ms swift
v3.0.0

موديلات مجتمع المجتمع
中文 | اللغة الإنجليزية
ورقة | الوثائق الإنجليزية | 中文文档
swift2.x en doc | swift2.x 中文文档
يمكنك الاتصال بنا والتواصل معنا بإضافة مجموعتنا:
| مجموعة الخلاف | مجموعة WeChat |
|---|---|
 |  |
؟ MS-SWIFT هو إطار رسمي يقدمه مجتمع ModelsCope لضبط ونشر نماذج لغة كبيرة ونماذج كبيرة متعددة الوسائط. وهي تدعم حاليًا التدريب (التدريب قبل التدريب ، والضبط ، والمواءمة البشرية) ، والاستدلال ، والتقييم ، والقياس ، ونشر 400 نموذج كبير و 150+ نماذج كبيرة متعددة الوسائط. تشمل هذه النماذج اللغوية الكبيرة (LLMS) نماذج مثل QWEN2.5 و LLAMA3.3 و GLM4 و Internlm2.5 و Yi1.5 و Mistral و Deepseek2.5 و Baichuan2 و Gemma2 و Telechat2. تتضمن LLMs متعددة الوسائط نماذج مثل QWEN2-VL و QWEN2-Audio و LLAMA3.2-Vision و LLAVA و Internvl2.5 و Minicpm-V-2.6 و GLM4V و XCOMPOSER2.5 و YI-VL و DEEPSEEK-VL2 و PHI3.5-RISION و GOT-ACR2.
؟ بالإضافة إلى ذلك ، تجمع MS-Swift أحدث تقنيات التدريب ، بما في ذلك Lora و Qlora و Llama-Pro و Longlora و Galore و Q-Galore و Lora+و Lisa و Dora و Fourierft و Reft و Unloth و Liger. تدعم MS-SWIFT تسريع وحدات الاستدلال والتقييم والنشر باستخدام VLLM و LMDEPLOY ، ويدعم تقدير النماذج الكبيرة والنماذج الكبيرة متعددة الوسائط باستخدام تقنيات مثل GPTQ و AWQ و BNB. لمساعدة الباحثين والمطورين على ضبط وتطبيق نماذج كبيرة بسهولة أكبر ، توفر MS-SWIFT أيضًا واجهة ويب على الويب المستندة إلى GRADIO وثروة من أفضل الممارسات.
لماذا تختار MS-SWIFT؟
--infer_backend vllm/lmdeploy .للتثبيت باستخدام PIP:
pip install ms-swift -Uللتثبيت من المصدر:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . 10 دقائق من الإدراك الذاتي للضبط من QWEN2.5-7b-instruct على وحدة معالجة الرسومات 3090 واحدة:
# 22GB
CUDA_VISIBLE_DEVICES=0
swift sft
--model Qwen/Qwen2.5-7B-Instruct
--train_type lora
--dataset ' AI-ModelScope/alpaca-gpt4-data-zh#500 '
' AI-ModelScope/alpaca-gpt4-data-en#500 '
' swift/self-cognition#500 '
--torch_dtype bfloat16
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--learning_rate 1e-4
--lora_rank 8
--lora_alpha 32
--target_modules all-linear
--gradient_accumulation_steps 16
--eval_steps 50
--save_steps 50
--save_total_limit 2
--logging_steps 5
--max_length 2048
--output_dir output
--system ' You are a helpful assistant. '
--warmup_ratio 0.05
--dataloader_num_workers 4
--model_author swift
--model_name swift-robot بعد اكتمال التدريب ، استخدم الأمر التالي لأداء الاستدلال مع الأوزان المدربة. يجب استبدال خيار --adapters بمجلد نقطة التفتيش الأخيرة التي تم إنشاؤها من التدريب. نظرًا لأن مجلد المحولات يحتوي على ملفات المعلمات من التدريب ، فليس هناك حاجة لتحديد --model أو --system بشكل منفصل.
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--temperature 0
--max_new_tokens 2048
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--merge_lora true
--infer_backend vllm
--max_model_len 8192
--temperature 0
--max_new_tokens 2048Web-UI هو حل واجهة التدريب والنشر على عتبة صفرية يعتمد على تقنية واجهة Gradio. لمزيد من التفاصيل ، يمكنك التحقق هنا.
SWIFT_UI_LANG=en swift web-ui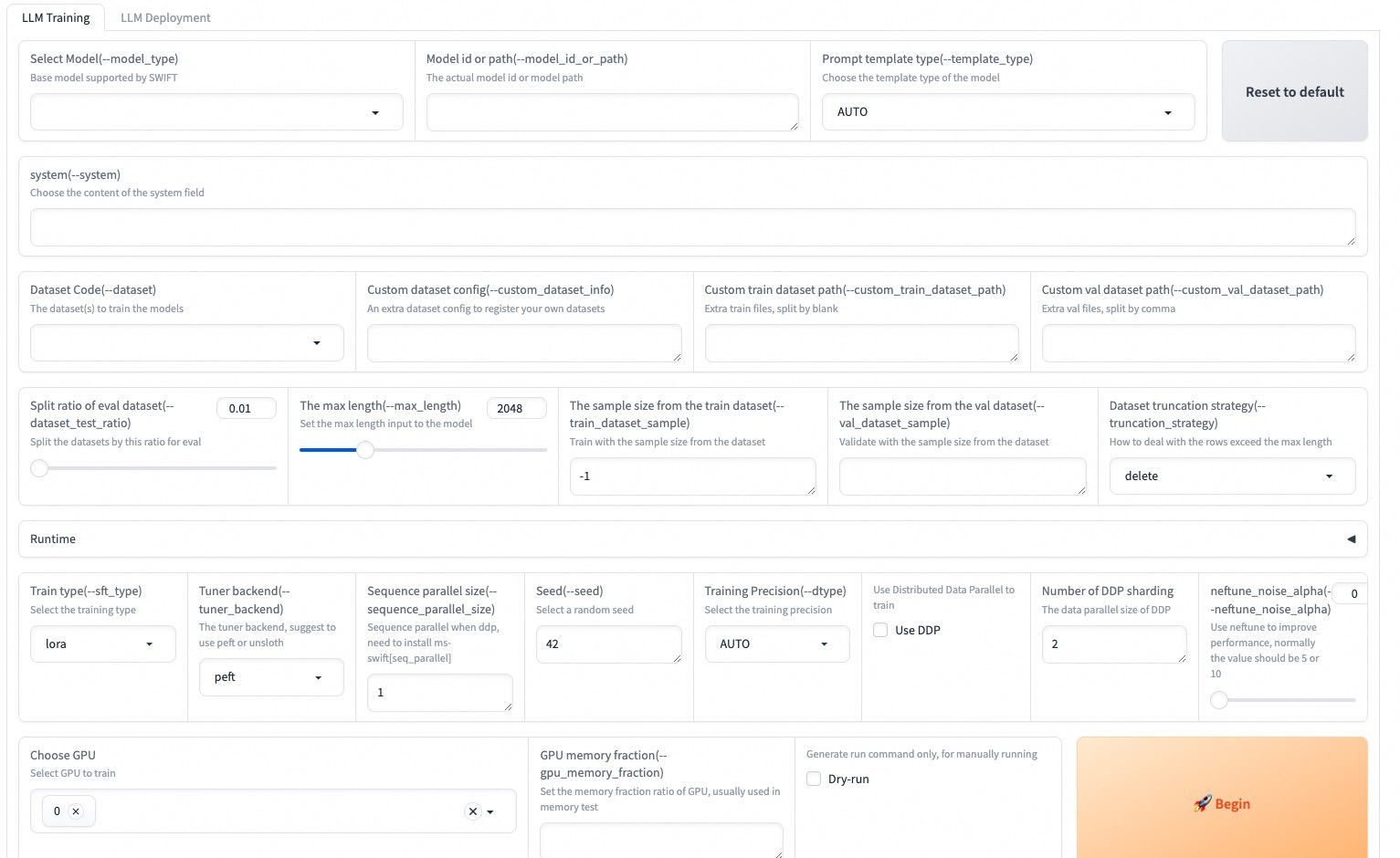
MS-SWIFT يدعم أيضًا التدريب والاستدلال باستخدام Python. فيما يلي رمز كاذب للتدريب والاستدلال. لمزيد من التفاصيل ، يمكنك الرجوع إلى هنا.
تمرين:
# Retrieve the model and template, and add a trainable LoRA module
model , tokenizer = get_model_tokenizer ( model_id_or_path , ...)
template = get_template ( model . model_meta . template , tokenizer , ...)
model = Swift . prepare_model ( model , lora_config )
# Download and load the dataset, and encode the text into tokens
train_dataset , val_dataset = load_dataset ( dataset_id_or_path , ...)
train_dataset = EncodePreprocessor ( template = template )( train_dataset , num_proc = num_proc )
val_dataset = EncodePreprocessor ( template = template )( val_dataset , num_proc = num_proc )
# Train the model
trainer = Seq2SeqTrainer (
model = model ,
args = training_args ,
data_collator = template . data_collator ,
train_dataset = train_dataset ,
eval_dataset = val_dataset ,
template = template ,
)
trainer . train ()الاستدلال:
# Perform inference using the native PyTorch engine
engine = PtEngine ( model_id_or_path , adapters = [ lora_checkpoint ])
infer_request = InferRequest ( messages = [{ 'role' : 'user' , 'content' : 'who are you?' }])
request_config = RequestConfig ( max_tokens = max_new_tokens , temperature = temperature )
resp_list = engine . infer ([ infer_request ], request_config )
print ( f'response: { resp_list [ 0 ]. choices [ 0 ]. message . content } ' )فيما يلي أبسط مثال على التدريب على النشر باستخدام MS-SWIFT. لمزيد من التفاصيل ، يمكنك التحقق من الأمثلة.
| روابط مفيدة |
|---|
| معلمات سطر الأوامر |
| النماذج ومجموعات البيانات المدعومة |
| نماذج مخصصة ، مجموعات بيانات مخصصة |
| LLM البرنامج التعليمي |
ما قبل التدريب:
# 8*A100
NPROC_PER_NODE=8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
swift pt
--model Qwen/Qwen2.5-7B
--dataset swift/chinese-c4
--streaming true
--train_type full
--deepspeed zero2
--output_dir output
--max_steps 100000
...الكون المثالى:
CUDA_VISIBLE_DEVICES=0 swift sft
--model Qwen/Qwen2.5-7B-Instruct
--dataset AI-ModelScope/alpaca-gpt4-data-en
--train_type lora
--output_dir output
...RLHF:
CUDA_VISIBLE_DEVICES=0 swift rlhf
--rlhf_type dpo
--model Qwen/Qwen2.5-7B-Instruct
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji:en
--train_type lora
--output_dir output
...CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--stream true
--infer_backend pt
--max_new_tokens 2048
# LoRA
CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--adapters swift/test_lora
--stream true
--infer_backend pt
--temperature 0
--max_new_tokens 2048CUDA_VISIBLE_DEVICES=0 swift deploy
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend vllmCUDA_VISIBLE_DEVICES=0 swift eval
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend lmdeploy
--eval_dataset ARC_cCUDA_VISIBLE_DEVICES=0 swift export
--model Qwen/Qwen2.5-7B-Instruct
--quant_bits 4 --quant_method awq
--dataset AI-ModelScope/alpaca-gpt4-data-zh
--output_dir Qwen2.5-7B-Instruct-AWQتم ترخيص هذا الإطار بموجب ترخيص Apache (الإصدار 2.0). بالنسبة للموديلات ومجموعات البيانات ، يرجى الرجوع إلى صفحة الموارد الأصلية واتباع الترخيص المقابل.
@misc { zhao2024swiftascalablelightweightinfrastructure ,
title = { SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning } ,
author = { Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen } ,
year = { 2024 } ,
eprint = { 2408.05517 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.05517 } ,
}

