ms swift
v3.0.0

Sitio web de ModelsCope Community
中文 | | Inglés
Documento | Documentación en inglés | 中文文档
Swift2.x en doc | swift2.x 中文文档
Puede contactarnos y comunicarse con nosotros agregando nuestro grupo:
| Grupo de discordias | Grupo de WeChat |
|---|---|
 |  |
? MS-Swift es un marco oficial proporcionado por la comunidad ModelsCope para ajustar e implementar modelos de idiomas grandes y modelos grandes multimodales. Actualmente es compatible con la capacitación (pre-entrenamiento, ajuste fino, alineación humana), inferencia, evaluación, cuantización y despliegue de más de 400 modelos grandes y más de 150 modelos grandes multimodales. Estos modelos de idiomas grandes (LLM) incluyen modelos como Qwen2.5, Llama3.3, GLM4, Internlm2.5, YI1.5, Mistral, Deepseek2.5, Baichuan2, Gemma2 y Telechat2. Los LLM multimodales incluyen modelos como QWEN2-VL, QWEN2-Audio, Llama3.2-Vision, Llava, Internvl2.5, MinicPM-V-2.6, GLM4V, XCOMPOSER2.5, YI-VL, Deepseek-VL2, PHI3.5-Vision y Got-OocR2.
? Además, MS-Swift reúne las últimas tecnologías de entrenamiento, incluidas Lora, Qlora, Llama-Pro, Longlora, Galore, Q-Galore, Lora+, Lisa, Dora, Fourierft, Reft, Unsloth y Liger. MS-Swift admite la aceleración de la inferencia, la evaluación y los módulos de implementación utilizando VLLM y LMDeploy, y admite la cuantificación de grandes modelos y grandes modelos multimodales utilizando tecnologías como GPTQ, AWQ y BNB. Para ayudar a los investigadores y desarrolladores a ajustar y aplicar modelos grandes más fácilmente, MS-Swift también proporciona una interfaz Web-UI basada en Grupo y una gran cantidad de mejores prácticas.
¿Por qué elegir MS-Swift?
--infer_backend vllm/lmdeploy .Para instalar con PIP:
pip install ms-swift -UPara instalar desde la fuente:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . 10 minutos de autoconía de ajuste de qwen2.5-7b-instructo en un solo 3090 GPU:
# 22GB
CUDA_VISIBLE_DEVICES=0
swift sft
--model Qwen/Qwen2.5-7B-Instruct
--train_type lora
--dataset ' AI-ModelScope/alpaca-gpt4-data-zh#500 '
' AI-ModelScope/alpaca-gpt4-data-en#500 '
' swift/self-cognition#500 '
--torch_dtype bfloat16
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--learning_rate 1e-4
--lora_rank 8
--lora_alpha 32
--target_modules all-linear
--gradient_accumulation_steps 16
--eval_steps 50
--save_steps 50
--save_total_limit 2
--logging_steps 5
--max_length 2048
--output_dir output
--system ' You are a helpful assistant. '
--warmup_ratio 0.05
--dataloader_num_workers 4
--model_author swift
--model_name swift-robot Después de que se complete el entrenamiento, use el siguiente comando para realizar una inferencia con los pesos entrenados. La opción --adapters debe reemplazarse con la última carpeta de punto de control generada a partir del entrenamiento. Dado que la carpeta de adaptadores contiene los archivos de parámetros de la capacitación, no es necesario especificar --model o --system por separado.
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--temperature 0
--max_new_tokens 2048
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--merge_lora true
--infer_backend vllm
--max_model_len 8192
--temperature 0
--max_new_tokens 2048El Web-UI es una solución de interfaz de capacitación e implementación de umbral cero basada en la tecnología de interfaz de Gradio. Para más detalles, puede consultar aquí.
SWIFT_UI_LANG=en swift web-ui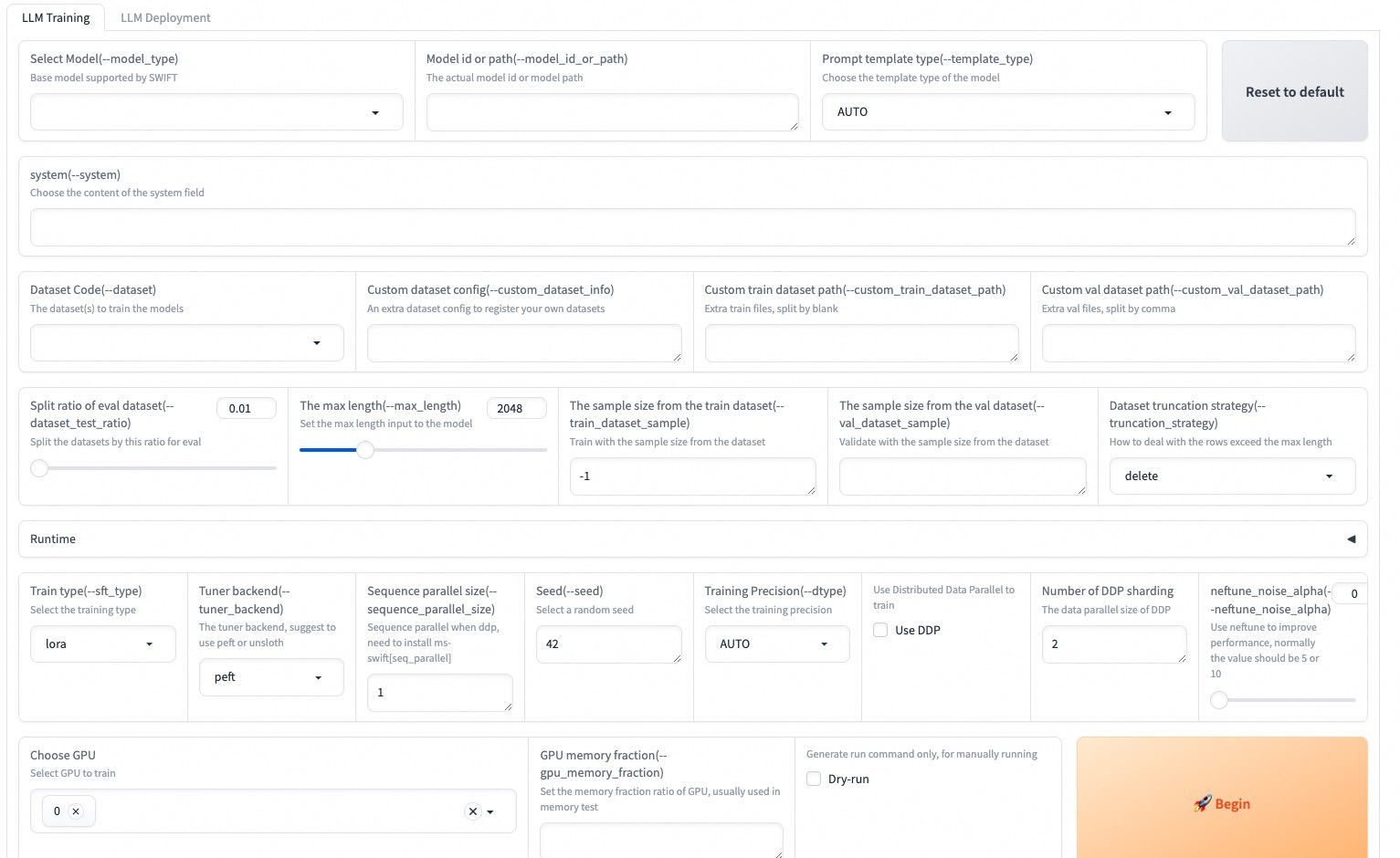
MS-Swift también admite capacitación e inferencia utilizando Python. A continuación se muestra el pseudocódigo para el entrenamiento y la inferencia. Para más detalles, puede consultar aquí.
Capacitación:
# Retrieve the model and template, and add a trainable LoRA module
model , tokenizer = get_model_tokenizer ( model_id_or_path , ...)
template = get_template ( model . model_meta . template , tokenizer , ...)
model = Swift . prepare_model ( model , lora_config )
# Download and load the dataset, and encode the text into tokens
train_dataset , val_dataset = load_dataset ( dataset_id_or_path , ...)
train_dataset = EncodePreprocessor ( template = template )( train_dataset , num_proc = num_proc )
val_dataset = EncodePreprocessor ( template = template )( val_dataset , num_proc = num_proc )
# Train the model
trainer = Seq2SeqTrainer (
model = model ,
args = training_args ,
data_collator = template . data_collator ,
train_dataset = train_dataset ,
eval_dataset = val_dataset ,
template = template ,
)
trainer . train ()Inferencia:
# Perform inference using the native PyTorch engine
engine = PtEngine ( model_id_or_path , adapters = [ lora_checkpoint ])
infer_request = InferRequest ( messages = [{ 'role' : 'user' , 'content' : 'who are you?' }])
request_config = RequestConfig ( max_tokens = max_new_tokens , temperature = temperature )
resp_list = engine . infer ([ infer_request ], request_config )
print ( f'response: { resp_list [ 0 ]. choices [ 0 ]. message . content } ' )Aquí está el ejemplo más simple de capacitación para implementar utilizando MS-Swift. Para más detalles, puede verificar los ejemplos.
| Enlaces útiles |
|---|
| Parámetros de línea de comando |
| Modelos y conjuntos de datos compatibles |
| Modelos personalizados, conjuntos de datos personalizados |
| Tutorial de LLM |
Pretruado:
# 8*A100
NPROC_PER_NODE=8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
swift pt
--model Qwen/Qwen2.5-7B
--dataset swift/chinese-c4
--streaming true
--train_type full
--deepspeed zero2
--output_dir output
--max_steps 100000
...Sintonia FINA:
CUDA_VISIBLE_DEVICES=0 swift sft
--model Qwen/Qwen2.5-7B-Instruct
--dataset AI-ModelScope/alpaca-gpt4-data-en
--train_type lora
--output_dir output
...RLHF:
CUDA_VISIBLE_DEVICES=0 swift rlhf
--rlhf_type dpo
--model Qwen/Qwen2.5-7B-Instruct
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji:en
--train_type lora
--output_dir output
...CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--stream true
--infer_backend pt
--max_new_tokens 2048
# LoRA
CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--adapters swift/test_lora
--stream true
--infer_backend pt
--temperature 0
--max_new_tokens 2048CUDA_VISIBLE_DEVICES=0 swift deploy
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend vllmCUDA_VISIBLE_DEVICES=0 swift eval
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend lmdeploy
--eval_dataset ARC_cCUDA_VISIBLE_DEVICES=0 swift export
--model Qwen/Qwen2.5-7B-Instruct
--quant_bits 4 --quant_method awq
--dataset AI-ModelScope/alpaca-gpt4-data-zh
--output_dir Qwen2.5-7B-Instruct-AWQEste marco tiene licencia bajo la licencia Apache (versión 2.0). Para modelos y conjuntos de datos, consulte la página de recursos original y siga la licencia correspondiente.
@misc { zhao2024swiftascalablelightweightinfrastructure ,
title = { SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning } ,
author = { Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen } ,
year = { 2024 } ,
eprint = { 2408.05517 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.05517 } ,
}

