ms swift
v3.0.0

เว็บไซต์ ModelsCope Community
中文ภาษาอังกฤษ
กระดาษ | เอกสารภาษาอังกฤษ | 中文文档
swift2.x en doc | swift2.x 中文文档
คุณสามารถติดต่อเราและสื่อสารกับเราได้โดยเพิ่มกลุ่มของเรา:
| กลุ่ม Discord | กลุ่ม WeChat |
|---|---|
 |  |
- MS-SWIFT เป็นกรอบการทำงานอย่างเป็นทางการที่จัดทำโดยชุมชน ModelsCope สำหรับการปรับแต่งและปรับใช้รูปแบบภาษาขนาดใหญ่และรุ่นขนาดใหญ่หลายรูปแบบ ปัจจุบันรองรับการฝึกอบรม (การฝึกอบรมก่อนการปรับแต่งการจัดตำแหน่งของมนุษย์) การอนุมานการประเมินผลการหาปริมาณและการปรับใช้โมเดลขนาดใหญ่ 400+ รุ่นและโมเดลขนาดใหญ่หลายรุ่น แบบจำลองภาษาขนาดใหญ่ (LLMS) เหล่านี้รวมถึงรุ่นเช่น QWEN2.5, LLAMA3.3, GLM4, InternLM2.5, Yi1.5, Mistral, Deepseek2.5, Baichuan2, Gemma2 และ Telechat2 LLM แบบหลายรูปแบบรวมถึงรุ่นเช่น QWEN2-VL, QWEN2-AUDIO, LLAMA3.2-Vision, LLAVA, InternVL2.5, MINICPM-V-2.6, GLM4V, XCOMPOSER2.5, YI-VL, DEEPSEEK-VL2, Phi3.5-Vision
- นอกจากนี้ MS-Swift ยังรวบรวมเทคโนโลยีการฝึกอบรมล่าสุด ได้แก่ Lora, Qlora, Llama-Pro, Longlora, Galore, Q-Galore, Lora+, Lisa, Dora, Fourierft, Reft, Unsloth และ Liger MS-Swift รองรับการเร่งความเร็วของการอนุมานการประเมินผลและโมดูลการปรับใช้โดยใช้ VLLM และ LMDEploy และรองรับการหาปริมาณของแบบจำลองขนาดใหญ่และโมเดลขนาดใหญ่หลายโมเดลโดยใช้เทคโนโลยีเช่น GPTQ, AWQ และ BNB เพื่อช่วยให้นักวิจัยและนักพัฒนาปรับแต่งและใช้โมเดลขนาดใหญ่ได้ง่ายขึ้น MS-Swift ยังให้อินเทอร์เฟซ Web-UI ที่ใช้ Gradio และแนวทางปฏิบัติที่ดีที่สุด
ทำไมต้องเลือก MS-Swift?
--infer_backend vllm/lmdeployในการติดตั้งโดยใช้ PIP:
pip install ms-swift -Uเพื่อติดตั้งจากแหล่งที่มา:
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . 10 นาทีของการปรับแต่งตนเองของ QWEN2.5-7B-Instruct ใน 3090 GPU เดียว:
# 22GB
CUDA_VISIBLE_DEVICES=0
swift sft
--model Qwen/Qwen2.5-7B-Instruct
--train_type lora
--dataset ' AI-ModelScope/alpaca-gpt4-data-zh#500 '
' AI-ModelScope/alpaca-gpt4-data-en#500 '
' swift/self-cognition#500 '
--torch_dtype bfloat16
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--learning_rate 1e-4
--lora_rank 8
--lora_alpha 32
--target_modules all-linear
--gradient_accumulation_steps 16
--eval_steps 50
--save_steps 50
--save_total_limit 2
--logging_steps 5
--max_length 2048
--output_dir output
--system ' You are a helpful assistant. '
--warmup_ratio 0.05
--dataloader_num_workers 4
--model_author swift
--model_name swift-robot หลังจากการฝึกอบรมเสร็จสมบูรณ์ให้ใช้คำสั่งต่อไปนี้เพื่อทำการอนุมานกับน้ำหนักที่ผ่านการฝึกอบรม ตัวเลือก --adapters ควรถูกแทนที่ด้วยโฟลเดอร์จุดตรวจสอบล่าสุดที่สร้างขึ้นจากการฝึกอบรม เนื่องจากโฟลเดอร์อะแดปเตอร์มีไฟล์พารามิเตอร์จากการฝึกอบรมจึงไม่จำเป็นต้องระบุ --model หรือ --system แยกต่างหาก
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--temperature 0
--max_new_tokens 2048
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0
swift infer
--adapters output/vx-xxx/checkpoint-xxx
--stream true
--merge_lora true
--infer_backend vllm
--max_model_len 8192
--temperature 0
--max_new_tokens 2048Web-UI เป็นโซลูชันการฝึกอบรมและการปรับใช้ส่วนต่อประสานที่ ไม่มีผล ตามเทคโนโลยี สำหรับรายละเอียดเพิ่มเติมคุณสามารถตรวจสอบได้ที่นี่
SWIFT_UI_LANG=en swift web-ui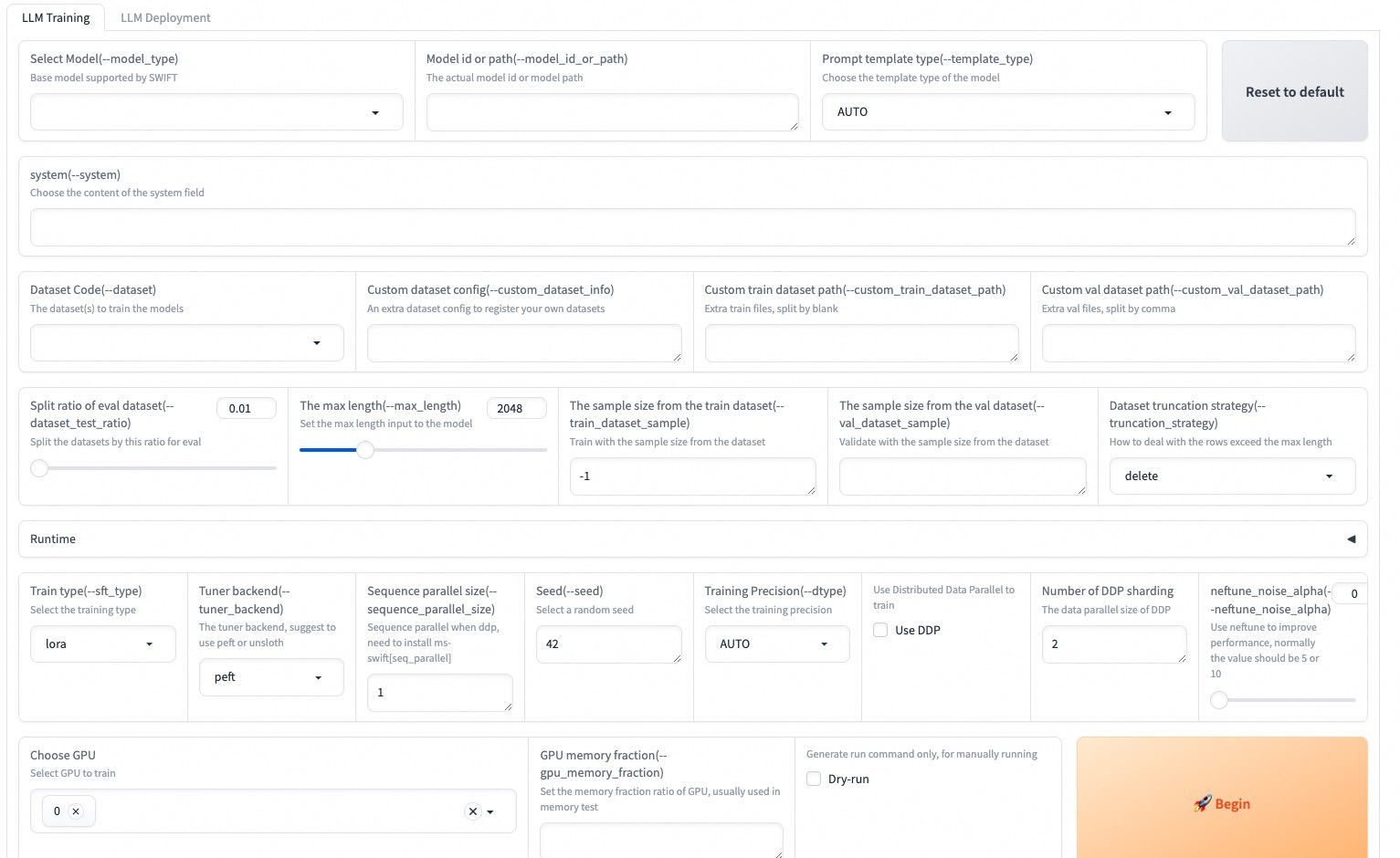
MS-Swift ยังสนับสนุนการฝึกอบรมและการอนุมานโดยใช้ Python ด้านล่างนี้เป็น pseudocode สำหรับการฝึกอบรมและการอนุมาน สำหรับรายละเอียดเพิ่มเติมคุณสามารถอ้างถึงที่นี่
การฝึกอบรม:
# Retrieve the model and template, and add a trainable LoRA module
model , tokenizer = get_model_tokenizer ( model_id_or_path , ...)
template = get_template ( model . model_meta . template , tokenizer , ...)
model = Swift . prepare_model ( model , lora_config )
# Download and load the dataset, and encode the text into tokens
train_dataset , val_dataset = load_dataset ( dataset_id_or_path , ...)
train_dataset = EncodePreprocessor ( template = template )( train_dataset , num_proc = num_proc )
val_dataset = EncodePreprocessor ( template = template )( val_dataset , num_proc = num_proc )
# Train the model
trainer = Seq2SeqTrainer (
model = model ,
args = training_args ,
data_collator = template . data_collator ,
train_dataset = train_dataset ,
eval_dataset = val_dataset ,
template = template ,
)
trainer . train ()การอนุมาน:
# Perform inference using the native PyTorch engine
engine = PtEngine ( model_id_or_path , adapters = [ lora_checkpoint ])
infer_request = InferRequest ( messages = [{ 'role' : 'user' , 'content' : 'who are you?' }])
request_config = RequestConfig ( max_tokens = max_new_tokens , temperature = temperature )
resp_list = engine . infer ([ infer_request ], request_config )
print ( f'response: { resp_list [ 0 ]. choices [ 0 ]. message . content } ' )นี่คือตัวอย่างที่ง่ายที่สุดของการฝึกอบรมเพื่อการปรับใช้โดยใช้ MS-Swift สำหรับรายละเอียดเพิ่มเติมคุณสามารถตรวจสอบตัวอย่าง
| ลิงค์ที่มีประโยชน์ |
|---|
| พารามิเตอร์บรรทัดคำสั่ง |
| รุ่นที่รองรับและชุดข้อมูล |
| โมเดลที่กำหนดเองชุดข้อมูลที่กำหนดเอง |
| การสอน LLM |
การฝึกอบรมล่วงหน้า:
# 8*A100
NPROC_PER_NODE=8
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
swift pt
--model Qwen/Qwen2.5-7B
--dataset swift/chinese-c4
--streaming true
--train_type full
--deepspeed zero2
--output_dir output
--max_steps 100000
...ปรับแต่ง:
CUDA_VISIBLE_DEVICES=0 swift sft
--model Qwen/Qwen2.5-7B-Instruct
--dataset AI-ModelScope/alpaca-gpt4-data-en
--train_type lora
--output_dir output
...RLHF:
CUDA_VISIBLE_DEVICES=0 swift rlhf
--rlhf_type dpo
--model Qwen/Qwen2.5-7B-Instruct
--dataset hjh0119/shareAI-Llama3-DPO-zh-en-emoji:en
--train_type lora
--output_dir output
...CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--stream true
--infer_backend pt
--max_new_tokens 2048
# LoRA
CUDA_VISIBLE_DEVICES=0 swift infer
--model Qwen/Qwen2.5-7B-Instruct
--adapters swift/test_lora
--stream true
--infer_backend pt
--temperature 0
--max_new_tokens 2048CUDA_VISIBLE_DEVICES=0 swift deploy
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend vllmCUDA_VISIBLE_DEVICES=0 swift eval
--model Qwen/Qwen2.5-7B-Instruct
--infer_backend lmdeploy
--eval_dataset ARC_cCUDA_VISIBLE_DEVICES=0 swift export
--model Qwen/Qwen2.5-7B-Instruct
--quant_bits 4 --quant_method awq
--dataset AI-ModelScope/alpaca-gpt4-data-zh
--output_dir Qwen2.5-7B-Instruct-AWQเฟรมเวิร์กนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต Apache (เวอร์ชัน 2.0) สำหรับรุ่นและชุดข้อมูลโปรดดูหน้าทรัพยากรดั้งเดิมและทำตามใบอนุญาตที่เกี่ยวข้อง
@misc { zhao2024swiftascalablelightweightinfrastructure ,
title = { SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning } ,
author = { Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen } ,
year = { 2024 } ,
eprint = { 2408.05517 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.05517 } ,
}

