ms swift
v3.0.0

ModelsCope Community -Website
中文 | Englisch
Papier | Englische Dokumentation | 中文文档
Swift2.x en doc | Swift2.x 中文文档
Sie können uns kontaktieren und mit uns kommunizieren, indem Sie unsere Gruppe hinzufügen:
| Discord -Gruppe | Wechat -Gruppe |
|---|---|
 |  |
? MS-Swift ist ein offizielles Rahmen der ModelsCope Community für Feinabstimmung und Bereitstellung von großsprachigen Modellen und multimodalen großen Modellen. Derzeit unterstützt es das Training (Vorausbildung, Feinabstimmung, menschliche Ausrichtung), Inferenz, Bewertung, Quantisierung und Bereitstellung von über 400 großen Modellen und mehr als 150 multimodalen großen Modellen. Diese großsprachigen Modelle (LLMs) umfassen Modelle wie Qwen2.5, Lama3.3, GLM4, Internlm2.5, Yi1.5, Mistral, Deepseek2.5, Baichuan2, Gemma2 und Telechat2. Zu den multimodalen LLMs gehören Modelle wie Qwen2-VL, Qwen2-Audio, LLAMA3.2-Vision, Llava, Internvl2.5, Minicpm-V-2.6, GLM4V, Xcomposer2.5, Yi-VL, Deepseek-VL2, Phi3.5-Vision sowie Got-OCR2.
? Darüber hinaus sammelt MS-Swift die neuesten Trainingstechnologien, darunter Lora, Qlora, Llama-Pro, Longlora, Galore, Q-Galore, Lora+, Lisa, Dora, Fourierft, Reft, Unloth und Liger. MS-Swift unterstützt die Beschleunigung von Inferenz-, Bewertungs- und Bereitstellungsmodulen unter Verwendung von VllM und LMDeploy und unterstützt die Quantisierung großer Modelle und multimodaler großer Modelle unter Verwendung von Technologien wie GPTQ, AWQ und BNB. Um Forschern und Entwicklern zu helfen, große Modelle einfacher zu optimieren und anzuwenden, bietet MS-Swift auch eine Gradio-basierte Web-UI-Schnittstelle und eine Fülle von Best Practices.
Warum MS-Swift wählen?
--infer_backend vllm/lmdeploy angeben.Mit PIP zu installieren:
pip install ms-swift -UAus Quelle installieren:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . 10 Minuten Selbstkognition Feinabstimmung von Qwen2.5-7b-Instruktur auf einer einzigen 3090 GPU:
# 22GB
CUDA_VISIBLE_DEVICES=0
swift sft
--model Qwen/Qwen2.5-7B-Instruct
--train_type lora
--dataset ' AI-ModelScope/alpaca-gpt4-data-zh#500 '
' AI-ModelScope/alpaca-gpt4-data-en#500 '
' swift/self-cognition#500 '
--torch_dtype bfloat16
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--learning_rate 1e-4
--lora_rank 8
--lora_alpha 32
--target_modules all-linear
--gradient_accumulation_steps 16
--eval_steps 50
--save_steps 50
--save_total_limit 2
--logging_steps 5
--max_length 2048
--output_dir output
--system ' You are a helpful assistant. '
--warmup_ratio 0.05
--dataloader_num_workers 4
--model_author swift
--model_name swift-robot Verwenden Sie nach Abschluss des Trainings den folgenden Befehl, um Inferenz mit den geschulten Gewichten durchzuführen. Die Option --adapters sollte durch den letzten Checkpoint -Ordner aus dem Training ersetzt werden. Da der Adapter -Ordner die Parameterdateien aus dem Training enthält, müssen --model oder --system separat angegeben.
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--temperature 0
--max_new_tokens 2048
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--merge_lora true
--infer_backend vllm
--max_model_len 8192
--temperature 0
--max_new_tokens 2048Das Web-UI ist eine Null-Schwellenwert -Schulungs- und Bereitstellungsschnittstellenlösung, die auf der Gradio-Schnittstellen-Technologie basiert. Weitere Informationen finden Sie hier.
SWIFT_UI_LANG=en swift web-ui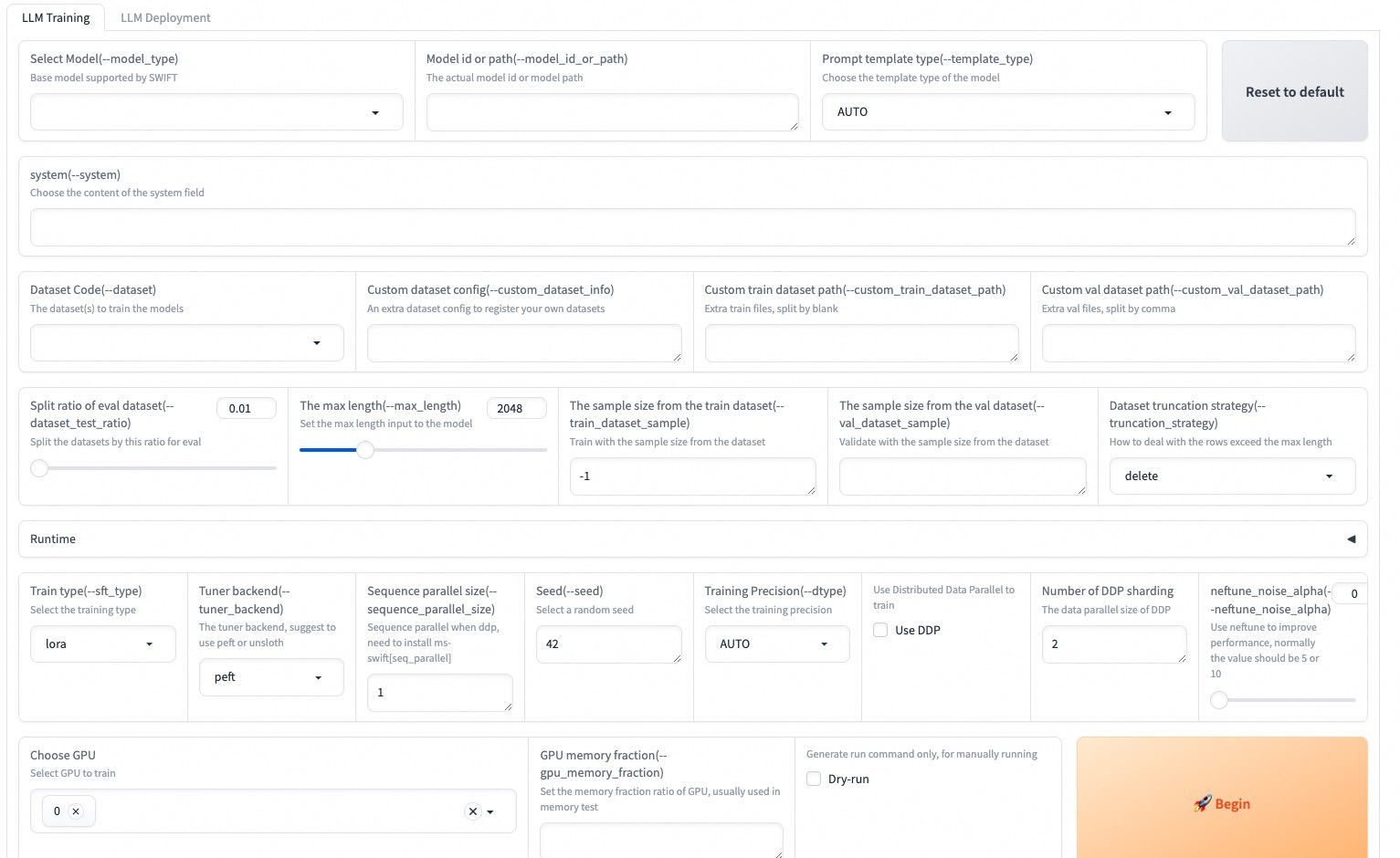
MS-Swift unterstützt auch Training und Inferenz mit Python. Unten finden Sie Pseudocode für Training und Inferenz. Weitere Informationen finden Sie hier.
Ausbildung:
# Retrieve the model and template, and add a trainable LoRA module
model , tokenizer = get_model_tokenizer ( model_id_or_path , ...)
template = get_template ( model . model_meta . template , tokenizer , ...)
model = Swift . prepare_model ( model , lora_config )
# Download and load the dataset, and encode the text into tokens
train_dataset , val_dataset = load_dataset ( dataset_id_or_path , ...)
train_dataset = EncodePreprocessor ( template = template )( train_dataset , num_proc = num_proc )
val_dataset = EncodePreprocessor ( template = template )( val_dataset , num_proc = num_proc )
# Train the model
trainer = Seq2SeqTrainer (
model = model ,
args = training_args ,
data_collator = template . data_collator ,
train_dataset = train_dataset ,
eval_dataset = val_dataset ,
template = template ,
)
trainer . train ()Schlussfolgerung:
# Perform inference using the native PyTorch engine
engine = PtEngine ( model_id_or_path , adapters = [ lora_checkpoint ])
infer_request = InferRequest ( messages = [{ 'role' : 'user' , 'content' : 'who are you?' }])
request_config = RequestConfig ( max_tokens = max_new_tokens , temperature = temperature )
resp_list = engine . infer ([ infer_request ], request_config )
print ( f'response: { resp_list [ 0 ]. choices [ 0 ]. message . content } ' )Hier ist das einfachste Beispiel für ein Training für die Bereitstellung mit MS-Swift. Weitere Informationen finden Sie in den Beispielen.
| Nützliche Links |
|---|
| Befehlszeilenparameter |
| Unterstützte Modelle und Datensätze |
| Benutzerdefinierte Modelle, benutzerdefinierte Datensätze |
| LLM Tutorial |
Vorausbildung:
# 8*A100
NPROC_PER_NODE=8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
swift pt
--model Qwen/Qwen2.5-7B
--dataset swift/chinese-c4
--streaming true
--train_type full
--deepspeed zero2
--output_dir output
--max_steps 100000
...Feinabstimmung:
CUDA_VISIBLE_DEVICES=0 swift sft
--model Qwen/Qwen2.5-7B-Instruct
--dataset AI-ModelScope/alpaca-gpt4-data-en
--train_type lora
--output_dir output
...RLHF:
CUDA_VISIBLE_DEVICES=0 swift rlhf
--rlhf_type dpo
--model Qwen/Qwen2.5-7B-Instruct
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji:en
--train_type lora
--output_dir output
...CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--stream true
--infer_backend pt
--max_new_tokens 2048
# LoRA
CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--adapters swift/test_lora
--stream true
--infer_backend pt
--temperature 0
--max_new_tokens 2048CUDA_VISIBLE_DEVICES=0 swift deploy
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend vllmCUDA_VISIBLE_DEVICES=0 swift eval
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend lmdeploy
--eval_dataset ARC_cCUDA_VISIBLE_DEVICES=0 swift export
--model Qwen/Qwen2.5-7B-Instruct
--quant_bits 4 --quant_method awq
--dataset AI-ModelScope/alpaca-gpt4-data-zh
--output_dir Qwen2.5-7B-Instruct-AWQDieses Framework ist unter der Apache -Lizenz (Version 2.0) lizenziert. Für Modelle und Datensätze finden Sie auf der ursprünglichen Ressourcenseite und befolgen Sie die entsprechende Lizenz.
@misc { zhao2024swiftascalablelightweightinfrastructure ,
title = { SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning } ,
author = { Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen } ,
year = { 2024 } ,
eprint = { 2408.05517 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.05517 } ,
}

