ms swift
v3.0.0

Modelscope社区网站
中文英语
纸|英语文档| | |
swift2.x en doc | swift2.x中文文档
您可以通过添加我们的小组与我们联系并与我们沟通:
| DISCORD组 | 微信集团 |
|---|---|
 |  |
? MS Swift是由Modelscope社区提供的官方框架,用于微调和部署大型语言模型和多模式大型模型。它目前支持培训(预训练,微调,人类对齐),400多个大型模型和150多个多模式大型模型的推理,评估,量化和部署。这些大型语言模型(LLM)包括Qwen2.5,Llama3.3,GLM4,InternLM2.5,Yi1.5,Mismtral,DeepSeek2.5,Baichuan2,Gemma2,gemma2和telechat2。多模式LLM包括QWEN2-VL,QWEN2-AUDIO,LLAMA3.2-VISION,LLAVA,INTENTVL2.5,MinICPM-V-2.6,GLM4V,XCOMPOSER2.5,YI-II-VL,YI-vl,DeepSeek-VL2,Phi3.5-Vision和Got-vision和Got-ocr2。
?此外,MS Swift收集了最新的培训技术,包括Lora,Qlora,Llama-Pro,Longlora,Galore,Galore,Q-Galore,Lora+,Lisa,Dora,Dora,Foura,Fourierft,Reft,Reft,Unsploth和Liger。 MS-SWIFT支持使用VLLM和LMDEPLOY的推理,评估和部署模块的加速,并使用GPTQ,AWQ和BNB等技术支持大型模型和多模式大型模型的量化。为了帮助研究人员和开发人员进行微调和更轻松地应用大型模型,MS-Swift还提供了基于Gradio的Web-UI界面和大量最佳实践。
为什么选择MS-Swift?
--infer_backend vllm/lmdeploy 。使用PIP安装:
pip install ms-swift -U从来源安装:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . 单个3090 GPU上QWEN2.5-7B教学的10分钟自我认知微调:
# 22GB
CUDA_VISIBLE_DEVICES=0
swift sft
--model Qwen/Qwen2.5-7B-Instruct
--train_type lora
--dataset ' AI-ModelScope/alpaca-gpt4-data-zh#500 '
' AI-ModelScope/alpaca-gpt4-data-en#500 '
' swift/self-cognition#500 '
--torch_dtype bfloat16
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--learning_rate 1e-4
--lora_rank 8
--lora_alpha 32
--target_modules all-linear
--gradient_accumulation_steps 16
--eval_steps 50
--save_steps 50
--save_total_limit 2
--logging_steps 5
--max_length 2048
--output_dir output
--system ' You are a helpful assistant. '
--warmup_ratio 0.05
--dataloader_num_workers 4
--model_author swift
--model_name swift-robot训练完成后,使用以下命令对受过训练的权重执行推理。 --adapters选项应替换为培训生成的最后一个检查点文件夹。由于适配器文件夹包含来自培训的参数文件,因此无需单独指定--model或--system 。
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--temperature 0
--max_new_tokens 2048
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--merge_lora true
--infer_backend vllm
--max_model_len 8192
--temperature 0
--max_new_tokens 2048Web-UI是基于Gradio接口技术的零阈值培训和部署接口解决方案。有关更多详细信息,您可以在此处检查。
SWIFT_UI_LANG=en swift web-ui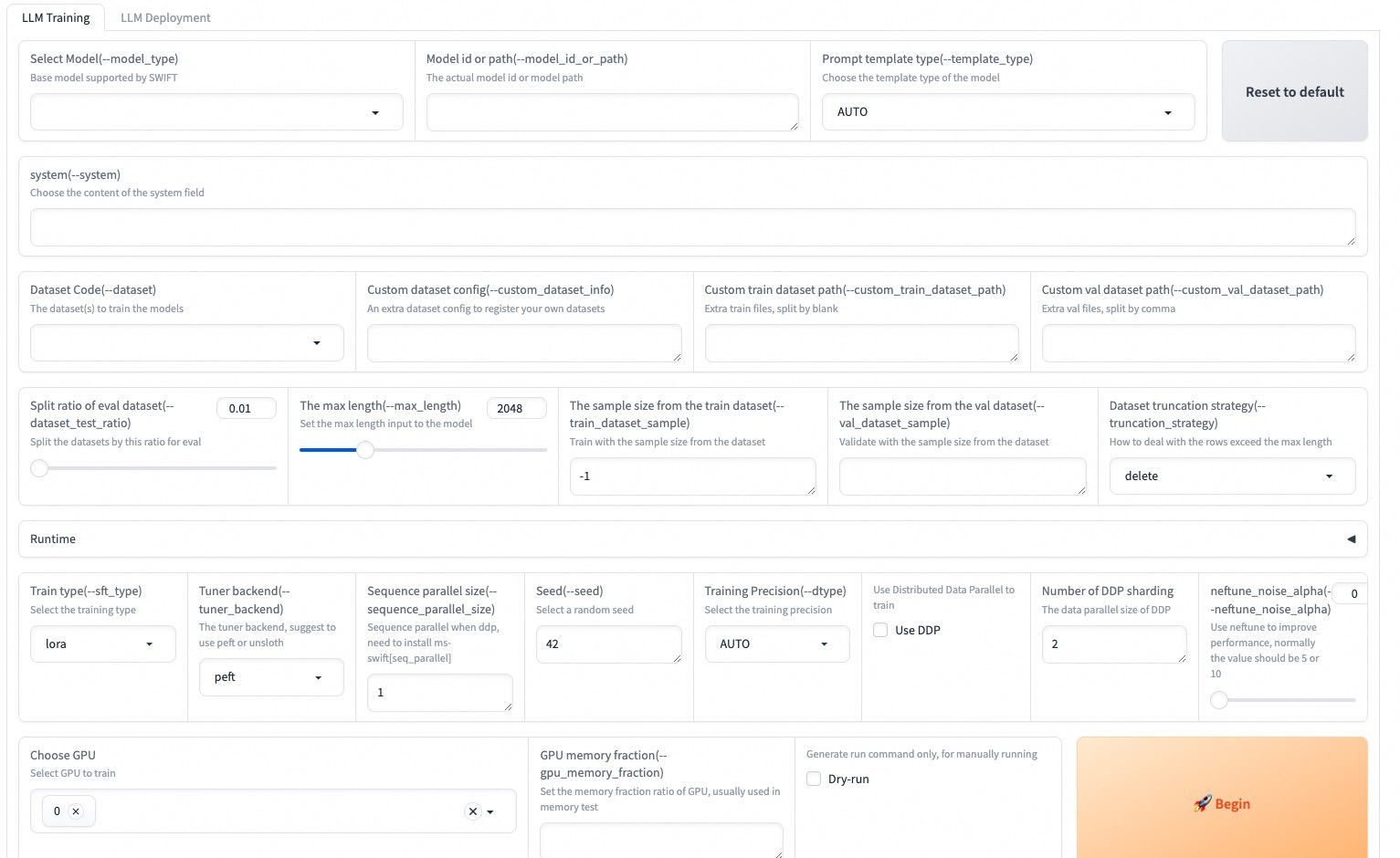
MS-SWIFT还支持使用Python的培训和推理。以下是用于训练和推理的伪代码。有关更多详细信息,您可以在此处参考。
训练:
# Retrieve the model and template, and add a trainable LoRA module
model , tokenizer = get_model_tokenizer ( model_id_or_path , ...)
template = get_template ( model . model_meta . template , tokenizer , ...)
model = Swift . prepare_model ( model , lora_config )
# Download and load the dataset, and encode the text into tokens
train_dataset , val_dataset = load_dataset ( dataset_id_or_path , ...)
train_dataset = EncodePreprocessor ( template = template )( train_dataset , num_proc = num_proc )
val_dataset = EncodePreprocessor ( template = template )( val_dataset , num_proc = num_proc )
# Train the model
trainer = Seq2SeqTrainer (
model = model ,
args = training_args ,
data_collator = template . data_collator ,
train_dataset = train_dataset ,
eval_dataset = val_dataset ,
template = template ,
)
trainer . train ()推理:
# Perform inference using the native PyTorch engine
engine = PtEngine ( model_id_or_path , adapters = [ lora_checkpoint ])
infer_request = InferRequest ( messages = [{ 'role' : 'user' , 'content' : 'who are you?' }])
request_config = RequestConfig ( max_tokens = max_new_tokens , temperature = temperature )
resp_list = engine . infer ([ infer_request ], request_config )
print ( f'response: { resp_list [ 0 ]. choices [ 0 ]. message . content } ' )这是使用MS-Swift部署培训的最简单示例。有关更多详细信息,您可以检查示例。
| 有用的链接 |
|---|
| 命令行参数 |
| 支持的模型和数据集 |
| 自定义模型,自定义数据集 |
| LLM教程 |
预训练:
# 8*A100
NPROC_PER_NODE=8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
swift pt
--model Qwen/Qwen2.5-7B
--dataset swift/chinese-c4
--streaming true
--train_type full
--deepspeed zero2
--output_dir output
--max_steps 100000
...微调:
CUDA_VISIBLE_DEVICES=0 swift sft
--model Qwen/Qwen2.5-7B-Instruct
--dataset AI-ModelScope/alpaca-gpt4-data-en
--train_type lora
--output_dir output
...RLHF:
CUDA_VISIBLE_DEVICES=0 swift rlhf
--rlhf_type dpo
--model Qwen/Qwen2.5-7B-Instruct
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji:en
--train_type lora
--output_dir output
...CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--stream true
--infer_backend pt
--max_new_tokens 2048
# LoRA
CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--adapters swift/test_lora
--stream true
--infer_backend pt
--temperature 0
--max_new_tokens 2048CUDA_VISIBLE_DEVICES=0 swift deploy
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend vllmCUDA_VISIBLE_DEVICES=0 swift eval
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend lmdeploy
--eval_dataset ARC_cCUDA_VISIBLE_DEVICES=0 swift export
--model Qwen/Qwen2.5-7B-Instruct
--quant_bits 4 --quant_method awq
--dataset AI-ModelScope/alpaca-gpt4-data-zh
--output_dir Qwen2.5-7B-Instruct-AWQ此框架是根据Apache许可证(版本2.0)获得许可的。对于模型和数据集,请参阅原始资源页面并遵循相应的许可证。
@misc { zhao2024swiftascalablelightweightinfrastructure ,
title = { SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning } ,
author = { Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen } ,
year = { 2024 } ,
eprint = { 2408.05517 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.05517 } ,
}

