TUPE
1.0.0
تنفيذ الورق إعادة التفكير في الموضعية في التدريب قبل اللغة.
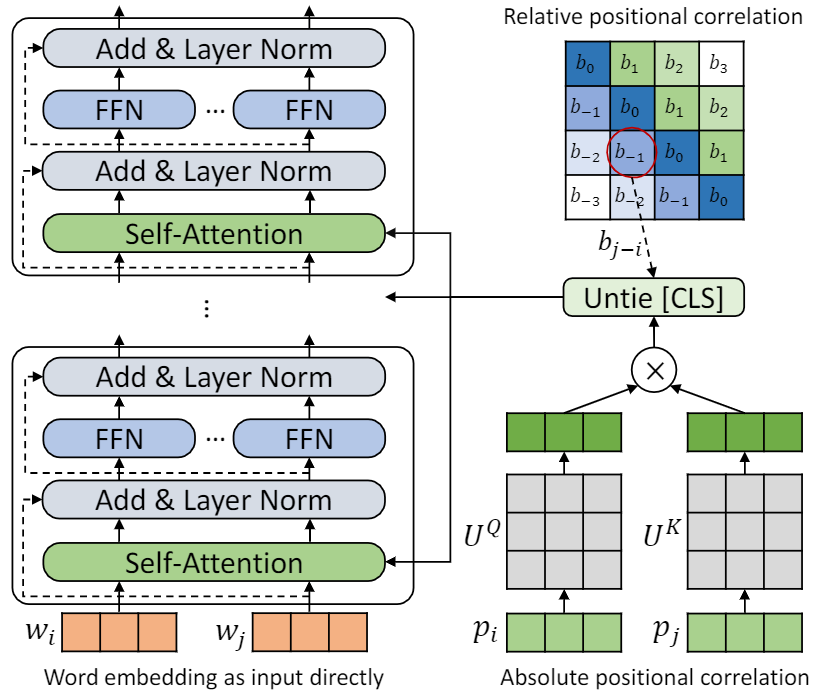
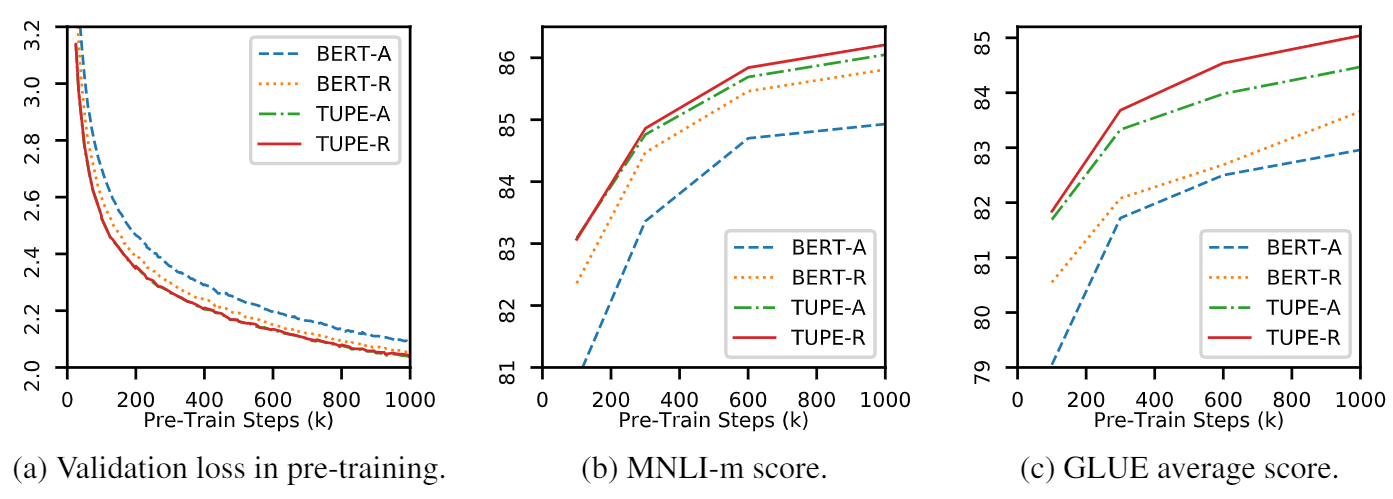
هذا الريبو هو إظهار tupe (محول مع الترميز الموضعي غير مرتب). يمكن العثور على تفاصيل الخوارزمية في ورقتنا. يمكن أن تتفوق Tupe على خطوط الأساس الأخرى على معيار الغراء بهامش كبير. على وجه الخصوص ، يمكن أن يحقق درجة أعلى من خطوط الأساس مع استخدام تكاليف حسابية ما قبل التدريب فقط 30 ٪.
نظرًا لموارد الحسابية المحدودة ، فإننا نستخدم نموذج ما قبل التدريب الأكثر استخدامًا ، Bert-Base ، للتحقق. ومع ذلك ، يرجى ملاحظة أنه يمكن استخدام طريقتنا في النماذج الأكبر (والأفضل) القائمة على المحولات ، مثل Roberta و Electra و Unilm ، وزيادة تحسينها. علاوة على ذلك ، نظرًا لأن التعديل بسيط وسهل ، يمكنك تطبيق Tupe بسهولة في النماذج الخاصة بك.
يعتمد تنفيذنا على FairSeq ، مع العديد من التغييرات:
fairseq/modules/transformer_sentence_encoder.py و fairseq/modules/multihead_attention.py لتشفير الموضع غير المرتبط.max-epoch مع warmup-ratio في Finetune ، بدلاً من وضع اختلاف total-num-update warmup-updates في المهام المختلفة. مزيد من التفاصيل انظر Fairseq. باختصار،
--cuda_ext ، للتدريب الدقيق المختلطالتثبيت من المصدر
لتثبيت Tupe من المصدر وتطوير محليًا:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . تعتمد المعالجة المسبقة على MosesDecoder ، يمكنك تشغيل البرنامج النصي التالي لسحبه.
cd TUPE
git submodule update --init ارجع إلى الخطوات في preprocess/pretrain/process.sh .
ارجع إلى الخطوات في preprocess/glue/process.sh .
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
الإعداد أعلاه هو لـ 16 V100 وحدات معالجة الرسومات ، وحجم الدُفعة هو 256 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ). قد تحتاج إلى تغيير MAX_SENTENCES أو UPDATE_FREQ وفقًا لبيئتك. لتعطيل الموضع النسبي ، يمكنك إزالته- --rel-pos .
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos لتسريع finetune ، قمنا بتعيين N_EPOCH=5 لـ mnli و qnli و qqp ، و N_EPOCH=10 للآخرين. بالنسبة إلى mnli ، N_CLASSES=3 وإعداد إضافي- --valid-subset valid,valid1 لتقييم mnli-m/-mm معًا. STS-B هي مهمة الانحدار ، لذلك قمنا بتعيين N_CLASSES=1 ، مع إعدادات إضافية --regression-target METRIC=pearson . بالنسبة للكولا ، قمنا بتعيين METRIC=mcc .
يتم تفتيش LR من {2e-5, 3e-5, 4e-5, 5e-5} ، سيتم تشغيل كل LR بواسطة 5 بذور مختلفة ، ونستخدم متوسطها نتيجة لذلك LR . سيتم استخدام نتيجة أفضل LR .
ملاحظة : إذا تم استخدام نموذج ما قبل التدريب الخاص بك- --rel-pos ، فيجب عليك تعيينه- --rel-pos في finetune ، وإلا يجب إزالته.
نقوم أيضًا بإصدار نقطة تفتيش Tupe-R (مع-- --rel-pos ) ، من أجل الاستنساخ.
يمكنك الاستشهاد بالورق الخاص بنا
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


