ms swift
v3.0.0

Site da comunidade Modelscope
中文 | Inglês
Papel | Documentação em inglês | 中文文档
Swift2.x en doc | swift2.x 中文文档
Você pode entrar em contato conosco e se comunicar conosco adicionando nosso grupo:
| Grupo de discórdios | Grupo WeChat |
|---|---|
 |  |
? O MS-SWIFT é uma estrutura oficial fornecida pela comunidade ModelCope para ajustar e implantar grandes modelos de idiomas e modelos grandes multimodais. Atualmente, ele suporta o treinamento (pré-treinamento, ajuste fino, alinhamento humano), inferência, avaliação, quantização e implantação de mais de 400 modelos grandes e mais de 150 modelos grandes multimodais. Esses grandes modelos de linguagem (LLMs) incluem modelos como QWEN2.5, LLAMA3.3, GLM4, INTERNLM2.5, YI1.5, Mistral, Deepseek2.5, Baichuan2, Gemma2 e Telechat2. Os LLMs multimodais incluem modelos como QWEN2-VL, QWEN2-AUDIO, LLAMA3.2-VISION, LLAVA, INTERNVL2.5, MINICPM-V-2.6, GLM4V, XCOMPOSER2.5, YI-VL, Deepseek-VL2, Phi3.5-Vision e Get-Dish e GOT-ALT-ALG.
? Além disso, o MS-SWIFT reúne as mais recentes tecnologias de treinamento, incluindo Lora, Qlora, Llama-Pro, Longlora, Galore, Q-Galore, Lora+, Lisa, Dora, Fourierft, Reft, Unsloth e Liger. O MS-SWIFT suporta a aceleração dos módulos de inferência, avaliação e implantação usando VLLM e LMDeploy e suporta a quantização de grandes modelos e modelos grandes multimodais usando tecnologias como GPTQ, AWQ e BNB. Para ajudar pesquisadores e desenvolvedores a ajustar e aplicar grandes modelos com mais facilidade, o MS-SWIFT também fornece uma interface Web-UI baseada em graduação e uma riqueza de melhores práticas.
Por que escolher o ms-swift?
--infer_backend vllm/lmdeploy .Para instalar usando PIP:
pip install ms-swift -UPara instalar da fonte:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . 10 minutos de ajuste fino de autoconhas de QWEN2.5-7B-INUSTRUTA em uma única GPU 3090:
# 22GB
CUDA_VISIBLE_DEVICES=0
swift sft
--model Qwen/Qwen2.5-7B-Instruct
--train_type lora
--dataset ' AI-ModelScope/alpaca-gpt4-data-zh#500 '
' AI-ModelScope/alpaca-gpt4-data-en#500 '
' swift/self-cognition#500 '
--torch_dtype bfloat16
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--learning_rate 1e-4
--lora_rank 8
--lora_alpha 32
--target_modules all-linear
--gradient_accumulation_steps 16
--eval_steps 50
--save_steps 50
--save_total_limit 2
--logging_steps 5
--max_length 2048
--output_dir output
--system ' You are a helpful assistant. '
--warmup_ratio 0.05
--dataloader_num_workers 4
--model_author swift
--model_name swift-robot Após a conclusão do treinamento, use o seguinte comando para realizar inferência com os pesos treinados. A opção --adapters deve ser substituída pela última pasta de ponto de verificação gerada a partir do treinamento. Como a pasta adaptadores contém os arquivos de parâmetro do treinamento, não há necessidade de especificar --model ou --system separadamente.
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--temperature 0
--max_new_tokens 2048
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--merge_lora true
--infer_backend vllm
--max_model_len 8192
--temperature 0
--max_new_tokens 2048O Web-UI é uma solução de interface de treinamento e implantação de limiar zero com base na tecnologia de interface gradio. Para mais detalhes, você pode verificar aqui.
SWIFT_UI_LANG=en swift web-ui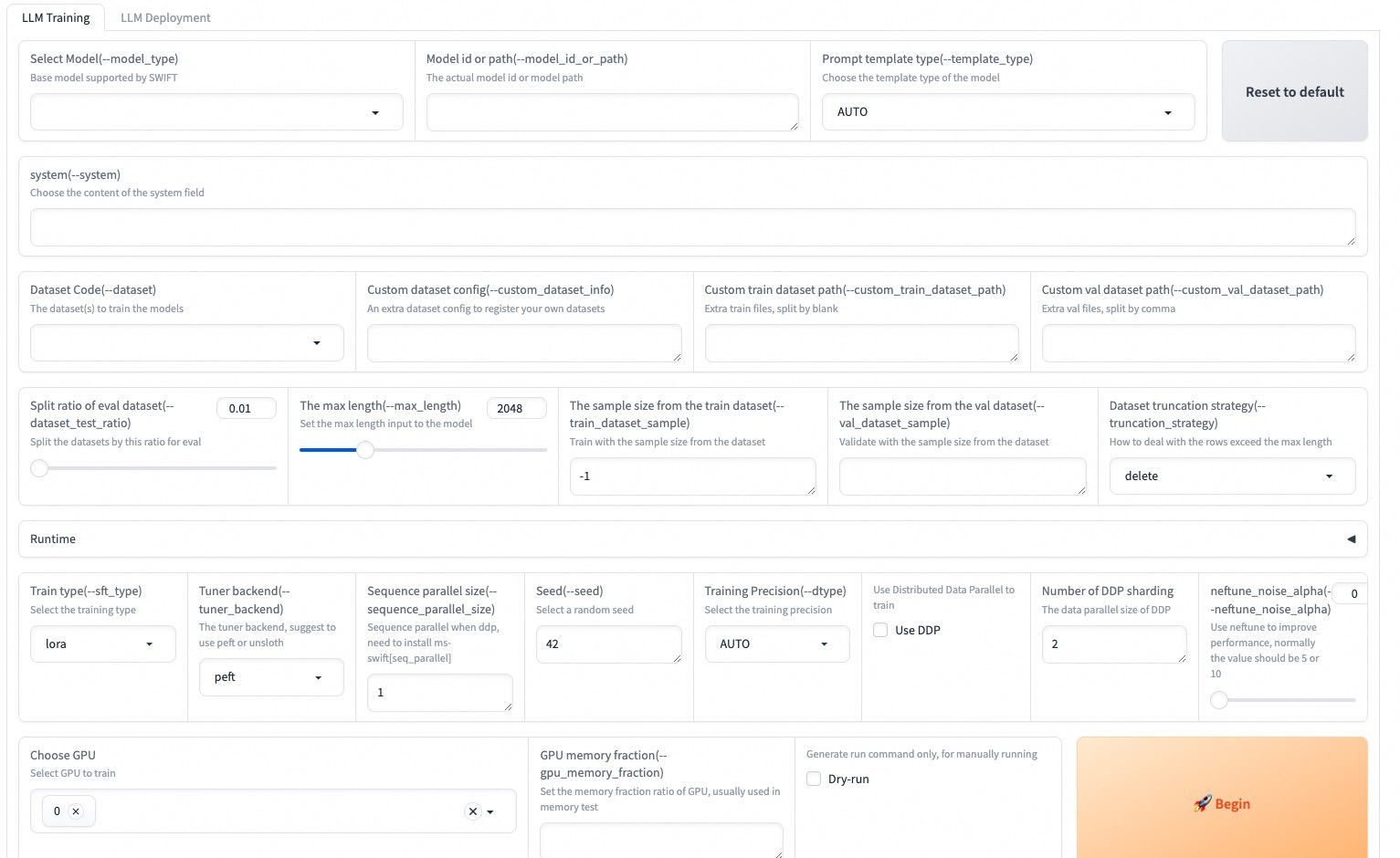
O MS-SWIFT também suporta treinamento e inferência usando Python. Abaixo está o pseudocódigo para treinamento e inferência. Para mais detalhes, você pode se referir aqui.
Treinamento:
# Retrieve the model and template, and add a trainable LoRA module
model , tokenizer = get_model_tokenizer ( model_id_or_path , ...)
template = get_template ( model . model_meta . template , tokenizer , ...)
model = Swift . prepare_model ( model , lora_config )
# Download and load the dataset, and encode the text into tokens
train_dataset , val_dataset = load_dataset ( dataset_id_or_path , ...)
train_dataset = EncodePreprocessor ( template = template )( train_dataset , num_proc = num_proc )
val_dataset = EncodePreprocessor ( template = template )( val_dataset , num_proc = num_proc )
# Train the model
trainer = Seq2SeqTrainer (
model = model ,
args = training_args ,
data_collator = template . data_collator ,
train_dataset = train_dataset ,
eval_dataset = val_dataset ,
template = template ,
)
trainer . train ()Inferência:
# Perform inference using the native PyTorch engine
engine = PtEngine ( model_id_or_path , adapters = [ lora_checkpoint ])
infer_request = InferRequest ( messages = [{ 'role' : 'user' , 'content' : 'who are you?' }])
request_config = RequestConfig ( max_tokens = max_new_tokens , temperature = temperature )
resp_list = engine . infer ([ infer_request ], request_config )
print ( f'response: { resp_list [ 0 ]. choices [ 0 ]. message . content } ' )Aqui está o exemplo mais simples de treinamento para implantação usando o MS-SWIFT. Para mais detalhes, você pode verificar os exemplos.
| Links úteis |
|---|
| Parâmetros da linha de comando |
| Modelos e conjuntos de dados suportados |
| Modelos personalizados, conjuntos de dados personalizados |
| Tutorial LLM |
Pré-treinamento:
# 8*A100
NPROC_PER_NODE=8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
swift pt
--model Qwen/Qwen2.5-7B
--dataset swift/chinese-c4
--streaming true
--train_type full
--deepspeed zero2
--output_dir output
--max_steps 100000
...Afinação:
CUDA_VISIBLE_DEVICES=0 swift sft
--model Qwen/Qwen2.5-7B-Instruct
--dataset AI-ModelScope/alpaca-gpt4-data-en
--train_type lora
--output_dir output
...RlHf:
CUDA_VISIBLE_DEVICES=0 swift rlhf
--rlhf_type dpo
--model Qwen/Qwen2.5-7B-Instruct
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji:en
--train_type lora
--output_dir output
...CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--stream true
--infer_backend pt
--max_new_tokens 2048
# LoRA
CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--adapters swift/test_lora
--stream true
--infer_backend pt
--temperature 0
--max_new_tokens 2048CUDA_VISIBLE_DEVICES=0 swift deploy
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend vllmCUDA_VISIBLE_DEVICES=0 swift eval
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend lmdeploy
--eval_dataset ARC_cCUDA_VISIBLE_DEVICES=0 swift export
--model Qwen/Qwen2.5-7B-Instruct
--quant_bits 4 --quant_method awq
--dataset AI-ModelScope/alpaca-gpt4-data-zh
--output_dir Qwen2.5-7B-Instruct-AWQEssa estrutura é licenciada sob a licença Apache (versão 2.0). Para modelos e conjuntos de dados, consulte a página de recursos originais e siga a licença correspondente.
@misc { zhao2024swiftascalablelightweightinfrastructure ,
title = { SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning } ,
author = { Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen } ,
year = { 2024 } ,
eprint = { 2408.05517 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.05517 } ,
}

