ms swift
v3.0.0

Situs Web Komunitas Modelscope
中文 | Bahasa Inggris
Kertas | Dokumentasi Bahasa Inggris | 中文文档
Swift2.x en doc | swift2.x 中文文档
Anda dapat menghubungi kami dan berkomunikasi dengan kami dengan menambahkan grup kami:
| Grup Perselisihan | Grup WeChat |
|---|---|
 |  |
? MS-Swift adalah kerangka kerja resmi yang disediakan oleh komunitas Modelscope untuk menyempurnakan dan menggunakan model bahasa besar dan model besar multi-modal. Saat ini mendukung pelatihan (pra-pelatihan, penyesuaian, penyelarasan manusia), inferensi, evaluasi, kuantisasi, dan penyebaran 400+ model besar dan 150+ model besar multi-modal. Model bahasa besar ini (LLM) termasuk model seperti QWEN2.5, LLAMA3.3, GLM4, Internlm2.5, Yi1.5, Mistral, Deepseek2.5, Baichuan2, Gemma2, dan Telechat2. The multi-modal LLMs include models such as Qwen2-VL, Qwen2-Audio, Llama3.2-Vision, Llava, InternVL2.5, MiniCPM-V-2.6, GLM4v, Xcomposer2.5, Yi-VL, DeepSeek-VL2, Phi3.5-Vision, and GOT-OCR2.
? Selain itu, MS-Swift mengumpulkan teknologi pelatihan terbaru, termasuk Lora, Qlora, Llama-Pro, Longlora, Galore, Q-Galore, Lora+, Lisa, Dora, Fourierft, Reft, Unsloth, dan Liger. MS-Swift mendukung percepatan modul inferensi, evaluasi, dan penyebaran menggunakan VLLM dan LMDeploy, dan mendukung kuantisasi model besar dan model multi-modal menggunakan teknologi seperti GPTQ, AWQ, dan BNB. Untuk membantu para peneliti dan pengembang menyempurnakan dan menerapkan model besar dengan lebih mudah, MS-Swift juga menyediakan antarmuka Web-UI berbasis gradio dan banyak praktik terbaik.
Mengapa Memilih MS-Swift?
--infer_backend vllm/lmdeploy .Untuk menginstal menggunakan pip:
pip install ms-swift -UUntuk menginstal dari sumber:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . 10 menit penyempurnaan kognisi mandiri QWEN2.5-7B-instruksi pada satu 3090 GPU:
# 22GB
CUDA_VISIBLE_DEVICES=0
swift sft
--model Qwen/Qwen2.5-7B-Instruct
--train_type lora
--dataset ' AI-ModelScope/alpaca-gpt4-data-zh#500 '
' AI-ModelScope/alpaca-gpt4-data-en#500 '
' swift/self-cognition#500 '
--torch_dtype bfloat16
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--learning_rate 1e-4
--lora_rank 8
--lora_alpha 32
--target_modules all-linear
--gradient_accumulation_steps 16
--eval_steps 50
--save_steps 50
--save_total_limit 2
--logging_steps 5
--max_length 2048
--output_dir output
--system ' You are a helpful assistant. '
--warmup_ratio 0.05
--dataloader_num_workers 4
--model_author swift
--model_name swift-robot Setelah pelatihan selesai, gunakan perintah berikut untuk melakukan inferensi dengan bobot terlatih. Opsi --adapters harus diganti dengan folder pos pemeriksaan terakhir yang dihasilkan dari pelatihan. Karena folder adapter berisi file parameter dari pelatihan, tidak perlu menentukan --model atau --system secara terpisah.
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--temperature 0
--max_new_tokens 2048
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--merge_lora true
--infer_backend vllm
--max_model_len 8192
--temperature 0
--max_new_tokens 2048Web-UI adalah solusi antarmuka pelatihan dan penyebaran nol berdasarkan teknologi antarmuka gradio. Untuk detail lebih lanjut, Anda dapat memeriksa di sini.
SWIFT_UI_LANG=en swift web-ui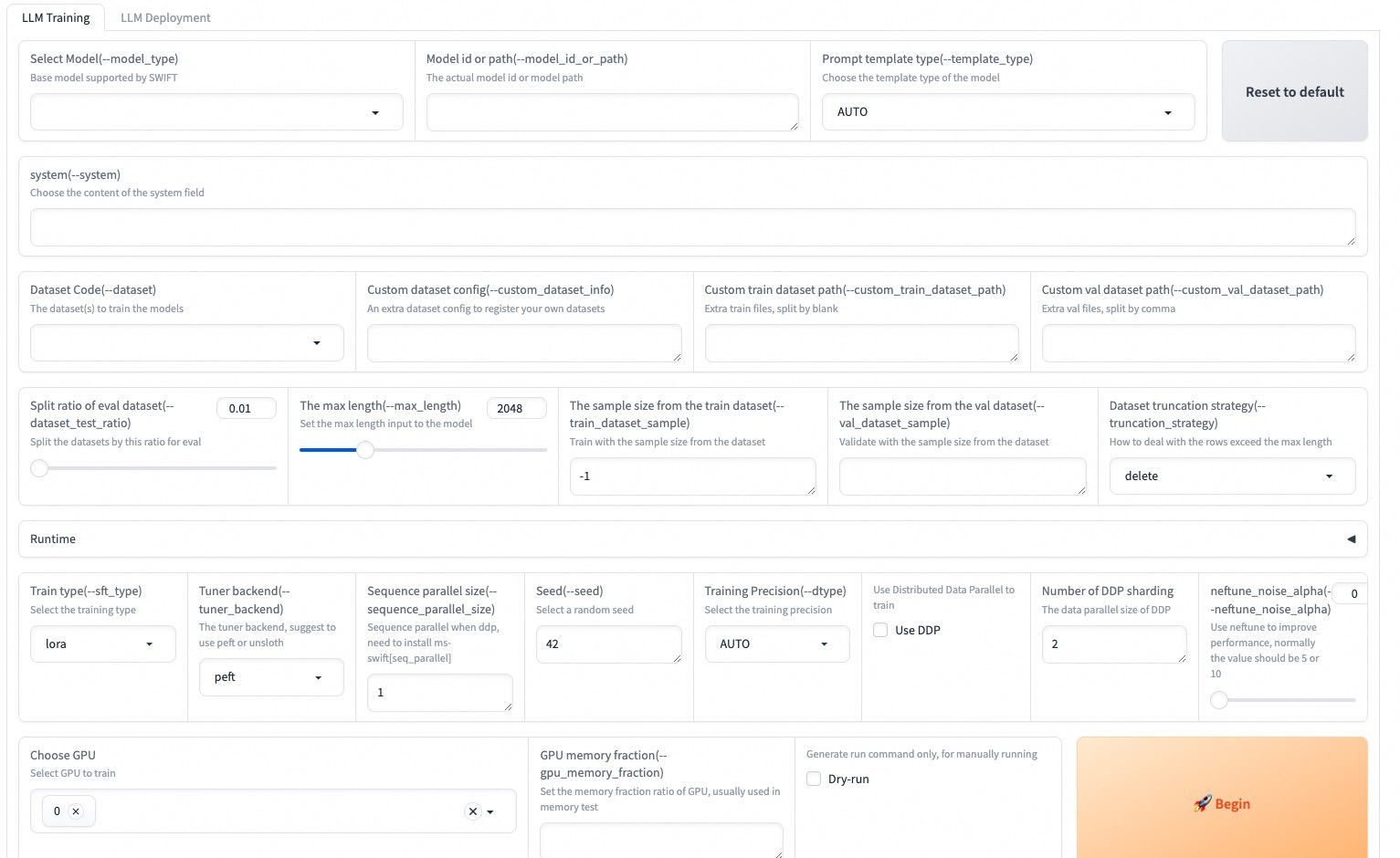
MS-Swift juga mendukung pelatihan dan inferensi menggunakan Python. Di bawah ini adalah pseudocode untuk pelatihan dan inferensi. Untuk detail lebih lanjut, Anda dapat merujuk di sini.
Pelatihan:
# Retrieve the model and template, and add a trainable LoRA module
model , tokenizer = get_model_tokenizer ( model_id_or_path , ...)
template = get_template ( model . model_meta . template , tokenizer , ...)
model = Swift . prepare_model ( model , lora_config )
# Download and load the dataset, and encode the text into tokens
train_dataset , val_dataset = load_dataset ( dataset_id_or_path , ...)
train_dataset = EncodePreprocessor ( template = template )( train_dataset , num_proc = num_proc )
val_dataset = EncodePreprocessor ( template = template )( val_dataset , num_proc = num_proc )
# Train the model
trainer = Seq2SeqTrainer (
model = model ,
args = training_args ,
data_collator = template . data_collator ,
train_dataset = train_dataset ,
eval_dataset = val_dataset ,
template = template ,
)
trainer . train ()Kesimpulan:
# Perform inference using the native PyTorch engine
engine = PtEngine ( model_id_or_path , adapters = [ lora_checkpoint ])
infer_request = InferRequest ( messages = [{ 'role' : 'user' , 'content' : 'who are you?' }])
request_config = RequestConfig ( max_tokens = max_new_tokens , temperature = temperature )
resp_list = engine . infer ([ infer_request ], request_config )
print ( f'response: { resp_list [ 0 ]. choices [ 0 ]. message . content } ' )Berikut adalah contoh paling sederhana dari pelatihan untuk ditempatkan menggunakan MS-Swift. Untuk detail lebih lanjut, Anda dapat memeriksa contohnya.
| Tautan yang berguna |
|---|
| Parameter baris perintah |
| Model dan Dataset yang Didukung |
| Model khusus, kumpulan data khusus |
| Tutorial llm |
Pra-Pelatihan:
# 8*A100
NPROC_PER_NODE=8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
swift pt
--model Qwen/Qwen2.5-7B
--dataset swift/chinese-c4
--streaming true
--train_type full
--deepspeed zero2
--output_dir output
--max_steps 100000
...Fine-tuning:
CUDA_VISIBLE_DEVICES=0 swift sft
--model Qwen/Qwen2.5-7B-Instruct
--dataset AI-ModelScope/alpaca-gpt4-data-en
--train_type lora
--output_dir output
...RLHF:
CUDA_VISIBLE_DEVICES=0 swift rlhf
--rlhf_type dpo
--model Qwen/Qwen2.5-7B-Instruct
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji:en
--train_type lora
--output_dir output
...CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--stream true
--infer_backend pt
--max_new_tokens 2048
# LoRA
CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--adapters swift/test_lora
--stream true
--infer_backend pt
--temperature 0
--max_new_tokens 2048CUDA_VISIBLE_DEVICES=0 swift deploy
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend vllmCUDA_VISIBLE_DEVICES=0 swift eval
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend lmdeploy
--eval_dataset ARC_cCUDA_VISIBLE_DEVICES=0 swift export
--model Qwen/Qwen2.5-7B-Instruct
--quant_bits 4 --quant_method awq
--dataset AI-ModelScope/alpaca-gpt4-data-zh
--output_dir Qwen2.5-7B-Instruct-AWQKerangka kerja ini dilisensikan di bawah lisensi Apache (versi 2.0). Untuk model dan kumpulan data, silakan merujuk ke halaman sumber daya asli dan ikuti lisensi yang sesuai.
@misc { zhao2024swiftascalablelightweightinfrastructure ,
title = { SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning } ,
author = { Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen } ,
year = { 2024 } ,
eprint = { 2408.05517 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.05517 } ,
}

