TUPE
1.0.0
การดำเนินการสำหรับการคิดใหม่การเข้ารหัสตำแหน่งในการฝึกอบรมภาษาก่อนการฝึกอบรม
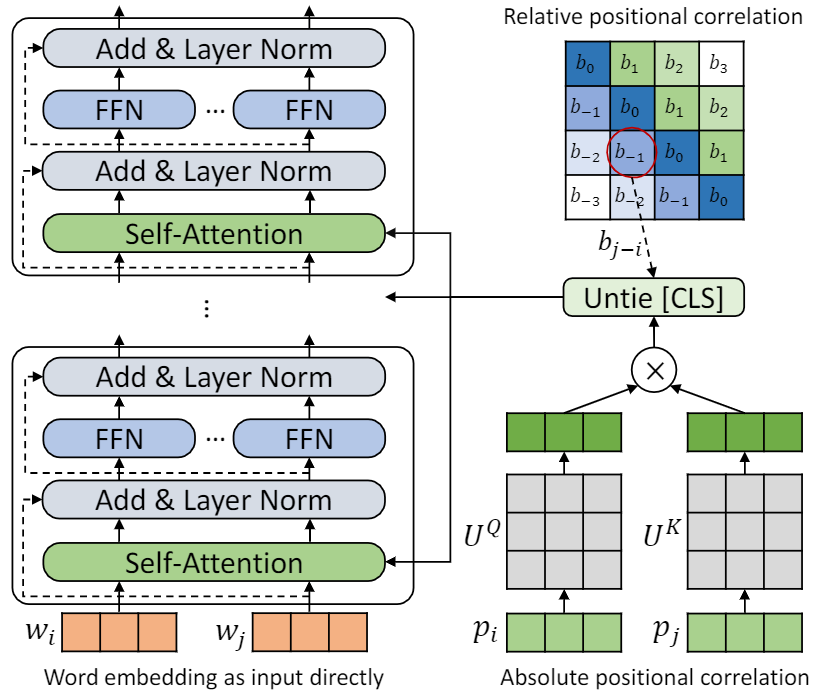
repo นี้คือการแสดงให้เห็นถึง TUPE (หม้อแปลงที่มีการเข้ารหัสตำแหน่งที่ไม่ได้รับการแก้ไข) รายละเอียดอัลกอริทึมสามารถพบได้ในบทความของเรา TUPE สามารถมีประสิทธิภาพเหนือกว่าเส้นเขตแดนอื่น ๆ บนเกณฑ์มาตรฐานกาวโดยระยะขอบขนาดใหญ่ โดยเฉพาะอย่างยิ่งมันสามารถบรรลุคะแนนสูงกว่า baselines ในขณะที่ใช้ค่าใช้จ่ายในการคำนวณล่วงหน้า 30% เท่านั้น
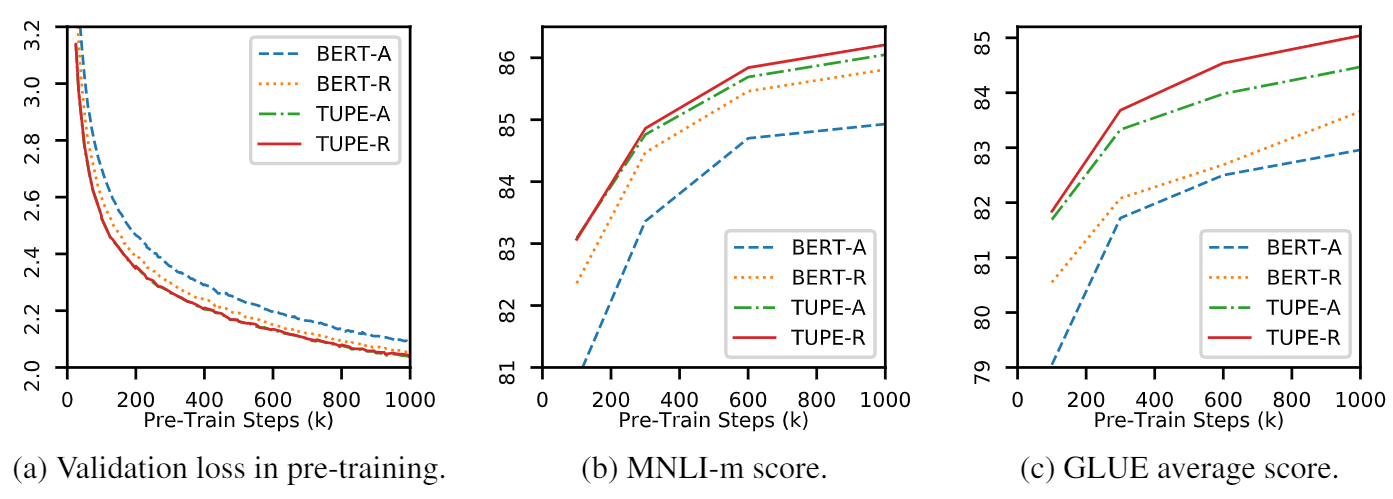
เนื่องจากทรัพยากรการคำนวณที่ จำกัด เราใช้รูปแบบการฝึกอบรมก่อนการฝึกอบรมที่ใช้กันอย่างแพร่หลายมากที่สุดสำหรับการตรวจสอบ อย่างไรก็ตามโปรดทราบว่าวิธีการของเราสามารถใช้สำหรับรุ่นที่มีขนาดใหญ่กว่า (และดีกว่า) เช่น Roberta, Electra และ Unilm และปรับปรุงให้ดีขึ้น นอกจากนี้เนื่องจากการดัดแปลงนั้นง่ายและง่ายคุณสามารถใช้ TUPE ในโมเดลของคุณได้อย่างง่ายดาย
การดำเนินการของเราขึ้นอยู่กับ Fairseq โดยมีการเปลี่ยนแปลงหลายอย่าง:
fairseq/modules/transformer_sentence_encoder.py และ fairseq/modules/multihead_attention.py สำหรับการเข้ารหัสตำแหน่งmax-epoch ด้วย warmup-ratio ใน Finetune แทนที่จะตั้งค่า total-num-update ที่แตกต่างกันและ warmup-updates สำหรับงานที่แตกต่างกัน รายละเอียดเพิ่มเติมดู Fairseq สั้น ๆ
--cuda_ext สำหรับการฝึกอบรมแบบผสมผสานแบบผสมผสานการติดตั้งจากแหล่งที่มา
ในการติดตั้ง TUPE จากแหล่งที่มาและพัฒนาในพื้นที่:
git clone https://github.com/guolinke/TUPE
cd TUPE
pip install --editable . การประมวลผลล่วงหน้าขึ้นอยู่กับ Mosesdecoder คุณสามารถเรียกใช้สคริปต์ต่อไปนี้เพื่อดึงมัน
cd TUPE
git submodule update --init อ้างถึงขั้นตอนใน preprocess/pretrain/process.sh
อ้างถึงขั้นตอนใน preprocess/glue/process.sh
DATA_DIR=./path_to_your_data/
SAVE_DIR=./your_own_save_path/
TOTAL_UPDATES=1000000
WARMUP_UPDATES=10000
PEAK_LR=0.0001
MAX_POSITIONS=512
MAX_SENTENCES=16
UPDATE_FREQ=1
SEED=your_seed
python train.py $DATA_DIR --fp16 --num-workers 16 --ddp-backend=c10d
--task masked_lm --criterion masked_lm --arch bert_base
--sample-break-mode complete --tokens-per-sample $MAX_POSITIONS
--optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-6 --clip-norm 1.0
--lr-scheduler polynomial_decay --lr $PEAK_LR --warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_UPDATES
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01
--max-sentences $MAX_SENTENCES --update-freq $UPDATE_FREQ --seed $SEED
--mask-prob 0.15
--embedding-normalize
--max-update $TOTAL_UPDATES --log-format simple --log-interval 100
--keep-updates-list 100000 300000 600000 1000000
--save-interval-updates 25000 --keep-interval-updates 3 --no-epoch-checkpoints --skip-invalid-size-inputs-valid-test
--save-dir $SAVE_DIR --rel-pos
การตั้งค่าข้างต้นสำหรับ 16 V100 GPU และขนาดแบทช์คือ 256 ( n_gpu * MAX_SENTENCES * UPDATE_FREQ ) คุณอาจต้องเปลี่ยน MAX_SENTENCES หรือ UPDATE_FREQ ตามสภาพแวดล้อมของคุณ ในการปิดการใช้งานตำแหน่งสัมพัทธ์คุณสามารถลบ --rel-pos
DATA_DIR=./path_to_your_downstream_data
SAVE_DIR=./path_to_your_save_dir
BERT_MODEL_PATH=./path_to_your_checkpoint
BATCH_SIZE=32
N_EPOCH=10 # 5 for MNLI, QNLI, QQP
SEED=your_seed
WARMUP_RATIO=0.06
N_CLASSES=2 # 3 for MNLI, 1 for STS-B
LR=0.00005 # search from 2e-5, 3e-5, 4e-5, 5e-5
METRIC=accuracy # mcc for CoLA, pearson for STS-B
python train.py $DATA_DIR --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128
--restore-file $BERT_MODEL_PATH
--max-positions 512
--max-sentences $BATCH_SIZE
--max-tokens 4400
--task sentence_prediction
--reset-optimizer --reset-dataloader --reset-meters
--required-batch-size-multiple 1
--init-token 0 --separator-token 2
--arch bert_base
--criterion sentence_prediction
--num-classes $N_CLASSES
--dropout 0.1 --attention-dropout 0.1
--weight-decay 0.01 --optimizer adam --adam-betas ' (0.9, 0.999) ' --adam-eps 1e-06
--clip-norm 1.0 --validate-interval-updates 2
--lr-scheduler polynomial_decay --lr $LR --warmup-ratio $WARMUP_RATIO
--max-epoch $N_EPOCH --seed $SEED --save-dir $SAVE_DIR --no-progress-bar --log-interval 100 --no-epoch-checkpoints --no-last-checkpoints --no-best-checkpoints
--find-unused-parameters --skip-invalid-size-inputs-valid-test --truncate-sequence --embedding-normalize
--tensorboard-logdir .
--best-checkpoint-metric $METRIC --maximize-best-checkpoint-metric --rel-pos เพื่อเพิ่มความเร็ว Finetune เราตั้งค่า N_EPOCH=5 สำหรับ mnli, qnli และ qqp และ N_EPOCH=10 สำหรับผู้อื่น สำหรับ MNLI, N_CLASSES=3 และการตั้งค่าเพิ่มเติม --valid-subset valid,valid1 ใช้สำหรับการประเมิน MNLI-M/-MM ด้วยกัน STS-B เป็นงานการถดถอยดังนั้นเราจึงตั้งค่า N_CLASSES=1 พร้อมการตั้งค่าเพิ่มเติม --regression-target และ METRIC=pearson สำหรับ Cola เราตั้งค่า METRIC=mcc
LR ถูกค้นหาจาก {2e-5, 3e-5, 4e-5, 5e-5} , แต่ละ LR จะทำงานโดย 5 เมล็ดที่แตกต่างกันและเราใช้ค่ามัธยฐานของพวกเขาเป็นผลมาจาก LR นั้น ผลลัพธ์ของ LR ที่ดีที่สุดจะถูกนำมาใช้
หมายเหตุ : หากรูปแบบการเตรียมการของคุณใช้ --rel-pos คุณควรตั้ง --rel-pos ใน finetune มิฉะนั้นคุณควรลบออก
นอกจากนี้เรายังปล่อยจุดตรวจสอบของ TUPE-R (พร้อม --rel-pos ) เพื่อการทำซ้ำ
คุณสามารถอ้างอิงกระดาษของเราได้โดย
@inproceedings{
ke2021rethinking,
title={Rethinking Positional Encoding in Language Pre-training},
author={Guolin Ke and Di He and Tie-Yan Liu},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=09-528y2Fgf}
}


