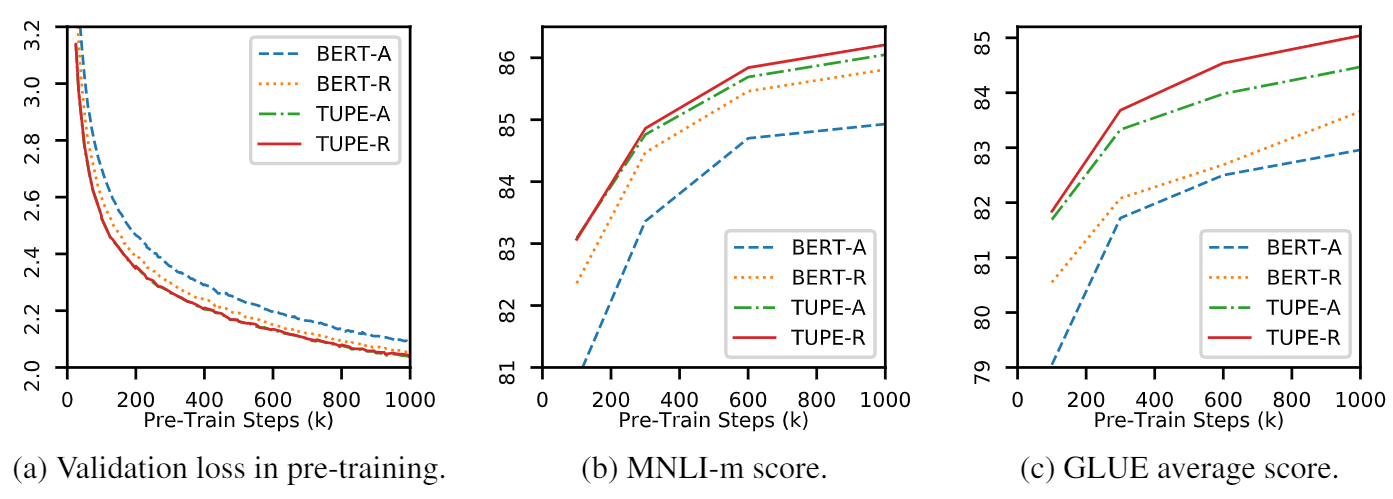
Este repositorio es para demostrar TUPE (transformador con codificación posicional desatada). Los detalles del algoritmo se pueden encontrar en nuestro artículo. Tupe puede superar a otras líneas de base en el punto de referencia de pegamento por un gran margen. En particular, puede lograr una puntuación más alta que las líneas de base al tiempo que solo usa costos computacionales previos al entrenamiento del 30%.
Debido a los recursos computacionales limitados, utilizamos el modelo de pre-entrenamiento más utilizado, Bert-Base, para la verificación. Sin embargo, tenga en cuenta que nuestro método podría usarse para modelos basados en transformadores más grandes (y mejores), como Roberta, Electra y Unilm, y mejorarlos aún más. Además, dado que la modificación es simple y fácil, puede aplicar fácilmente TUPE en sus modelos.
Nuestra implementación se basa en Fairseq, con varios cambios:
fairseq/modules/transformer_sentence_encoder.py y fairseq/modules/multihead_attention.py para una codificación posicional desatada.max-epoch con warmup-ratio en Finetune, en lugar de establecer diferentes total-num-update y warmup-updates para diferentes tareas. Más detalles ver Fairseq. Brevemente,
--cuda_ext , para capacitación de precisión mixtaInstalación desde la fuente
Para instalar TUPE desde la fuente y desarrollar localmente:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . El preprocesamiento se basa en Mosesdecoder, puede ejecutar el siguiente script para extraerlo.
cd TUPE
git submodule update --init Consulte los pasos en preprocess/pretrain/process.sh .
Consulte los pasos en preprocess/glue/process.sh .
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
La configuración anterior es para 16 GPU V100, y el tamaño de lote es 256 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ). Es posible que deba cambiar MAX_SENTENCES o UPDATE_FREQ de acuerdo con su entorno. Para deshabilitar la posición relativa, puede eliminar --rel-pos .
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos Para acelerar Finetune, configuramos N_EPOCH=5 para mnli, qnli y qqp, y N_EPOCH=10 para otros. Para MNLI, N_CLASSES=3 y una configuración adicional --valid-subset valid,valid1 se usa para evaluar MNLI-M/-MM juntos. STS-B es una tarea de regresión, por lo que establecemos N_CLASSES=1 , con configuraciones adicionales --regression-target y METRIC=pearson . Para COLA, establecemos METRIC=mcc .
Se busca LR desde {2e-5, 3e-5, 4e-5, 5e-5} , cada LR será ejecutado por 5 semillas diferentes, y usamos la mediana de ellas como resultado de ese LR . Se utilizará el resultado de la mejor LR .
Nota : Si su modelo de pre-proyren utilizado --rel-pos , debe establecer --rel-pos en Finetune, de lo contrario, debe eliminarlo.
También lanzamos el punto de control de TUPE-R (con --rel-pos ), para la reproducibilidad.
Puedes citar nuestro artículo por
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


