ms swift
v3.0.0

Site Web de la communauté Modelscope
中文 | anglais
Document | Documentation en anglais | 中文文档
Swift2.x en doc | swift2.x 中文文档
Vous pouvez nous contacter et communiquer avec nous en ajoutant notre groupe:
| Groupe de discorde | Groupe de WeChat |
|---|---|
 |  |
? MS-SWIFT est un cadre officiel fourni par la communauté Modelscope pour le réglage et le déploiement de modèles de grande langue et de grands modèles multimodaux. Il soutient actuellement la formation (pré-formation, réglage fin, alignement humain), l'inférence, l'évaluation, la quantification et le déploiement de plus de 400 grands modèles et de plus de 150 grands modèles multimodaux. Ces modèles de grande langue (LLMS) comprennent des modèles tels que Qwen2.5, Llama3.3, GLM4, Interlm2.5, Yi1.5, Mistral, Deepseek2.5, Baichuan2, Gemma2 et Telechat2. Les LLM multimodaux comprennent des modèles tels que Qwen2-VL, Qwen2-Audio, Llama3.2-Vision, Llava, Internvl2.5, MiniCPM-V-2.6, GLM4V, Xcomposer2.5, YI-VL, Deepseek-VL2, PHI3.5-vision et GOT-OCR2.
? En outre, MS-Swift rassemble les dernières technologies de formation, notamment Lora, Qlora, Llama-Pro, Longlora, Galore, Q-Galore, Lora +, Lisa, Dora, Fourierft, Reft, Unsloth et Liger. MS-SWIFT prend en charge l'accélération des modules d'inférence, d'évaluation et de déploiement à l'aide de VLLM et LMDEPLOY, et prend en charge la quantification de grands modèles et de grands modèles multimodaux à l'aide de technologies telles que GPTQ, AWQ et BNB. Pour aider les chercheurs et les développeurs à affiner et à appliquer plus de grands modèles, MS-SWIFT fournit également une interface Web-UI basée sur Gradio et une richesse de meilleures pratiques.
Pourquoi choisir MS-SWIFT?
--infer_backend vllm/lmdeploy .Pour installer en utilisant PIP:
pip install ms-swift -UPour installer à partir de la source:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . 10 minutes de réglage fin d'auto-cobine de QWEN2.5-7B-INSTRUCTION sur un seul GPU 3090:
# 22GB
CUDA_VISIBLE_DEVICES=0
swift sft
--model Qwen/Qwen2.5-7B-Instruct
--train_type lora
--dataset ' AI-ModelScope/alpaca-gpt4-data-zh#500 '
' AI-ModelScope/alpaca-gpt4-data-en#500 '
' swift/self-cognition#500 '
--torch_dtype bfloat16
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--learning_rate 1e-4
--lora_rank 8
--lora_alpha 32
--target_modules all-linear
--gradient_accumulation_steps 16
--eval_steps 50
--save_steps 50
--save_total_limit 2
--logging_steps 5
--max_length 2048
--output_dir output
--system ' You are a helpful assistant. '
--warmup_ratio 0.05
--dataloader_num_workers 4
--model_author swift
--model_name swift-robot Une fois l'entraînement terminé, utilisez la commande suivante pour effectuer l'inférence avec les poids formés. L'option --adapters doit être remplacée par le dernier dossier de point de contrôle généré à partir de la formation. Étant donné que le dossier des adaptateurs contient les fichiers de paramètres à partir de la formation, il n'est pas nécessaire de spécifier --model ou --system séparément.
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--temperature 0
--max_new_tokens 2048
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--merge_lora true
--infer_backend vllm
--max_model_len 8192
--temperature 0
--max_new_tokens 2048Le Web-UI est une solution d'interface de formation et de déploiement zéro basée basée sur la technologie d'interface Gradio. Pour plus de détails, vous pouvez vérifier ici.
SWIFT_UI_LANG=en swift web-ui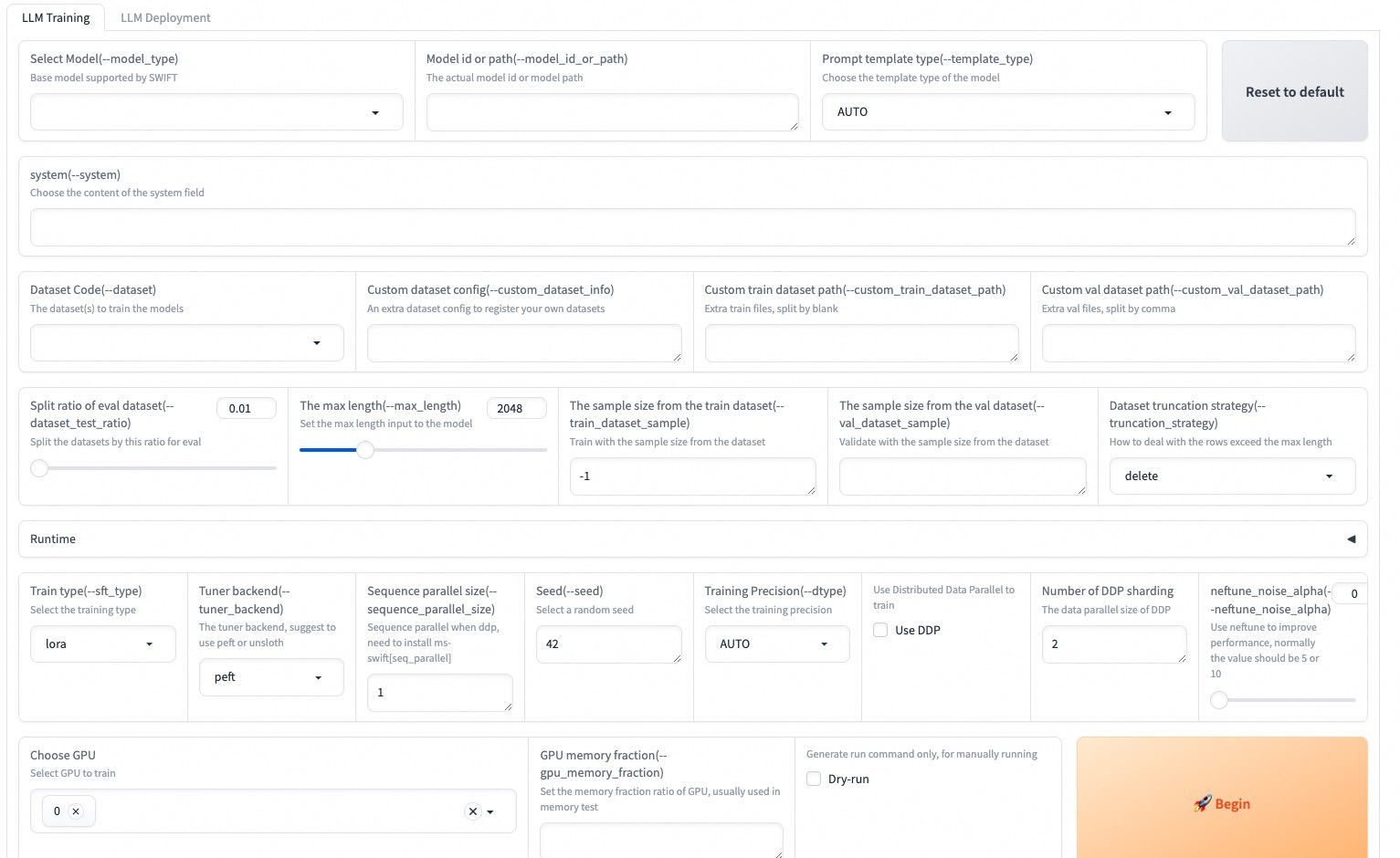
MS-SWIFT prend également en charge la formation et l'inférence à l'aide de Python. Vous trouverez ci-dessous le pseudocode pour la formation et l'inférence. Pour plus de détails, vous pouvez vous référer ici.
Entraînement:
# Retrieve the model and template, and add a trainable LoRA module
model , tokenizer = get_model_tokenizer ( model_id_or_path , ...)
template = get_template ( model . model_meta . template , tokenizer , ...)
model = Swift . prepare_model ( model , lora_config )
# Download and load the dataset, and encode the text into tokens
train_dataset , val_dataset = load_dataset ( dataset_id_or_path , ...)
train_dataset = EncodePreprocessor ( template = template )( train_dataset , num_proc = num_proc )
val_dataset = EncodePreprocessor ( template = template )( val_dataset , num_proc = num_proc )
# Train the model
trainer = Seq2SeqTrainer (
model = model ,
args = training_args ,
data_collator = template . data_collator ,
train_dataset = train_dataset ,
eval_dataset = val_dataset ,
template = template ,
)
trainer . train ()Inférence:
# Perform inference using the native PyTorch engine
engine = PtEngine ( model_id_or_path , adapters = [ lora_checkpoint ])
infer_request = InferRequest ( messages = [{ 'role' : 'user' , 'content' : 'who are you?' }])
request_config = RequestConfig ( max_tokens = max_new_tokens , temperature = temperature )
resp_list = engine . infer ([ infer_request ], request_config )
print ( f'response: { resp_list [ 0 ]. choices [ 0 ]. message . content } ' )Voici l'exemple le plus simple de formation au déploiement à l'aide de MS-SWIFT. Pour plus de détails, vous pouvez vérifier les exemples.
| Liens utiles |
|---|
| Paramètres de ligne de commande |
| Modèles et ensembles de données pris en charge |
| Modèles personnalisés, ensembles de données personnalisés |
| Tutoriel LLM |
Pré-formation:
# 8*A100
NPROC_PER_NODE=8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
swift pt
--model Qwen/Qwen2.5-7B
--dataset swift/chinese-c4
--streaming true
--train_type full
--deepspeed zero2
--output_dir output
--max_steps 100000
...Réglage fin:
CUDA_VISIBLE_DEVICES=0 swift sft
--model Qwen/Qwen2.5-7B-Instruct
--dataset AI-ModelScope/alpaca-gpt4-data-en
--train_type lora
--output_dir output
...RLHF:
CUDA_VISIBLE_DEVICES=0 swift rlhf
--rlhf_type dpo
--model Qwen/Qwen2.5-7B-Instruct
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji:en
--train_type lora
--output_dir output
...CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--stream true
--infer_backend pt
--max_new_tokens 2048
# LoRA
CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--adapters swift/test_lora
--stream true
--infer_backend pt
--temperature 0
--max_new_tokens 2048CUDA_VISIBLE_DEVICES=0 swift deploy
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend vllmCUDA_VISIBLE_DEVICES=0 swift eval
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend lmdeploy
--eval_dataset ARC_cCUDA_VISIBLE_DEVICES=0 swift export
--model Qwen/Qwen2.5-7B-Instruct
--quant_bits 4 --quant_method awq
--dataset AI-ModelScope/alpaca-gpt4-data-zh
--output_dir Qwen2.5-7B-Instruct-AWQCe cadre est sous licence Apache (version 2.0). Pour les modèles et ensembles de données, veuillez vous référer à la page de ressources d'origine et suivre la licence correspondante.
@misc { zhao2024swiftascalablelightweightinfrastructure ,
title = { SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning } ,
author = { Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen } ,
year = { 2024 } ,
eprint = { 2408.05517 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.05517 } ,
}

